
推荐点击下面图片,通过本站淘宝优惠价购买:

大数据(1) - 虚拟机集群搭建
使用工具:
1.VMware12 +,
2.CentOS-6.8 / CentOS-7 +,
3.jdk1.8
一、安装主服务器虚拟机


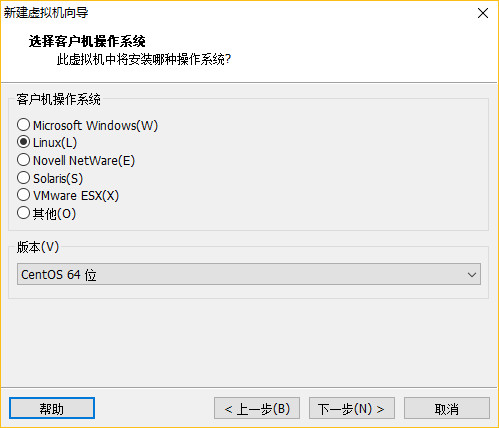


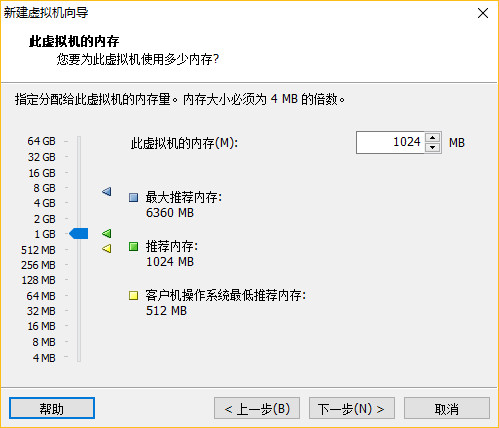
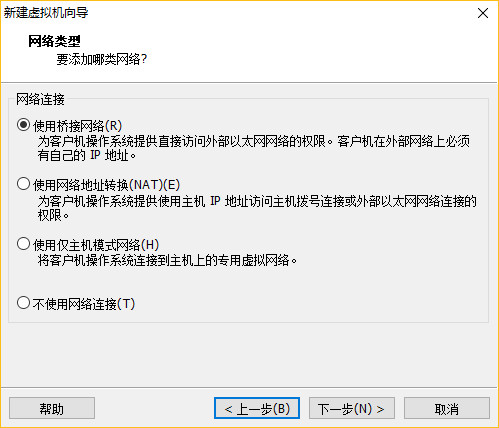
