
推荐本站淘宝优惠价购买喜欢的宝贝:

Host Tuning
概述
适当的主机调整可以带来高达 100 倍的性能提升。
原因如下:
TCP Buffer Sizing TCP 缓冲区大小
TCP 使用所谓的“拥塞窗口”(CWND)来确定一次可以发送多少个数据包。拥塞窗口大小越大,吞吐量越高。 TCP的“慢启动”和“拥塞避免”算法决定了拥塞窗口的大小。最大拥塞窗口与内核为每个套接字分配的缓冲区空间量有关。对于每个套接字,缓冲区大小都有一个默认值,程序可以在打开套接字之前使用系统库调用来更改该值。还有一个内核强制的最大缓冲区大小。套接字的发送端和接收端的缓冲区大小都可以调整。
为了获得最大的吞吐量,使用与您使用的链路最佳匹配的 TCP 发送和接收套接字缓冲区大小至关重要。如果缓冲区太小,TCP 拥塞窗口将永远无法完全打开。如果接收方缓冲区太大,TCP 流量控制将被打破,发送方可能会超过接收方的处理能力,导致 TCP 窗口关闭。这种情况通常在发送方主机快于接收方主机时发生。发送方过大的窗口通常不会成为问题,前提是您有足够的内存;请注意,每个 TCP 套接字都有可能请求这么多内存,即使对于短连接也是如此,这容易耗尽系统资源。
最佳缓冲区大小是链路带宽*延迟乘积的两倍(另请参阅有用的 BDP 计算器TCP Throughput Calculator - Tools - SWITCHlan - SWITCH):
buffer size = 2 * bandwidth * delay
即: 缓冲区大小 = 2 * 带宽 * 延迟
可以使用 ping 程序来获取延迟。确定端到端容量(路径中最慢一跳的带宽)比较棘手,并且可能需要您四处询问以找出路径中各个网络的容量。由于 ping 给出了往返时间 (RTT),因此可以使用此公式代替上一个公式:
buffer size = bandwidth * RTT
即: 缓冲区大小 = 带宽 * RTT
例如,如果您的 ping 时间为 50 毫秒,并且端到端网络全部由 1G 或 10G 以太网组成,则 TCP 缓冲区应为:
05 sec * (1 Gbit / 8 bits) = 6.25 MBytes.
在历史上,为了实现完整的带宽利用,用户需要指定网络路径的缓冲区大小,应用程序员需要使用BSD中的setsockopt()调用的SO_SNDBUF和SO_RCVBUF选项来设置发送方和接收方的缓冲区大小。幸运的是,Linux、FreeBSD、Windows和Mac OSX现在都支持TCP自动调整,因此您不再需要担心设置默认的缓冲区大小。
TCP自动调整
从Linux 2.6(于2005年发布)、Mac OSX 10.5、Windows Vista和FreeBSD 7.0开始,发送方和接收方的自动调节功能就可用了,不再需要手动设置每个路径的TCP发送和接收缓冲区。然而,对于许多高速网络路径来说,最大缓冲区大小仍然太小,必须按照每个操作系统的页面描述进行增加。
TCP 自动调整最大值
调整 Linux 的默认最大 TCP 缓冲区大小可以使自动调优算法有能力根据长路径上的可用带宽来调整发送和接收窗口。每个操作系统对此设置的反应不同,请查阅特定操作系统的资源以获取建议。
下图说明了将最大 TCP 缓冲区大小从 32MB 调整为 64MB 对两个 Linux 服务器的影响,它们之间经过一个往返时间为 75ms 的路径。调整后的数值导致吞吐量提高了近2倍。

ESnet建议针对这个值使用合理的默认设置,通常在32MB到128MB之间。假设没有任何网络丢包,对于在100ms路径上的10Gbps单流量,将需要一个120MB的缓冲区,。希望实现更快速度或更长距离的主机将需要更多的缓冲区。打算使用并行流的用户应该使用较少的缓冲区以避免内存耗尽。
ESnet 建议该值采用合理的默认值,通常在 32MB 到 128MB 之间。预计 10Gbps、单流、跨越 100 毫秒的路径将需要 120MB 缓冲区,避免任何网络损失。期望更快的速度或更远的距离的主机将需要更多。那些打算使用并行流的人应该减少使用以避免内存耗尽。
TCP 拥塞避免算法
