
08
2023
07
08
2023
07
08
2023
07
python爬取福利网站图片完整代码
import requests,bs4,re,os,threading
class MeiNvTu:
def __init__(self):
self.url_main='https://网址/pw/'
self.url=f'{self.url_main}thread.php?fid='
def getPageMax(self,typeID=14):
try:
res = requests.get(f'{self.url}{typeID}')
res.encoding = 'utf-8'
soup = bs4.BeautifulSoup(res.text, 'lxml')
pageNum = soup.select('#main > div > span.fl > div.pages.cc > span')
pageNum = int(re.search('/(.*?)Go', str(pageNum)).group(1))
return pageNum
except:
return 0
def getTitleList(self,typeID=14,page=1):
'''
爬取栏目里某一页的列表,网络错误返回False
:param typeID:
:param page:
:return:
'''
try:
res=requests.get(f'{self.url}{typeID}&page={page}')
res.encoding= 'utf-8'
soup=bs4.BeautifulSoup(res.text,'lxml')
listTitle=soup.select('tr > td > h3')
lists=[]
for item in listTitle:
if 'html_data' in item.a['href'] :
d={}
d['href']=self.url_main+item.a['href']
d['title']=item.a.text
lists.append(d)
return lists
except:
return False
def downImg(self,url,path):
'''
下载一整个页面的图片
:param url:
:param path:
:return:
'''
global pool_sema
res = requests.get(url)
res.encoding = 'utf-8'
soup = bs4.BeautifulSoup(res.text, 'lxml')
imgs=soup.select('#read_tpc > img')
lists=[]
try:
for i,item in enumerate(imgs):
imgUrl=re.search("window.open\('(.*?)'\);", str(item['onclick'])).group(1)
imgData=requests.get(imgUrl).content
typ=imgUrl.split('.')[-1]
with open(f'{path}{i}.{typ}','wb')as f:
f.write(imgData)
except:
print('\033[31m[下载失败!网络异常] ' + path)
pool_sema.release()
return
#将下载好的情况记录下来,下次可以跳过
textpath=''
for item in path.split('\\')[0:3]:
textpath=textpath+item+'\\'
mutex.acquire()
try:
with open(textpath+'log.txt','a')as f:
f.writelines(path.split('\\')[3]+'\n\r')
except:
pass
mutex.release()
# 完成后线程池记录-1
print('\033[31m[完成下载] '+path)
pool_sema.release()
def get_typeTitle(self,id):
'''
返回类型的标题
:param id:
:return:
'''
if id==14:
return '唯美写真'
if id==15:
return '网友马赛克'
if id==16:
return '露出马赛克'
if id==49:
return '街拍马赛克'
if id==21:
return '丝袜美腿'
if id==114:
return '欧美马赛克'
def downloadthe(self,title,path):
'''
判断是否已经下载过,下载过返回True,没下载过返回False
:param title:
:param path:
:return:
'''
try:
with open(path+'log.txt', 'r')as f:
text = f.read()
if title in text:
return True
else:
return False
except:
return False
def get_Page_History(self,path):
'''
读取上一次结束 的页码
:param path:
:return:
'''
try:
with open(path+'pagelog.ini','r')as f:
return int(f.read())
except:
return 0
if __name__ == '__main__':
# 限制线程数量
pool_sema = threading.BoundedSemaphore(70)
# 创建互斥体
mutex = threading.Lock()
#创建爬取对象
mnt=MeiNvTu()
#栏目id
typeID=21
#获得最大页数
page_max=mnt.getPageMax(typeID)
if page_max==0:
print('\033[31m网络错误!,总页数为0')
else:
path_main= f"D:\\爬取的网站图片\\{mnt.get_typeTitle(typeID)}\\"
if os.path.isdir(path_main) != True:
os.makedirs(path_main, mode=0o777)
#爬取某页的列表
page_History=mnt.get_Page_History(path_main)
for i in range(page_max):
#跳过之前下载过的页码
if i+1<page_History:
print(f'\033[37m跳过页码:{i + 1}')
continue
#记录下来页码
with open(path_main+'pagelog.ini','w')as f:
f.write(str(i+1))
print(f'\033[37m当前页码:{i+1}')
titleList = mnt.getTitleList(typeID, i + 1)
if titleList==False:
print('\033[31m网络错误!,列表获取失败!')