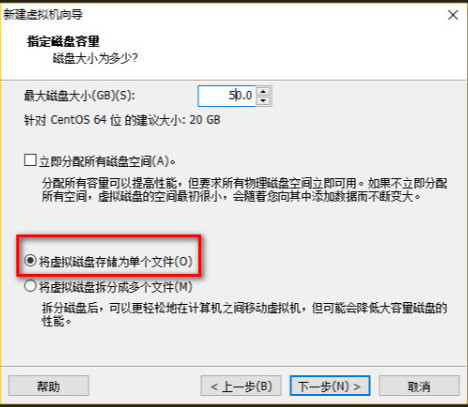
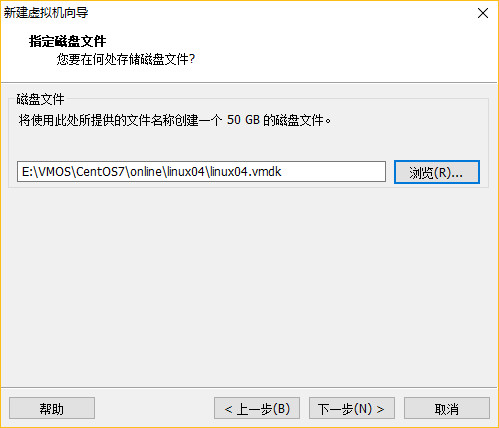
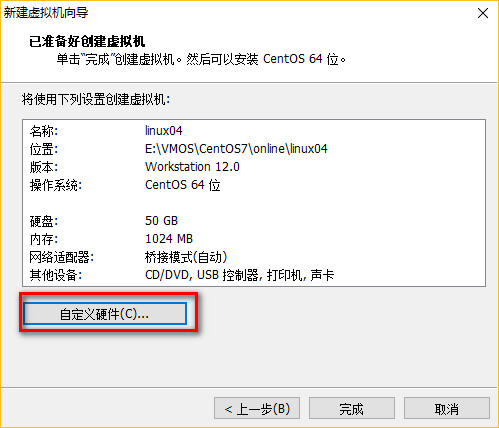
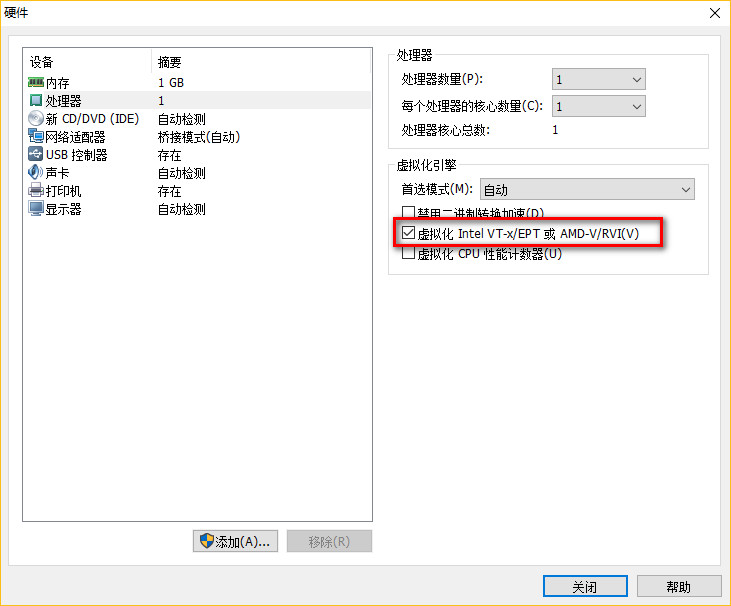
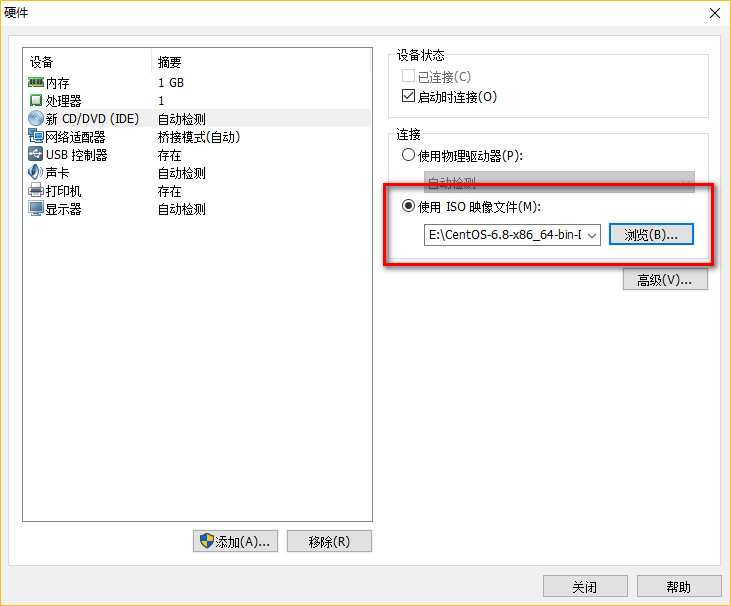
配置完成,点击启动虚拟机!