多年来,TCP reno 拥塞避免算法一直是所有 TCP 实现中的默认算法。然而,随着网络变得越来越快,很明显 Reno 无法很好地适应高带宽延迟产品网络。为了解决这个问题,开发了许多新的拥塞避免算法,包括 CUBIC、HTCP 和 BBR。大多数Linux发行版默认使用cubic,它成为2006年发布的内核2.6.19中的默认值。更多详细信息可以在以下位置找到:http://en.wikipedia.org/wiki/TCP_congestion_avoidance_algorithm
Linux调优
本节内容包含了针对连接速度为1Gbps或更高的数据传输主机的Linux优化的快速参考指南。请注意,这里描述的大多数调优设置实际上会降低连接速度低于1Gbps(例如大多数家庭用户)的主机的性能。
请注意,本节的设置并不试图通过单个流实现完全的10G速率。这些设置假设您正在使用支持并行流的工具,或者同时进行多个数据传输,并且希望在这些流之间进行公平分享。因此,最大值比支持单个流所需的值少2到4倍。例如,一个在100ms网络上的10Gbps流需要120MB的缓冲(参见BDP计算器)。大多数数据传输应用程序(如GridFTP)将使用2-8个流来高效地进行传输,并防止拥塞引起的数据包丢失。将您的支持10Gbps的主机的最大缓冲设置为每个套接字占用32M-64M,可以确保并行流正常工作,并且不会消耗大部分系统资源。
如果您尝试优化单个流程,请参阅测试/测量主机页面的调整建议(Test/Measurement Host Tuning)。
常规步骤
要检查系统正在使用的设置,请使用"sysctl name"(例如:“sysctl net.ipv4.tcp_rmem”)。要更改设置,请使用"sysctl -w"。要使设置永久生效,请将设置添加到"sysctl.conf"文件中。
TCP 调优
与大多数现代操作系统一样,Linux 现在在自动调整 TCP 缓冲区方面做得很好,但默认的最大 Linux TCP 缓冲区大小仍然太小。以下是针对不同类型主机的一些 sysctl.conf 配置示例。
对于一个配备10G网卡、针对最高100ms往返时延的网络路径进行优化,并以对单个流和并行流工具友好的方式进行设置的主机,请将以下代码添加到/etc/sysctl.conf文件中:
# allow testing with buffers up to 64MB net.core.rmem_max = 67108864 net.core.wmem_max = 67108864 # increase Linux autotuning TCP buffer limit to 32MB net.ipv4.tcp_rmem = 4096 87380 33554432 net.ipv4.tcp_wmem = 4096 65536 33554432 # recommended for hosts with jumbo frames enabled net.ipv4.tcp_mtu_probing=1 # recommended to use a 'fair queueing' qdisc (either fq or fq_codel) net.core.default_qdisc = fq_codel
请注意,自2017年起,fq_codel成为默认选项,适用于4.12内核及更高版本。fq和fq_codel都表现良好,并支持速率控制。
另请注意,我们不再推荐将拥塞控制设置为htcp。在较新的内核版本中,htcp似乎不再比默认的cubic设置更有优势。
我们还强烈建议降低最大流量以避免可能导致交换机和接收主机缓冲区溢出的数据包突发。
例如,对于一个10G主机,请在启动脚本中添加以下代码:
/sbin/tc qdisc add dev ethN root fq maxrate 8gbit对于运行使用4个并行流的数据传输工具的主机,请执行以下操作:
/sbin/tc qdisc add dev ethN root fq maxrate 2gbit其中 ‘ethN’ 是您系统上以太网设备的名称。
对于具有针对高达 200 毫秒 RTT 的网络路径以及对单并行流工具的友好性进行优化的 10G NIC 的主机,或在高达 50 毫秒 RTT 的路径上优化的 40G NIC 的主机:
