
08
2023
07
08
2023
07
域控服务器热备方案
域控制器热备,看到HYPER-V迁移的文章,用这个方法不知是否可行:环境是两台服务器加一台ISCSI存储,要建立一个域服务器,并且可以是热备的,我的想法是做一个MSCS群集,建一个虚拟2008系统,在里面建域来实现,不知是否可行,这样只需管理一个虚拟的系统就行了也实现热备,而用备份域的方法可能较麻烦(没有实施过,只是觉得)。我的结构是这样的:群集用一个域,装在2个节点的其中一个上,然后再在HYPER-V中装2008建一个域,实际用的。如果用备份域这种方式做是否会更好?没有实施过,有没有相关的资料参考一下,非常感谢!
作者:hqy | 分类:技术文章 | 浏览:836 | 评论:0
08
2023
07
搭建域控和添加本域辅域控,加入域
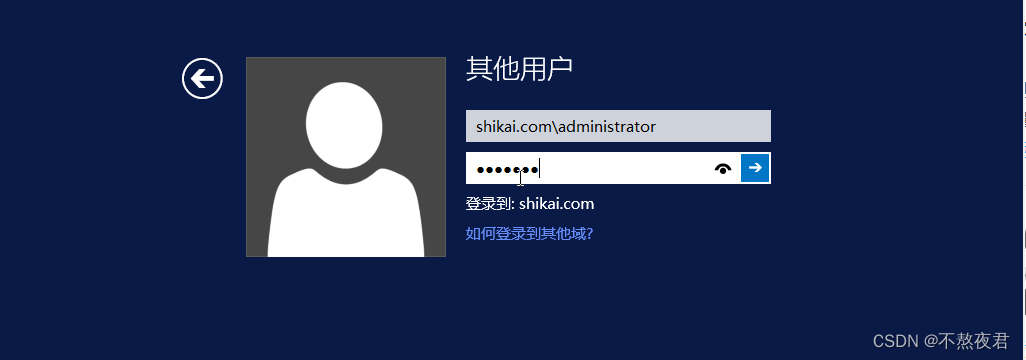
首先,我们登入我们昨天已经加入域的用户(即和之前一样,用(已加入的域名)+(用户名))登入主机(和主域控所在的主机不一样,我这里是登入已加入域的主机)
作者:hqy | 分类:技术文章 | 浏览:1047 | 评论:0
08
2023
07
08
2023
07
08
2023
07
08
2023
07
08
2023
07
08
2023
07
08
2023
07
08
2023
07
08
2023
07
08
2023
07
08
2023
07
08
2023
07
08
2023
07
08
2023
07
08
2023
07
python爬取福利网站图片完整代码
import requests,bs4,re,os,threading
class MeiNvTu:
def __init__(self):
self.url_main='https://网址/pw/'
self.url=f'{self.url_main}thread.php?fid='
def getPageMax(self,typeID=14):
try:
res = requests.get(f'{self.url}{typeID}')
res.encoding = 'utf-8'
soup = bs4.BeautifulSoup(res.text, 'lxml')
pageNum = soup.select('#main > div > span.fl > div.pages.cc > span')
pageNum = int(re.search('/(.*?)Go', str(pageNum)).group(1))
return pageNum
except:
return 0
def getTitleList(self,typeID=14,page=1):
'''
爬取栏目里某一页的列表,网络错误返回False
:param typeID:
:param page:
:return:
'''
try:
res=requests.get(f'{self.url}{typeID}&page={page}')
res.encoding= 'utf-8'
soup=bs4.BeautifulSoup(res.text,'lxml')
listTitle=soup.select('tr > td > h3')
lists=[]
for item in listTitle:
if 'html_data' in item.a['href'] :
d={}
d['href']=self.url_main+item.a['href']
d['title']=item.a.text
lists.append(d)
return lists
except:
return False
def downImg(self,url,path):
'''
下载一整个页面的图片
:param url:
:param path:
:return:
'''
global pool_sema
res = requests.get(url)
res.encoding = 'utf-8'
soup = bs4.BeautifulSoup(res.text, 'lxml')
imgs=soup.select('#read_tpc > img')
lists=[]
try:
for i,item in enumerate(imgs):
imgUrl=re.search("window.open\('(.*?)'\);", str(item['onclick'])).group(1)
imgData=requests.get(imgUrl).content
typ=imgUrl.split('.')[-1]
with open(f'{path}{i}.{typ}','wb')as f:
f.write(imgData)
except:
print('\033[31m[下载失败!网络异常] ' + path)
pool_sema.release()
return
#将下载好的情况记录下来,下次可以跳过
textpath=''
for item in path.split('\\')[0:3]:
textpath=textpath+item+'\\'
mutex.acquire()
try:
with open(textpath+'log.txt','a')as f:
f.writelines(path.split('\\')[3]+'\n\r')
except:
pass
mutex.release()
# 完成后线程池记录-1
print('\033[31m[完成下载] '+path)
pool_sema.release()
def get_typeTitle(self,id):
'''
返回类型的标题
:param id:
:return:
'''
if id==14:
return '唯美写真'
if id==15:
return '网友马赛克'
if id==16:
return '露出马赛克'
if id==49:
return '街拍马赛克'
if id==21:
return '丝袜美腿'
if id==114:
return '欧美马赛克'
def downloadthe(self,title,path):
'''
判断是否已经下载过,下载过返回True,没下载过返回False
:param title:
:param path:
:return:
'''
try:
with open(path+'log.txt', 'r')as f:
text = f.read()