二、虚拟机网络设置
需要静态的方式配置ip,请参考链接: 设置静态IP
(1)重启网卡服务:
1 2 | CentOS6.8: # service network restartCentOS7.2: # systemctl restart network.service |
(2)CRT远程连接Linux
(3)禁用SELinux
1 2 3 4 | ** Selinux:linux安全管理工具** # vi /etc/sysconfig/selinux** 编辑改动如下: SELINUX:disable |
(4)禁用防火墙
1 2 3 4 5 6 7 8 | ** CentOS 6.8 iptables # service iptables stop # chkconfig iptables off** CentOS 7.2 # systemctl stop firewalld.service # systemctl disable firewalld.service |
(5)ping外网测试
1 | ping www.baidu.com |
三、分配权限给普通管理员
1 2 3 4 5 6 | su - rootvisudo添加:shifu(对应账号) ALL=(ALL) NOPASSWD: ALL |

四、修改ip与主机名的映射关系
1 2 3 4 5 6 | $ sudo vi /etc/hosts(对应你准备配置的ip)192.168.1.213 linux01192.168.1.214 linux02192.168.1.215 linux03 |
五、更新yum与安装samba
参考更新优化linux链接:linux软件优化安装
参考安装samba链接 :安装samba
六、安装JDK
(1)解压jdk包
1 2 3 4 5 6 7 8 | 在家目录创建两个文件夹:cd ~mkdir -p softwares/installtionsmkdir modules在windows将jdk压缩包用samba拉到linux的installtions中,解压到modules中tar -zxf jdk-8u131-linux-x64.gz -C /home/amidn/modules |
(2)配置环境变量
1 2 3 4 5 6 7 8 9 10 11 12 | vim /etc/profile在文件最底部添加:#JAVA_HOMEJAVA_HOME=/home/admin/modules/jdk1.8.0_121export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jarexport PATH=$PATH:$JAVA_HOME/bin保存后让配置生效:source /etc/profile |
(3)删除OpenJDK(CentOS 自带的JAVA环境)
1 2 3 4 5 6 | 查看相关的自带java文件:rpm -qa | grep java用无依赖的方式删除掉:sudo rpm -e --nodeps (将查询到的文件复制到这里,一个一个的删掉) |
(4)查看java版本
1 2 3 4 5 | source /etc/profilejava -version如果是你安装的版本,就完成啦 |