# allow testing with buffers up to 128MB net.core.rmem_max = 134217728 net.core.wmem_max = 134217728 # increase Linux autotuning TCP buffer limit to 64MB net.ipv4.tcp_rmem = 4096 87380 67108864 net.ipv4.tcp_wmem = 4096 65536 67108864 # recommended default congestion control is htcp net.ipv4.tcp_congestion_control=htcp # recommended for hosts with jumbo frames enabled net.ipv4.tcp_mtu_probing=1 # recommended to enable 'fair queueing' net.core.default_qdisc = fq_codel
注:您应该保持 net.tcp_mem 的设置不变,因为默认值是合适的。一些性能专家建议将 net.core.optmem_max 增加到与 net.core.rmem_max 和 net.core.wmem_max 相匹配,但我们发现这样做并没有任何区别。一些专家还建议将 net.ipv4.tcp_timestamps 和 net.ipv4.tcp_sack 设置为0,因为这样做可以减少CPU负载。对于广域网(WAN)性能,我们强烈不赞同该建议,因为我们观察到默认值为1在更多情况下起到正面的作用,并且可以有很大帮助。
Linux 支持可插入的拥塞控制算法。要获取内核(kernal 2.6.20+)中可用的拥塞控制算法的列表,请运行:
sysctl net.ipv4.tcp_available_congestion_control
cubic 通常是大多数 Linux 发行版中的默认设置,但我们发现 htcp 通常效果更好。如果您的系统上可用,您可能还想尝试 BBR。
要设置默认拥塞控制算法,请执行以下操作:
sysctl -w net.ipv4.tcp_congestion_control=htcp
如果您使用巨型帧,我们建议设置 tcp_mtu_probing = 1 以帮助避免 MTU 黑洞问题。将其设置为 2 有时会导致性能问题。
UDP 调优
如果不进行一些调整,UDP 将无法获得完整的 10Gbps(或更高)。重要因素是:
使用巨型帧:使用 9K MTU 性能将提高 4-5 倍
数据包大小:最佳性能是 MTU 大小减去数据包标头大小。例如,对于 9000 字节 MTU,对于 IPV4 使用 8972,对于 IPV6 使用 8952。
套接字缓冲区大小:对于 UDP,缓冲区大小与 TCP 不同,与 RTT 相关,但默认值仍然不够大。在大多数情况下,将套接字缓冲区设置为 4M 似乎有很大帮助
核心(core)选择:10G 的 UDP 通常受 CPU 限制,因此选择正确的核心非常重要。在 Sandy/Ivy Bridge 主板上尤其如此。
iperf、iperf3 和 nuttcp 的示例命令:
nuttcp -l8972 -T30 -u -w4m -Ru -i1 -xc4/4 remotehost iperf3 -l8972 -T30 -u -w4m -b0 -A 4,4 -c remotehost numactl -C 4 iperf -l8972 -T30 -u -w4m -b10G -c remotehost
您可能需要尝试不同的核心来找到适合您主机的最佳核心。您可以使用’mpstat -P ALL 1’命令来确定哪个核心用于处理网卡中断,然后用同一套接字尝试不同的核心。请注意,'top’命令在此方面不够可靠。
一般来说,nuttcp 似乎是 UDP 最快的。请注意,您需要 nuttcp V7.1 或更高版本才能获得“-xc”选项。
即使进行了这样的调整,您仍需要快速的核心才能达到完全的10Gbps速度。例如,一颗2.9GHz的英特尔Xeon CPU可以实现完全的10Gbps线速,但是使用一颗2.5GHz的英特尔Xeon CPU,我们只能达到5.9Gbps。而使用40G的网卡,2.9GHz的CPU可以实现22Gbps的UDP传输速率。