if title in text:
return True
else:
return False
except:
return False
def get_Page_History(self,path):
'''
读取上一次结束 的页码
:param path:
:return:
'''
try:
with open(path+'pagelog.ini','r')as f:
return int(f.read())
except:
return 0
if __name__ == '__main__':
# 限制线程数量
pool_sema = threading.BoundedSemaphore(70)
# 创建互斥体
mutex = threading.Lock()
#创建爬取对象
mnt=MeiNvTu()
#栏目id
typeID=21
#获得最大页数
page_max=mnt.getPageMax(typeID)
if page_max==0:
print('\033[31m网络错误!,总页数为0')
else:
path_main= f"D:\\爬取的网站图片\\{mnt.get_typeTitle(typeID)}\\"
if os.path.isdir(path_main) != True:
os.makedirs(path_main, mode=0o777)
#爬取某页的列表
page_History=mnt.get_Page_History(path_main)
for i in range(page_max):
#跳过之前下载过的页码
if i+1<page_History:
print(f'\033[37m跳过页码:{i + 1}')
continue
#记录下来页码
with open(path_main+'pagelog.ini','w')as f:
f.write(str(i+1))
print(f'\033[37m当前页码:{i+1}')
titleList = mnt.getTitleList(typeID, i + 1)
if titleList==False:
print('\033[31m网络错误!,列表获取失败!')
break
for item in titleList:
title=item['title'].replace(' ','').replace(':','').replace('!','').replace('?','').replace('*','').replace('"','')
path = path_main + title + "\\"
#判断是否有这个目录,没有的话就建立
if os.path.isdir(path) != True:
os.makedirs(path, mode=0o777)
if mnt.downloadthe(title,path_main)==False:
# 线程池记录+1
pool_sema.acquire()
print('\033[37m[开始下载] '+path)
# 爬取某个标题中的所有图片
t=threading.Thread(target=mnt.downImg,args=(item['href'], path))
t.setDaemon(True)
t.start()
else:
print('\033[35m发现下载过的:',title,' 已经智能跳过!')
作者:hqy | 分类:技术文章 | 浏览:2270 | 评论:0
08
2023
07
08
2023
07
- 本站推荐小工具
-
- 控制面板
- 随心随性
-
沧海月明珠有泪,蓝田日暖玉生烟。
- 网站分类
- 搜索
- 最新留言
- 文章归档
-
- 2025年6月 (596)
- 2025年5月 (396)
- 2025年4月 (1023)
- 2025年3月 (628)
- 2025年2月 (407)
- 2025年1月 (118)
- 2024年12月 (125)
- 2024年11月 (390)
- 2024年10月 (175)
- 2024年9月 (200)
- 2024年8月 (537)
- 2024年7月 (437)
- 2024年6月 (461)
- 2024年5月 (460)
- 2024年4月 (324)
- 2024年3月 (334)
- 2024年2月 (288)
- 2024年1月 (202)
- 2023年12月 (131)
- 2023年11月 (140)
- 2023年10月 (71)
- 2023年9月 (50)
- 2023年8月 (31)
- 2023年7月 (82)
- 2023年6月 (19)
- 2023年5月 (192)
- 2023年4月 (221)
- 2023年3月 (84)
- 2023年2月 (89)
- 2023年1月 (207)
- 2022年12月 (216)
- 2022年11月 (343)
- 2022年10月 (62)
- 2022年9月 (73)
- 2022年8月 (158)
- 2022年7月 (119)
- 2022年6月 (168)
- 2022年5月 (33)
- 2022年4月 (53)
- 2022年3月 (60)
- 2022年2月 (7)
- 2022年1月 (31)
- 2021年12月 (35)
- 2021年11月 (27)
- 2021年10月 (74)
- 2021年9月 (61)
- 2021年8月 (29)
- 2021年7月 (17)
- 2021年6月 (55)
- 2021年5月 (57)
- 2021年4月 (51)
- 2021年3月 (16)
- 2021年2月 (1)
- 2021年1月 (27)
- 2020年12月 (60)
- 2020年11月 (28)
- 2020年10月 (8)
- 2020年9月 (1)
- 2020年8月 (32)
- 2020年7月 (50)
- 2020年6月 (86)
- 2020年5月 (87)
- 2020年4月 (27)
- 2020年3月 (26)
- 2020年2月 (9)
- 2020年1月 (35)
- 2019年12月 (37)
- 2019年11月 (99)
- 2019年10月 (30)
- 2019年9月 (24)
- 2019年8月 (17)
- 2019年7月 (92)
- 2019年6月 (21)
- 2019年5月 (120)
- 2019年4月 (156)
- 2019年3月 (163)
- 2019年2月 (2)
- 2019年1月 (272)
- 网站收藏
- 友情链接