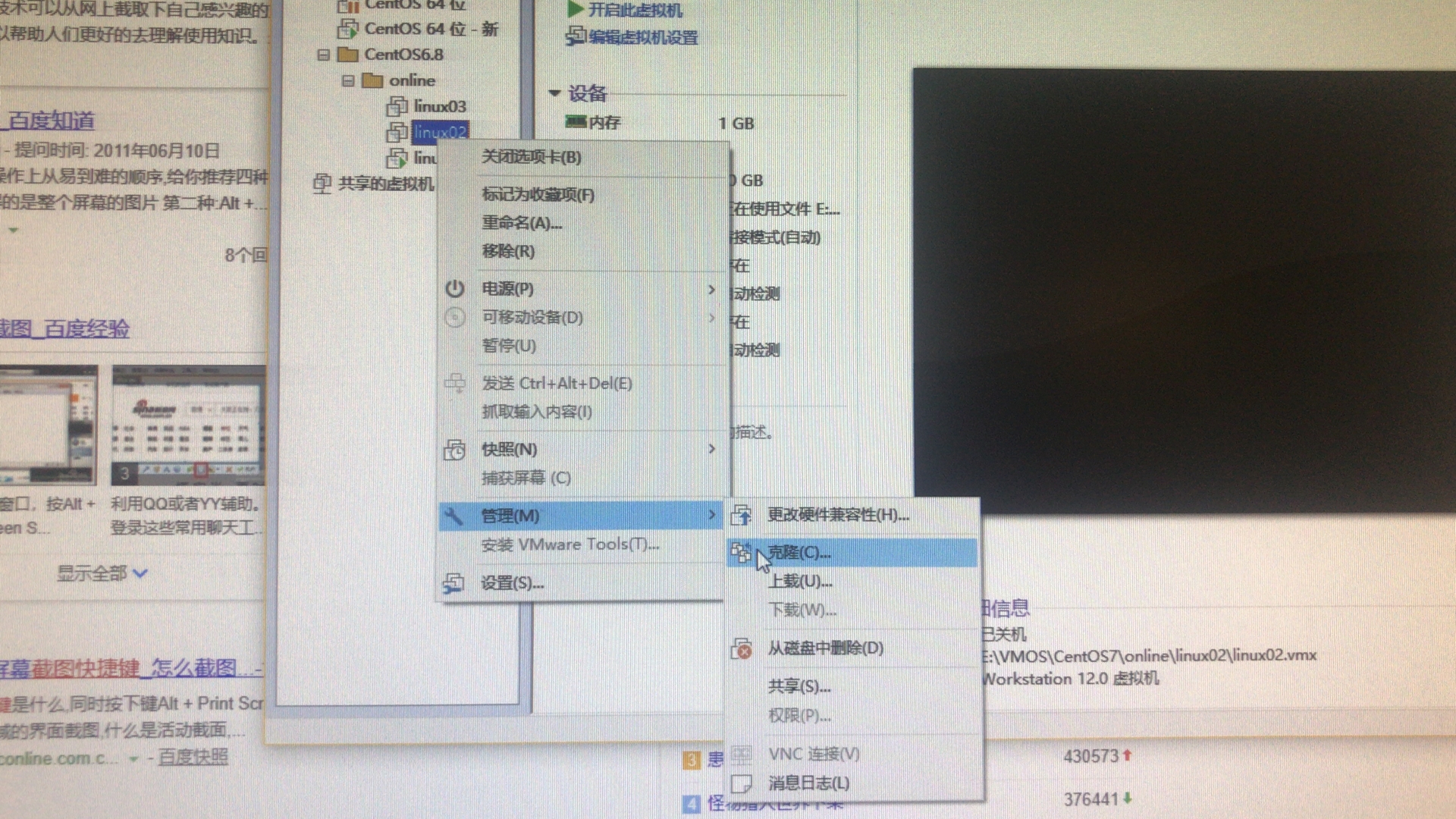
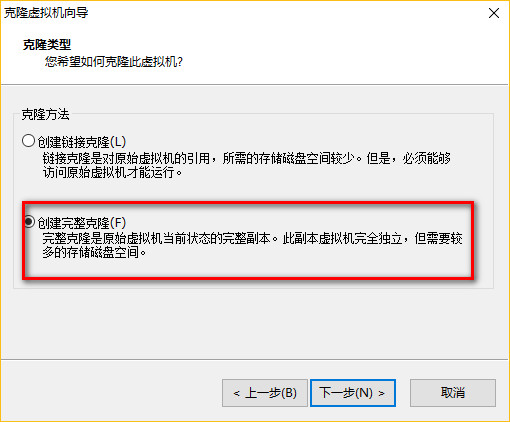
七、将linux01,克隆出linux02,linux03
(1)克隆
1 2 3 | 先关机sudo shutdown -h now |
(2)修改后两台机器的网络配置
1 2 3 4 5 6 | ** 主机名 $ sudo vi /etc/sysconfig/network** 网卡MAC地址 $ sudo vi /etc/udev/rules.d/70-persistent-net.rules** IP地址 $ sudo vi /etc/sysconfig/network-scripts/ifcfg-eth0 |
(3)使用CRT连接3台机器,测试
八、 配置SSH无秘钥访问(如下操作,需要在3台机器中分别执行)
1 2 3 4 5 6 7 8 9 10 | ** 生成密钥,猛点回车 $ ssh-keygen -t rsa** 分发公钥 $ ssh-copy-id linux01; ssh-copy-id linux02; ssh-copy-id linux03;** ssh访问测试 ssh linux01 ssh linux02 ssh linux03 |
九、关闭后两台机器的界面(linux02,linux03)
1 2 3 4 | CentOS6: $ sudo vi /etc/inittabCentOS7: $ sudo systemctl set-default multi-user.target |
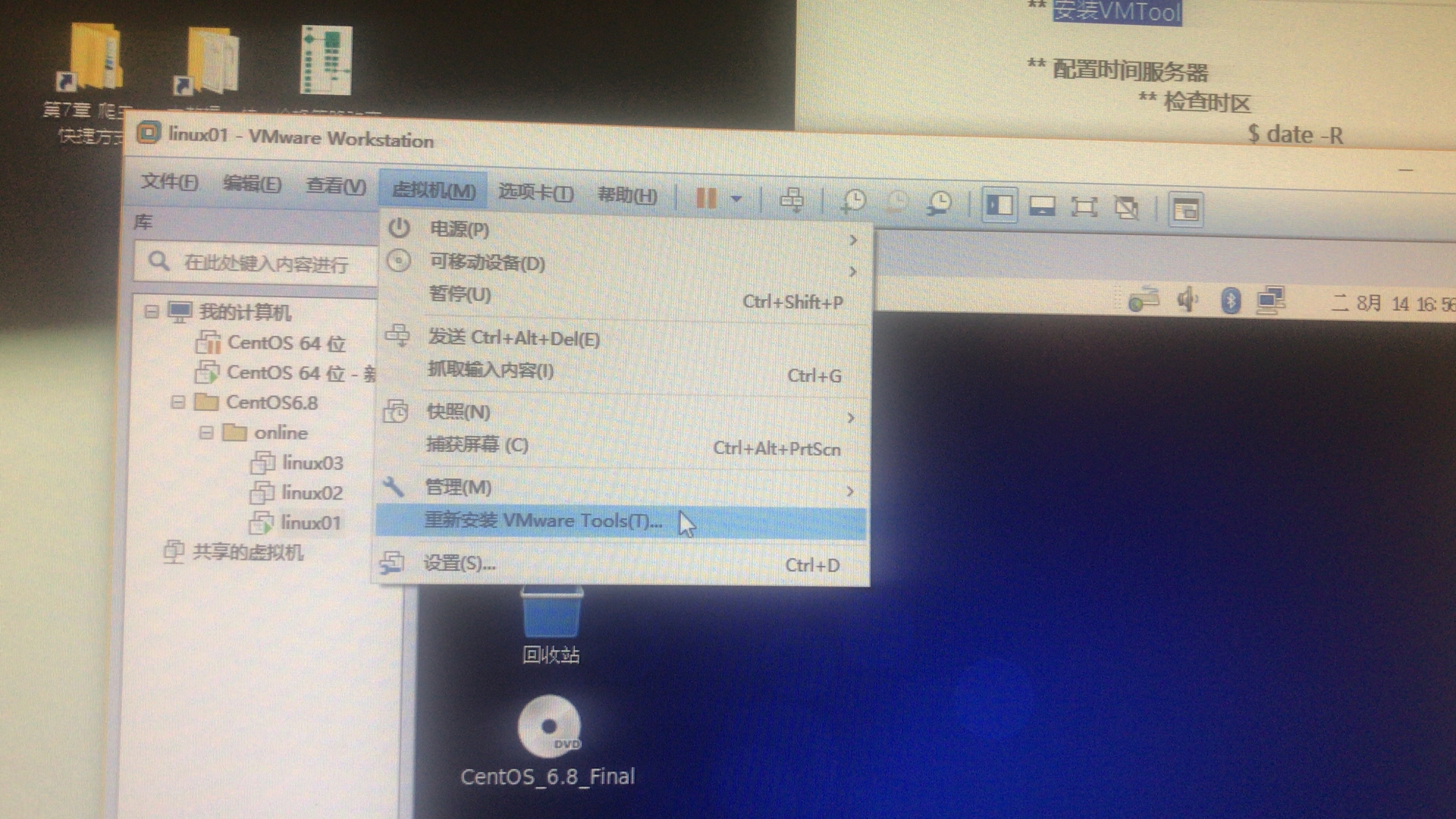
十、安装VMTool(只安装在linux01)

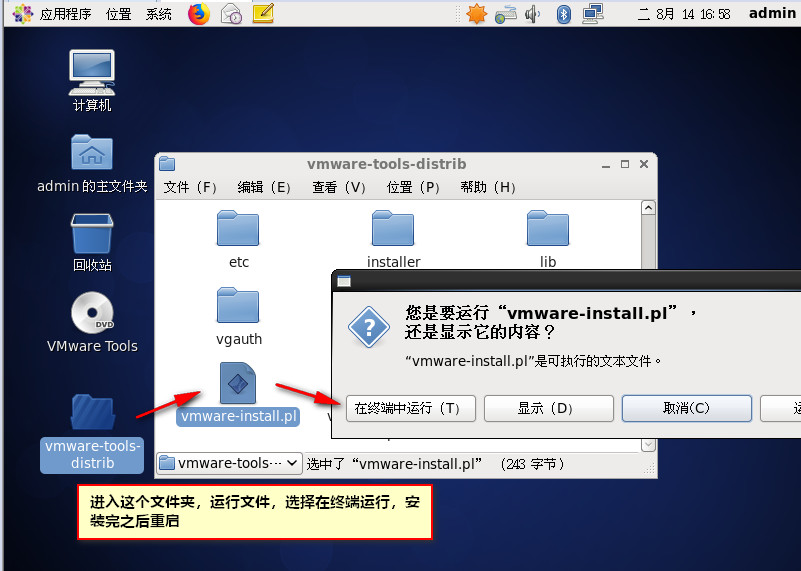
十一、配置时间服务器
(1) 检查时区
1 2 3 4 | $ date -R ** 如果时区不是+0800东八区区时的话,需要手动纠正 $ sudo rm -rf /etc/localtime $ sudo ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime |
(2)检查软件包
1 2 3 4 | 如果ntp工具不存在,则需要使用yum安装 $ sudo rpm -qa | grep ntp如果不存在则安装: $ sudo yum -y install ntp |
(3)先以网络时间为标准,纠正集群的时间服务器的时间
1 | $ sudo ntpdate pool.ntp.org |
(4)修改ntp配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | $ sudo vi /etc/ntp.conf 修改为如下: #允许192.168.1.x网段上的所有机器和当前这台机器进行实践同步 restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap#当该节点丢失网络连接,依然可以作为时间服务器为集群其他节点提供时间同步服务 server 127.127.1.0 