处理器架构的设计趋向于以牺牲时钟速率为代价提供更多的聚合能力(例如更多的核心)。提高时钟速度的发展已经带来了问题,并且在某些用例中回报递减。许多新的机器提供更多的核心,在虚拟机和大量小型网络流量的处理中通常表现出色。而对于单个流量性能测试这样的用例来说,较少的核心和更高的时钟速率将会带来更好的效果。
如果您想查看使用 2 个 UDP 流(每个流位于一个单独的核心上)可以获得多少流量,您可以执行以下操作:
nuttcp -i1 -xc 2/2 -Is1 -u -Ru -l8972 -w4m -p 5500 remotehost & \ nuttcp -i1 -xc 3/3 -Is2 -u -Ru -l8972 -w4m -p 5501 remotehost & \
确定 CPU 限制
如果您执行了上述命令,但仍然没有获得很好的性能,可以使用’mpstat -P ALL 1’命令来确定CPU的使用情况。例如,以下是使用建议的命令行选项进行的一次nuttcp测试,结果是5.9 Gbps:
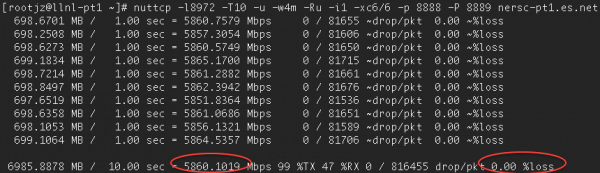
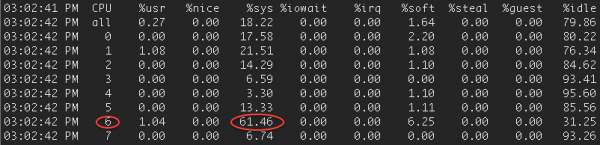
请注意,nuttcp报告在发送主机上的CPU使用率为99%。接收主机上的mpstat确认核心6未达到饱和状态:
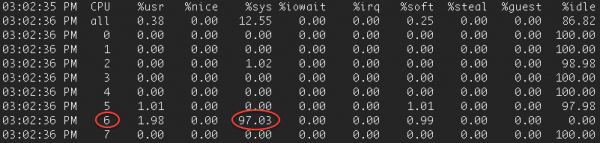
发送主机上的 mpstat 确认核心 6 已饱和:
对于这些主机,在不同的内核上运行多个 nuttcp 客户端将增加总吞吐量。
测试/测量主机调优
以下是针对Linux测试/测量主机(如运行iperf、iperf3或nuttcp等工具的perfSONAR主机)的调优设置快速参考指南。请注意,我们假设测量工具正在尝试使用perfSONAR pscheduler工具执行串行单流TCP测试。这意味着我们增加了基本的TCP套接字大小以支持较大的内存分配,并且与GridFTP等工具相比,并行流的使用不太常见。要确定适当的套接字大小,您可以使用BDP计算器进行计算。
为支持10Gbps速度,在100ms的路径上,至少需要120MB的缓冲区可用。您可能需要根据要测试的路径的延迟调整这些值。配置为使用巨帧的主机还需要更多的缓冲区空间。
常规设置
# increase TCP max buffer size setable using setsockopt() # allow testing with 256MB buffers net.core.rmem_max = 268435456 net.core.wmem_max = 268435456 # increase Linux autotuning TCP buffer limits # min, default, and max number of bytes to use # allow auto-tuning up to 128MB buffers net.ipv4.tcp_rmem = 4096 87380 134217728 net.ipv4.tcp_wmem = 4096 65536 134217728 # don't cache ssthresh from previous connection net.ipv4.tcp_no_metrics_save = 1 # If you are using Jumbo Frames, also set this net.ipv4.tcp_mtu_probing = 1 # recommended to enable 'fair queueing' net.core.default_qdisc = fq_codel
针对具有专为200ms往返时延(RTT)以下网络路径优化的10G NIC的主机,或者具有专为50ms RTT以下网络路径优化的40G NIC的主机,请使用以下值替代上述设置:
# increase TCP max buffer size setable using setsockopt() net.core.rmem_max = 536870912 net.core.wmem_max = 536870912 # increase Linux autotuning TCP buffer limit net.ipv4.tcp_rmem = 4096 87380 268435456 net.ipv4.tcp_wmem = 4096 65536 268435456
我们还强烈建议降低最大流量速率,以避免可能导致交换机和接收主机缓冲区溢出的分组突发。