break
for item in titleList:
title=item['title'].replace(' ','').replace(':','').replace('!','').replace('?','').replace('*','').replace('"','')
path = path_main + title + "\\"
#判断是否有这个目录,没有的话就建立
if os.path.isdir(path) != True:
os.makedirs(path, mode=0o777)
if mnt.downloadthe(title,path_main)==False:
# 线程池记录+1
pool_sema.acquire()
print('\033[37m[开始下载] '+path)
# 爬取某个标题中的所有图片
t=threading.Thread(target=mnt.downImg,args=(item['href'], path))
t.setDaemon(True)
t.start()
else:
print('\033[35m发现下载过的:',title,' 已经智能跳过!')
作者:hqy | 分类:技术文章 | 浏览:2228 | 评论:0
08
2023
07
08
2023
07
08
2023
07
07
2023
07
06
2023
07
06
2023
07
06
2023
07
大型企业AD架构规划
1、项目介绍:
公司是外资企业,在国外有多个分公司,每个公司的都有自己独立的AD域,导致AD帐号去做集团化的验证登录、邮件管理,或分公司出差去其它国家的公司,用AD登录和使用都不是统一的,所以大大提出集团化AD域架构,统一使用唯一集团工号去登录和使用系统和邮件。
2、AD域架构选型
考虑主要从父子域和单域多站点,后再网上搜索一些文档和测试,最终选的单域多站点(其中也有一个原因现所有公司都有VPN专线互联)
作者:hqy | 分类:Windows&windows server | 浏览:759 | 评论:0
06
2023
07
06
2023
07
06
2023
07
06
2023
07
06
2023
07
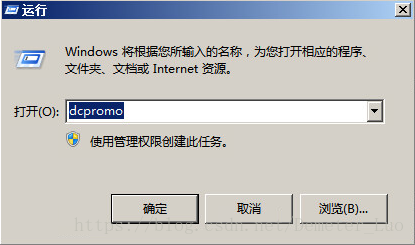
项目实例一:新建的DNS上创建AD集成域的条件转发Forward Zone,验证直接指向搭建的DNS的终端是否能够成功加域和身份验证
步骤一、搭建AD域控
1.创建虚拟机Windows Server 2008 R2
2.在开始菜单栏选择运行命令提示符,键入dcpromo
作者:hqy | 分类:Network | 浏览:930 | 评论:0
06
2023
07
windows客户端加入域时报错: DNS名称不存在
windows客户端加入域时报错: DNS名称不存在,具体报错如下:
--------------------
注意: 此信息主要供网络管理员参考。如果您不是网络管理员,请通知网络管理员您收到了此信息,该信息已记录在文件 C:\Windows\debug\dcdiag.txt 中。
查询 DNS 以获取用于查找域“throld.com”的 Active Directory 域控制器(AD DC)的服务位置(SRV)资源记录时出现下列错误:
作者:hqy | 分类:Windows&windows server | 浏览:1475 | 评论:0
06
2023
07
理解计算机的主DNS后缀选项
原本在这一节要讲解DNS的安装,但我发现其实在此之前,还需要向大家说明几个基本的概念,首先说到的是DNS后缀。
作者:hqy | 分类:Network | 浏览:930 | 评论:0
06
2023
07
DNS查询工具之NSLOOKUP的使用
上一节里我们讨论了有关DIG工具的用法,本节将对windows下nslookup工具的一些主要命令进行描述。
作者:hqy | 分类:Network | 浏览:886 | 评论:0
06
2023
07
DNS 客户端查询过程
DNS客户端的注册信息在DNS服务器中是以记录的方式体现出来的,那么客户端就可以用一些方式进行查询各类记录。相对应的,服务器会对这些查询进行响应,我们称之为解析,至于DNS内部的工作机制,我们不得而知,但可以通过一些命令和方法间接地了解DNS查询过程。为了更好的描述这个问题,我做了一张简单的TOPO图,其中DNS1为DNS服务器,主机XP3是一个DNS客户端。拓扑图如下:
作者:hqy | 分类:Network | 浏览:742 | 评论:0
06
2023
07
- 本站推荐小工具
-
- 控制面板
- 随心随性
-
沧海月明珠有泪,蓝田日暖玉生烟。
- 网站分类
- 搜索
- 最新留言
-
- I'am sorry about that. Now I change it by referencing.