fudge 127.127.1.0 stratum 10 # Use public servers from the pool.ntp.org project. # Please consider joining the pool (http://www.pool.ntp.org/join.html). #server 0.centos.pool.ntp.org iburst #server 1.centos.pool.ntp.org iburst #server 2.centos.pool.ntp.org iburst #server 3.centos.pool.ntp.org iburst |
(5)重启ntp服务
1 2 3 4 5 6 | CentOS6: $ sudo chkconfig ntpd on $ sudo service ntpd restartCentOS7: $ sudo systemctl enable ntpd.service $ sudo systemctl restart ntpd.service |
注意:出现报错为:the NTP socket is in use, exiting
解决办法:
1 2 3 | service ntpd stopntpdate ntp.api.bz |
(6)使用从节点,手动同步时间(linux02,linux03)
1 | $ sudo ntpdate linux01 |
(7)设置时间同步任务(linux02,linux03)
1 2 3 4 5 6 7 8 9 10 11 | # crontab -e 编辑时间任务 (尖叫提示:上面的#号代表root用户,下边的#号代表shell注释)# .------------------------------------------minute(0~59)# | .----------------------------------------hours(0~23)# | | .--------------------------------------day of month(1~31)# | | | .------------------------------------month(1~12)# | | | | .----------------------------------day of week(0~6)# | | | | | .--------------------------------command# | | | | | |# | | | | | |*/10 * * * * /usr/sbin/ntpdate linux01 |
(8)重启定时任务
1 2 3 4 | CentOS6: # service crond restartCentOS7: # systemctl restart crond.service |
十二、备份配置好的集群、(必须养成定期备份的习惯)
先关机:
$ sudo shutdown -h now
按照时间新建文件夹,将已经安装完成的3台虚拟机,备份到该文件夹中。
** Hadoop介绍
** HDFS:分布式存储文件
角色:NameNode和DataNode