例如,对于具有 10G NIC 或更快的主机,请将以下内容添加到引导脚本中:
/sbin/tc qdisc add dev ethN root fq maxrate 8gbit
40G/100G网络调优
对于具有40G/100G以太网NIC的主机,您还需要调整一些额外的配置以最大化吞吐量。
最重要的配置项包括:
将CPU governor设置为“performance”模式。
将TCP缓冲区大小设置为最大值(2GB)。
确保为IRQ和用户进程使用正确的核心。
在BIOS中禁用同时多线程(SMT)(也称为超线程)。我们发现SMT会导致非常不一致的结果,特别是在基于AMD的主机上。
确保启用了公平队列(fq或fq-codel),并为您的环境设置了良好的调度速率。
大多数较新版本的Linux将net.core.default_qdisc设置为fq_codel,这似乎工作正常。一些较旧版本的默认设置为pfifo_fast,并且不支持fq_codel。这些应该改为fq。NIC调整:将环形缓冲区大小增加到最大值(8192),并确认中断合并打开。
/usr/sbin/ethtool -G ethN rx 8192 tx 8192
/usr/sbin/ethtool -C ethN adaptive-rx on adaptive-tx on如果您的硬件支持,启用IOMMU。
对于现代Linux操作系统(5.x内核的系统),不需要进行其他调优。
有关旧系统上 100G 调整的更多详细信息,请参阅 2016 年 9 月的此演示。
CPU 时钟速率对于 40G/100G 流非常重要,如果您关心单个流的吞吐量,则更高的 CPU 时钟速率很重要。一般来说,您需要至少 3GHz 的 CPU 时钟速率才能实现每流 30Gbps。
对于40G/100G网络流量,CPU时钟速率非常重要。如果您关心单个流量的吞吐量,较高的CPU时钟速率非常重要。一般来说,您需要至少3GHz的CPU时钟速率才能实现每个流量30Gbps的速度。
在ESnet的100G perfSONAR节点上,我们通常看到约30Gbps的单个流量,并且可以通过使用8个流和iperf2以及iperf3的新线程版本轻松达到95Gbps以上。合理的调度可以确保各个流不会互相干扰。
有关DTN文件系统调优的信息,请参阅DTN调优文档。
中断绑定(Interrupt Binding )
为了充分最大化 NUMA 架构系统(例如:Intel Sandy/Ivy Bridge 主板)上的单流性能(TCP 和 UDP),您需要注意正在使用哪个 CPU 插槽和核心。
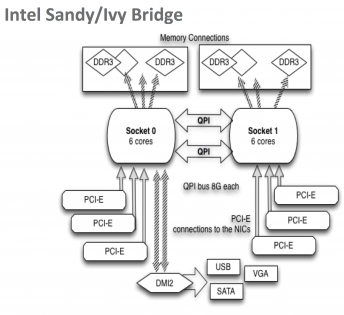
如上图表所示,NIC的PCI插槽只直接连接到两个CPU插槽中的一个。如果中断或应用程序使用错误的插槽,将会产生较大的性能损失,因为这将导致所有数据经过QPI总线进行交互。在40G/100G的PCI gen-3主机上,如果使用错误的CPU插槽,TCP和UDP性能可能会降低最多2倍。因此,确保NIC的中断和应用程序都使用正确的CPU插槽非常重要。
要指定哪个核心处理网卡中断,您需要禁用 irqbalance,然后将中断绑定到特定的 CPU 插槽。为此,请在启动时运行供应商提供的 IRQ 脚本。
Mellanox: /usr/sbin/set_irq_affinity_bynode.sh socket ethN
Chelsio: /sbin/t4_perftune.sh
其中“ethN”是您的以太网设备的名称。要找出要传递给 set_irq_affinity_bynode.sh 的套接字,可以使用以下命令:
cat /sys/class/net/ethN/device/numa_node
要确定用于该 NUMA 节点的最佳核心,请使用以下命令:
numactl --hardware
请注意,'numactl --hardware’所报告的“节点间距离”越大,使用最佳NUMA节点就越重要。
在 Linux 上,您可以使用 sched_setaffinity() 系统调用或 numactl 命令行工具将进程绑定到核心。