- Why are you still mirroring the site with your own adsense code?We don't want to block our friends in China from accessing VMpatch as a country.Remove our site directly from your site. Otherwise, we will block China completely.
- 已经发送了哟。
- 可以说具体一些?按文章赞助?
- 怎么赞助? 赞助多少?
- 按文章赞助后,会回复。
- 怎么联系 下载链接在哪里?
- 估计是地址失效了吧。。。
- 博主,为啥我用这个代码最后面加上我的uid,生成二维码,支付宝扫码出来没反应呢https://ds.alipay.com/?appId=0999988&actionType=toAccount&goBack=NO&amount=&userId=”+a+“”&memo=
- 本站和本人不卖啊,提供互联网搜集的链接自行下载,不保任何。
- 文章归档
-
- 2025年5月 (396)
- 2025年4月 (1023)
- 2025年3月 (628)
- 2025年2月 (407)
- 2025年1月 (119)
- 2024年12月 (125)
- 2024年11月 (390)
- 2024年10月 (175)
- 2024年9月 (200)
- 2024年8月 (537)
- 2024年7月 (437)
- 2024年6月 (461)
- 2024年5月 (460)
- 2024年4月 (324)
- 2024年3月 (334)
- 2024年2月 (288)
- 2024年1月 (202)
- 2023年12月 (131)
- 2023年11月 (140)
- 2023年10月 (71)
- 2023年9月 (50)
- 2023年8月 (31)
- 2023年7月 (82)
- 2023年6月 (19)
- 2023年5月 (192)
- 2023年4月 (221)
- 2023年3月 (84)
- 2023年2月 (89)
- 2023年1月 (207)
- 2022年12月 (216)
- 2022年11月 (343)
- 2022年10月 (62)
- 2022年9月 (73)
- 2022年8月 (158)
- 2022年7月 (119)
- 2022年6月 (168)
- 2022年5月 (33)
- 2022年4月 (53)
- 2022年3月 (60)
- 2022年2月 (7)
- 2022年1月 (31)
- 2021年12月 (35)
- 2021年11月 (27)
- 2021年10月 (74)
- 2021年9月 (61)
- 2021年8月 (29)
- 2021年7月 (17)
- 2021年6月 (55)
- 2021年5月 (57)
- 2021年4月 (51)
- 2021年3月 (16)
- 2021年2月 (1)
- 2021年1月 (27)
- 2020年12月 (60)
- 2020年11月 (28)
- 2020年10月 (8)
- 2020年9月 (1)
- 2020年8月 (32)
- 2020年7月 (50)
- 2020年6月 (86)
- 2020年5月 (87)
- 2020年4月 (27)
- 2020年3月 (26)
- 2020年2月 (9)
- 2020年1月 (35)
- 2019年12月 (37)
- 2019年11月 (99)
- 2019年10月 (30)
- 2019年9月 (24)
- 2019年8月 (17)
- 2019年7月 (92)
- 2019年6月 (21)
- 2019年5月 (120)
- 2019年4月 (156)
- 2019年3月 (163)
- 2019年2月 (2)
- 2019年1月 (272)
- 网站收藏
- 友情链接