** YARN:分布式资源调度框架(Hadoop2.x以上才引用)
角色:ResourceManager和NodeManager
** MapReduce:分布式数据处理框架
一、下载hadoop拉到linux中,并解压到指定目录
tips:用smb把hadoop压缩包从window拉到linux时,请注意smb的登陆用户,会导致后面一堆坑,慎用root登陆smb。
(1)将压缩包拉到/home/admin/softwares/installtions/目录
(2) 解压到/home/admin/modules目录
1 | tar -zxf hadoop-2.7.2.tar.gz -C /home/admin/modules/ |
二、配置环境变量
1 2 3 4 5 6 7 8 9 10 11 12 13 | vim /etc/profile在最下面添加export HADOOP_HOME=/home/admin/modules/hadoop-2.7.2/binexport PATH=$PATH:$HADOOP_HOMEexport HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/nativeexport HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"保存退出后source /etc/profile |
配置成功后可用 hadoop version 查看版本,注意没有横杠!
三、配置
** 最终配置效果:
linux01:namenode、datanode、nodemanager
linux02:resourcemanager 、datanode 、nodemanager
linux03:datanode、nodemanager
(1)删除windows脚本
1 2 3 | ** 进入到hadoop的etc/hadoop目录下 $ rm -rf *.cmd |
(2)重命名文件
1 | $ mv mapred-site.xml.template mapred-site.xml |
(3)配置evn文件
查看java路径:
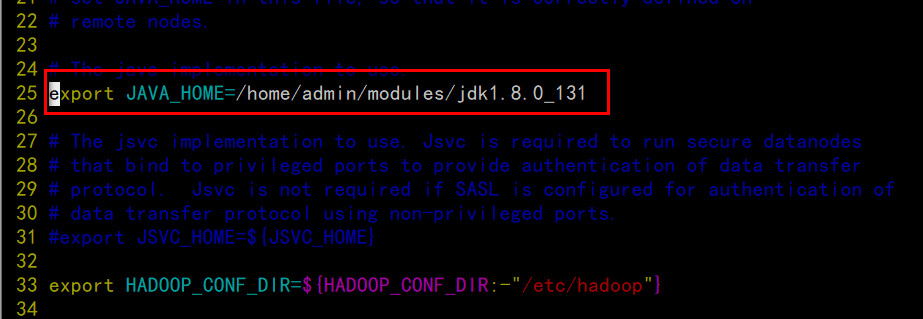
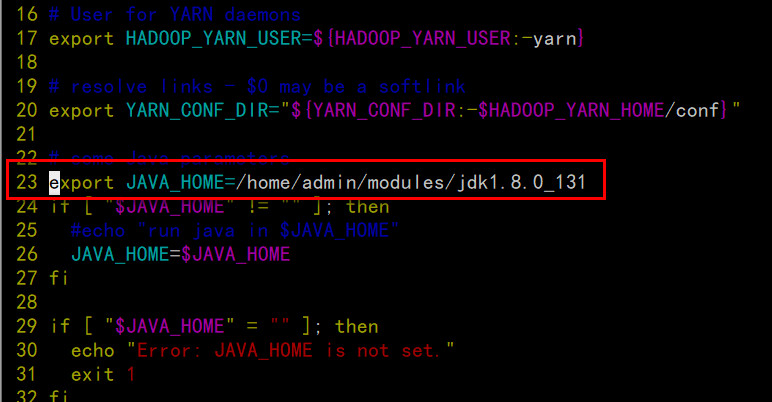
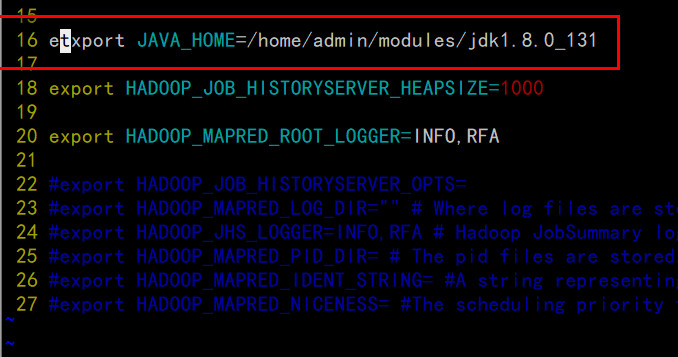
echo $JAVA_HOME,我的机器:/home/admin/modules/jdk1.8.0_131

配置hadoop-env.sh
配置yarn-env.sh
配置mapred-env.sh
(4)配置site文件
配置 core-site.xml
1 2 3 4 5 6 7 8 9 10 11 | <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://linux01:8020</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/admin/modules/hadoop-2.7.2/hadoop-data</value> </property></configuration> |