网络测试工具 iperf3 和 nuttcp 都允许您从命令行选择核心。对于 iperf3,您可以使用“-A”标志,对于 nuttcp,您可以使用“-xc”标志来执行此操作。
对于其他程序,您可以使用 numactl。例如:
numactl -N socketID program_name
如果您使用 perfSONAR 4.x 并使用 pscheduler 启动这些工具,则无需担心这一点,因为 pScheduler 会自动确定要使用哪个 CPU 插槽。
要测试进行 IRQ 绑定对 CPU 的影响,请使用 mpstat。例如:
mpstat -P ALL 1
“mpstat -P ALL 1” 是一个使用mpstat命令的命令行参数,用于显示系统中每个CPU核心的实时性能统计信息。具体而言,它将以每秒一次的频率输出每个CPU核心的使用率、空闲率、系统时间和用户时间等信息。
该命令的输出可帮助您监测系统中每个CPU核心的负载情况,以便更好地了解每个核心的性能状态。通过定期观察输出,您可以获得关于各个核心的工作负载、处理能力和效率的信息,有助于调优和优化系统性能。
Packet Pacing
数据包调节(Packet Pacing)
当从一个速度更快的主机发送数据到一个速度较慢的主机时,很容易超过接收方的处理能力,导致数据包丢失和TCP退避。类似的问题也会出现在一个10G主机向低于10G的虚拟电路发送数据,或者一个40G主机向10G主机发送数据,或者一个CPU速度较快的40G/100G主机向CPU速度较慢的40G/100G主机发送数据。当使用支持并行流的工具(如GridFTP)时,这些问题会更加显著。在一些往返时间较长的路径(50-80毫秒RTT)上,启用数据包调节(packet pacing)后,TCP性能可以提升2-4倍。
基于公平队列(Fair Queuing,FQ)的数据包调节是解决这个问题的一种非常有效的方法。
需要谨慎考虑数据包调节技术,因为对主机上的所有流量都会产生影响。下面的信息仅适用于对系统要求和流量模式非常了解的情况。
使用FQ(公平队列)调度器的数据包调节
从Linux内核3.11或更高版本开始(在CentOS 7.2、Fedora 20、Debian 8和Ubuntu 13.10中可用),引入了一个新的“公平队列”调度器,其中包含能更好地从快速主机中调节数据包的代码。有关更多详细信息,请参阅https://lwn.net/Articles/564978/。
随后发布了fq_codel,它在fq的基础上结合了公平队列和基于延迟的队列管理的概念,但不支持数据包调节。自2017年起,fq_codel成为默认的排队策略,从4.12版内核开始。
然而,对于高吞吐量TCP,我们建议使用fq而不是fq_codel,因为fq支持数据包调节,并且在内核版本低于4.20时,如果您想尝试BBR拥塞控制算法,也需要使用fq。
要确认您的主机已配置为使用 fq:
sysctl -a | grep qdisc
如果不是,请将其添加到 /etc/sysctl.conf 中:
net.core.default_qdisc = fq
启用数据包调节的方法如下:
tc qdisc add dev $ETH root fq maxrate Ngbit
例如,对于运行GridFTP的10G数据传输节点(DTN),默认使用4个并行流,我们建议将FQ设置如下:
tc qdisc add dev $ETH root fq maxrate 2gbit
其他有用的tc命令包括 'show' 和 'delete'。例如:
tc qdisc show dev $ETH
tc qdisc del dev $ETH root
对于向大多数10G主机发送数据的100G数据传输节点(DTN),同样建议设置2gbit的数据包调节速率。
您还可以使用 'setsockopt' 系统调用和 SO_MAX_PACING_RATE 选项,将基于FQ的数据包调节添加到您的应用程序中。不过,这仅在主机配置为使用fq作为qdisc时才有效。iperf3工具使用 --fq-rate 选项来实现此功能(v3.1.5及更高版本)。
本文链接:http://hqyman.cn/post/6856.html 非本站原创文章欢迎转载,原创文章需保留本站地址!
休息一下~~