配置hdfs-site.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | <configuration> <!-- 指定数据冗余份数 --> <property> <name>dfs.replication</name> <value>1</value> </property> <!-- 关闭权限检查--> <property> <name>dfs.permissions.enable</name> <value>false</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>linux03:50090</value> </property> <property> <name>dfs.namenode.http-address</name> <value>linux01:50070</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property></configuration> |
配置yarn-site.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | <configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>linux02</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>86400</value> </property> <property> <name>yarn.log.server.url</name> <value>http://linux01:19888/jobhistory/logs/</value> </property></configuration> |
配置mapred-site.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 配置 MapReduce JobHistory Server 地址 ,默认端口10020 --> <property> <name>mapreduce.jobhistory.address</name> <value>linux01:10020</value> </property> <!-- 配置 MapReduce JobHistory Server web ui 地址, 默认端口19888 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>linux01:19888</value> </property></configuration> |
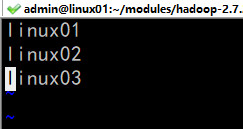
(5)配置slaves文件
四、分发安装配置完成的hadoop到linux02以及linux03
1 2 | $ scp -r hadoop-2.7.2/ linux02:/home/admin/modules/$ scp -r hadoop-2.7.2/ linux03:/home/admin/modules/ |
五、 格式化namenode(在hadoop-2.7.2的根目录下执行)
1 | $ bin/hdfs namenode -format |
如果正常格式化会生成haddop-data文件夹
六、启动服务
1 2 3 4 5 6 | HDFS:(linux01) $ sbin/start-dfs.shYARN:(一定要在ResourceManager所在机器启动,linux02) $ sbin/start-yarn.shJobHistoryServer:(linux01) $ ssh admin@linux01 '/home/admin/modules/hadoop-2.7.2/sbin/mr-jobhistory-daemon.sh start historyserver' |
常见启动失败情况:
(1)hadoop处于安全模式,namenode启动失败,参考链接
解决:磁盘空间不足,需要手动释放资源后再用命令 hdfs dfsadmin -safemode leave 离开安全模式
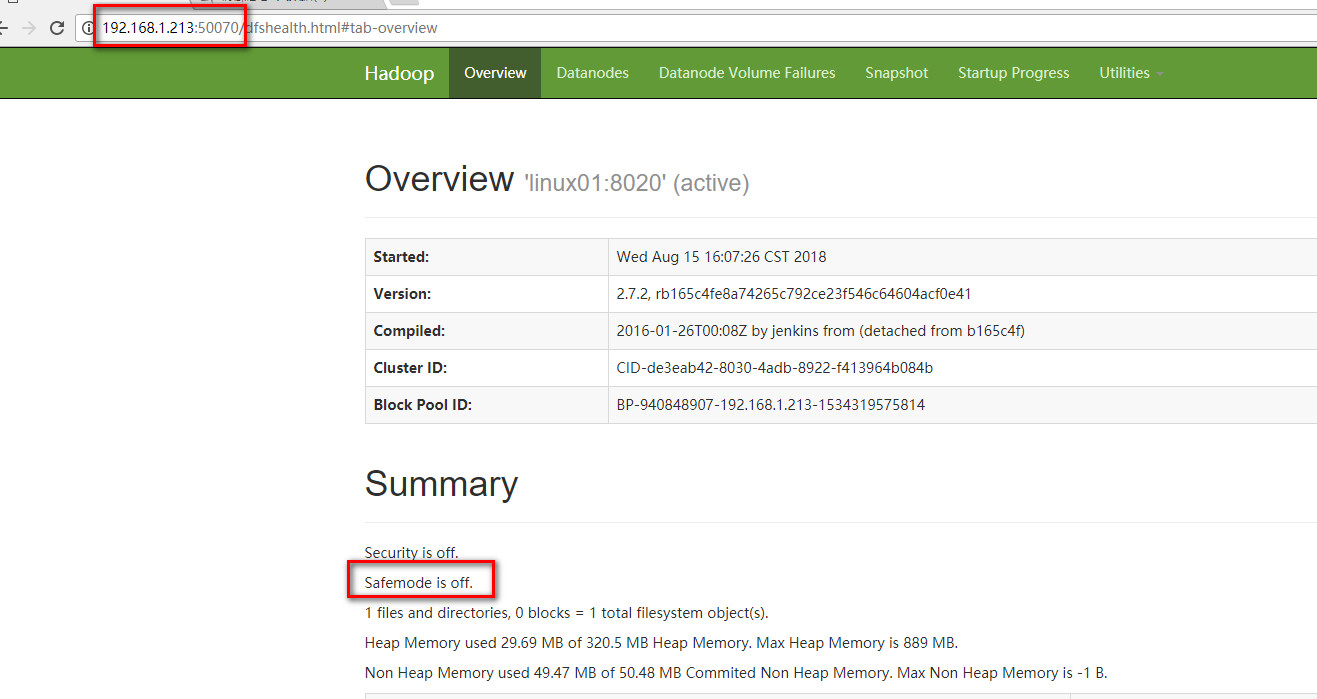
全部完成后查看:
在浏览器输入192.168.1.213:50070,如果不在安全模式证明namenode启动正常
输入192.168.1.214:8088

七、关闭全部服务
1 | $ sbin/stop-all.sh |
八、将系统变量追加到用户变量中(3台机器都要操作)
1 2 3 | $ cd ~$ cat /etc/profile >> .bashrc |
生效 $ source ~/.bashrc
九、编写脚本批量操作三台机器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | $ cd ~$ mkdir tools$ vim /tools/jpsutil.sh添加批量查看jps服务的脚本#!/bin/bashfor i in admin@linux01 admin@linux02 admin@linux03do echo "==================$i===================" ssh $i 'jps'done保存后查看sh jpsutil.sh |
十、遇到问题
关闭虚拟机后重启,重启集群时,namenode启动失败,需要使用命令:bin/hdfs namenode -format
格式化,才能启动。
格式化后datanode又有异常,需要把/hadoop-2.7.2/hadoop-data/dfs/name/current/VERSION里面的clusterID复制下来,依次替换/hadoop-2.7.2/hadoop-data/dfs/data/current/VERSION里的clusterID,再执行:sbin/hadoop-daemon.sh start datanode(全部机器都要操作)。
格式化会导致集群原本存储的数据全部丢失,如何正常关机后,正常开启集群,这个有待研究。
本文链接:https://hqyman.cn/post/1877.html 非本站原创文章欢迎转载,原创文章需保留本站地址!
休息一下,本站随机推荐观看栏目: