
RAG理论
1. 什么是RAG
众所周知,大模型基于海量的数据来训练,它具备非常强大的智能,能够回答各种问题。但是我们在使用过程中发现,通用大模型在某些专业领域能力还不够强,很多领域相关问题很难回答得上来。通常,预训练(pre-train)的大模型只懂得它训练时用的数据,对于训练集之外的新信息(比如网络搜索新数据或特定行业的知识)就不太清楚。
那么怎么构建一个私有的GPT大模型呢?方法有很多种,包括 1. 重新训练私有领域数据的大模型,2. 基于已有大模型做专有数据的微调(FineTuning) 3. 通过RAG技术,优化大模型基础能力。4. 通过Prompt 工程把私有数据在对话中给到大模型。
RAG: Retrieval Augmented Generation,检索增强生成技术。RAG由FaceBook AI实验室 于2020年提出,他们的论文Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks[1], 提供了一种通过给大模型提供向量数据来增强模型能力的方法。
快速来看一下文章摘要:
背景与挑战:这些大型预训练语言模型,因其存储了大量事实知识和在 NLP 任务中的出色表现而闻名。但它们在精确获取和处理知识方面存在局限,尤其是在知识要求高的任务中。这导致它们在特定任务的架构上表现不佳。此外,如何提供决策依据和更新模型中的知识仍是一个挑战。
检索增强生成(RAG)方法:文章提出了一种 RAG 模型的微调方案,这些模型巧妙地结合了预训练的参数记忆(例如 seq2seq 模型)和非参数记忆(例如维基百科的密集向量索引)。通过预训练的神经检索器,这种组合被赋予了新的生命。RAG 模型的目标是利用这两种记忆类型,使语言生成更加生动和具有创造力。
两种RAG形式:研究精心比较了两种 RAG 形式。一种在整个生成过程中使用相同的检索段落,另一种则可以为每个词汇使用不同的段落。。
性能与评估:在多种知识密集型 NLP 任务中,RAG 模型经过微调和评估后,创造了三个开放领域问答任务的新纪录,超越了传统的参数型 seq2seq 模型和专门的检索-提取架构。在语言生成方面,与仅使用参数的 seq2seq 模型相比,RAG 模型能生成更加具体、多样和真实的语言。
整体看一下:论文对RAG技术的理解。主要由 Retriever和Generator两大部分组成。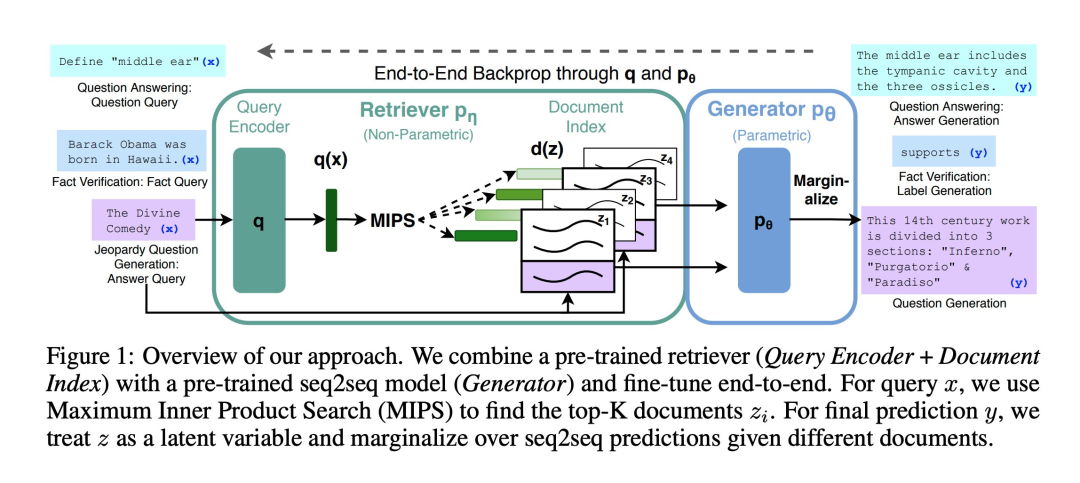
随着时间的推移,尤其是大模型的进步,RAG的架构有些变化,更加组件化和清晰化。如果希望了解更多关于RAG的历史和发展,推荐仔细阅读综述文章:
Retrieval-Augmented Generation for Large Language Models: A Survey
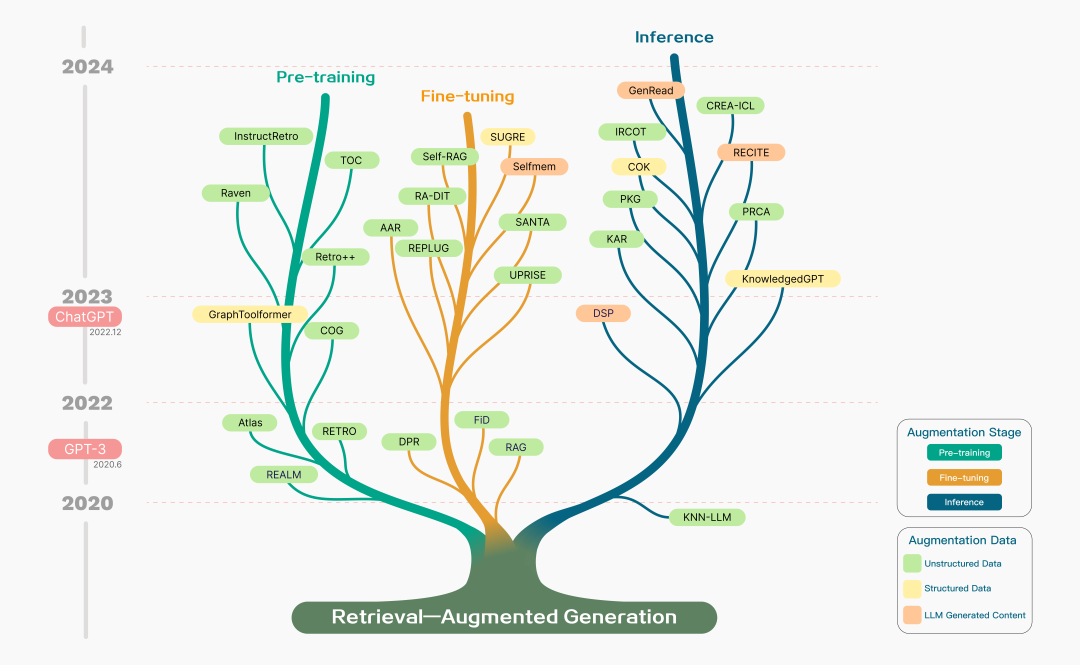 image.png
image.png
2. 进一步理解RAG
第一节相对学术化一些,我们来看一个更好理解的图:
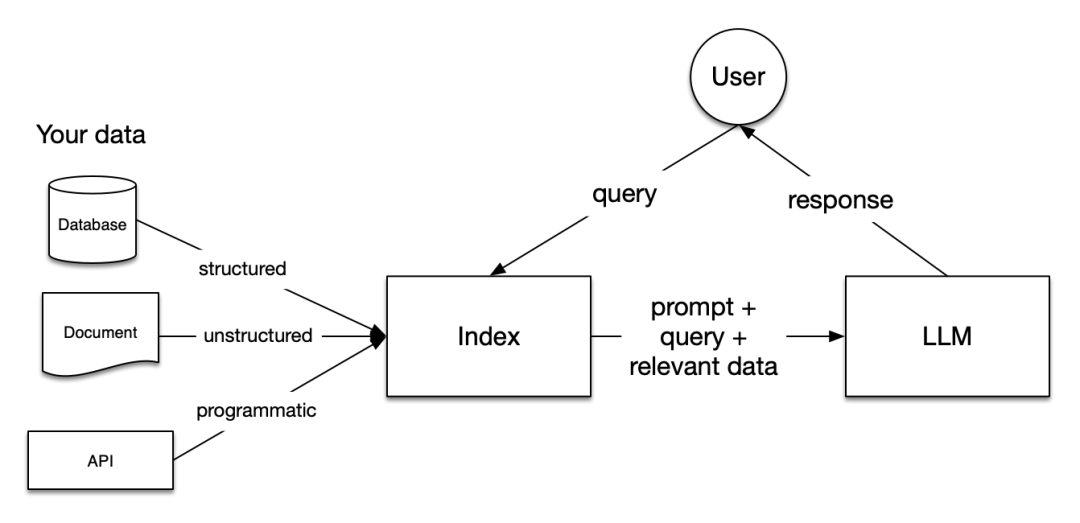
从上图可以看到RAG的系统核心,由User(Query),(Vector) Index , LLM 三大组件组成。
2.1 三大组件
用户发起的查询(User->query)。这种查询一般都是自然语言的,用户不再需要学习类似于之前搜索引擎的DSL或者数据库的SQL。这样大幅降低这类系统的使用门槛。
模型所需的外部数据(Index -> prompt)。可以看到,RAG系统的核心工作其实在这个组件。
索引:将不同类似的用户数据,比如结构化的关系数据库、非结构化的文本、甚至是可编程的API,通过向量嵌入(Vector embedding)方法来将它们变成向量数据。
召回,向量数据的召回,本质上通过余弦相似度来找到最匹配的多个向量。目的是从大量数据中快速筛选出与查询最相关的文档子集,为后续的更详细检索过程提供一个更专注的候选集。这种方法旨在提高检索过程的效率和效果,减少计算资源的需求,并加速响应时间。
查询。这里查询方法有很多种,涉及到向量数据库的相关度计算与评估,不同的查询策略。
大模型(LLM)。这里面的大模型可以是开源的Llama2/Mistral 等,也可以是闭源的GPT3.5/4等。
2.2 实现RAG的五个步骤
重复总结一下,实现RAG中有五个关键步骤,如下图所示:
加载:指将各种文本文件、PDF、其他网站、数据库还是API等数据,导入我们工作流的步骤。
索引:和普通关系数据库无本质差异,在于通过索引加速查询。不同的是,具体的索引算法。
存储:存储索引以及其他元数据,以避免重新索引
查询:对于任何给定的索引,可以进行多种查询,包括子查询、多步查询和混合策略。
评估:提供了关于查询的响应有多准确、快速的客观衡量。
3. RAG的进化
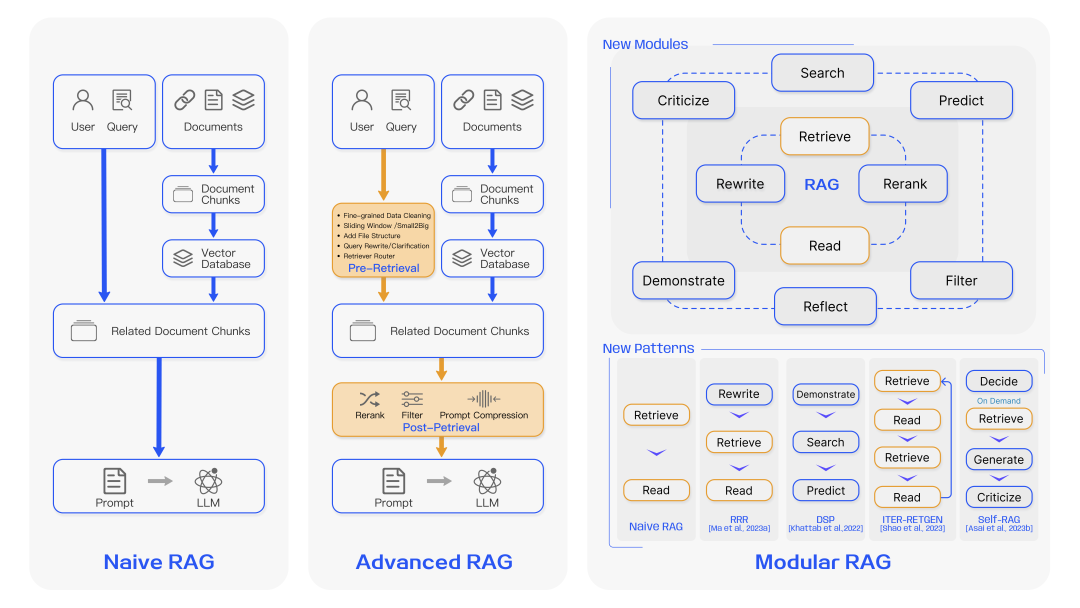 image.png
image.png
初级RAG(Naive RAG):这是RAG的最初形式,包括基本的索引、检索和生成过程。它以简单的方式将检索到的信息与生成任务相结合,但可能存在准确性和效率的问题。
高级RAG(Advanced RAG):在初级RAG的基础上,高级RAG引入了预检索和后检索处理方法,优化了索引和检索流程。这种范式致力于提高检索内容的质量和相关性,以及提升生成任务的效果。
模块化RAG(Modular RAG):这种范式通过引入多样的模块,如搜索模块、记忆模块和额外的生成模块,提供了更多的灵活性和定制化能力。模块化RAG允许根据特定问题的上下文重新配置或替换模块,实现更复杂和高效的检索增强生成任务。
再次推荐阅读综述文章
Retrieval-Augmented Generation for Large Language Models: A Survey
4. RAG能干嘛?
RAG的LLM应用的用例无穷无尽,但大致可以分为三类:
查询引擎[2]: 查询引擎允许您对您的数据提出问题。它接收自然语言查询,并返回响应,以及检索并传递给LLM的参考上下文。
聊天引擎[3]:聊天引擎用于与您的数据进行多轮对话。
Agent(代理)[4]: Agent由LLM驱动,能够实现自动决策。可以采取任意数量的步骤来完成给定的任务,动态地决定最佳行动方案。Agent某种意义上来讲是一种AGI。
5. 给我也搞一个
可以!接下来我们基于Llama Index[5]库来实现一个网页数据的Q&A机器人。
RAG实战
2023 年以来,出现了大量的开源 & 闭源LLM大模型,基本上都能够在上面构建 RAG 系统。最常见的方式包括:
基于LLama-Index 和 GPT3.5 来构建
我们基于来LLama-Index 和 GPT3.5 来构建一个RAG系统,它能够访问你指定的网页数据,你可以提问关于这个网页的任何内容。
Llama-Index是一个简单灵活的数据框架,用于连接自定义数据源到大型语言模型(LLM)。
它提供了API和入门教程,方便用户进行数据的读取和查询。
Llama-Index可以作为桥梁,连接自定义数据和大型语言模型。
通过Llama-Index,用户可以轻松构建应用程序,并访问私有或特定领域的数据。
加载库和数据
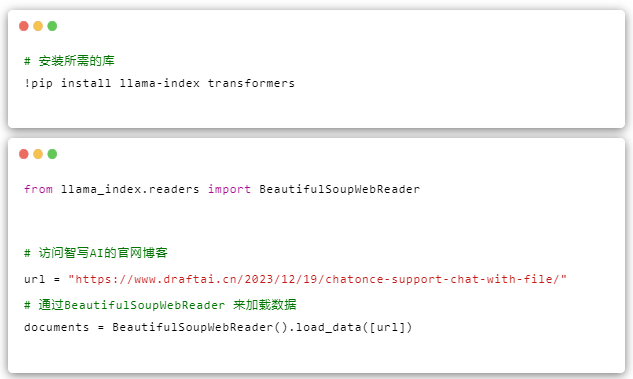
索引&存储
## index
import os
import openai
#设置你在openai的密钥
os.environ['OPENAI_API_KEY'] = "sk-"
openai.api_key = os.environ['OPENAI_API_KEY']
from llama_index.llms import OpenAI
## 指定GPT3.5模型,记得要用gpt-3.5-turbo-1106,更便宜
llm = OpenAI(model="gpt-3.5-turbo-1106", temperature=0)
from llama_index import ServiceContext
## 向量化,采用BAAI的向量库,开源免费,比用OpenAI的embbeding便宜。
service_context = ServiceContext.from_defaults(llm=llm, embed_model="local:BAAI/bge-small-zh-v1.5") #BAAI/bge-small-zh-v1.5. BAAI/bge-small-en-v1.5
查询

不同的查询策略和效果
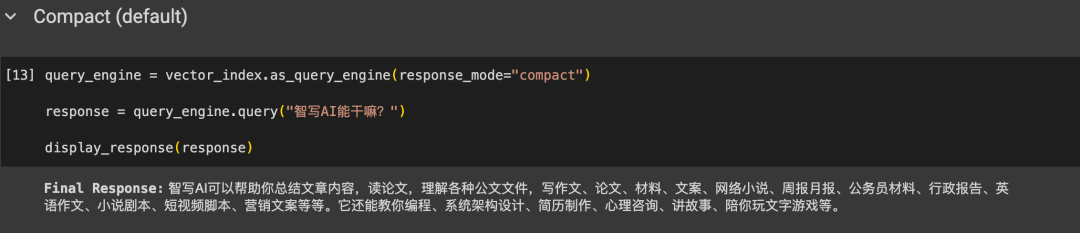 image.png
image.png
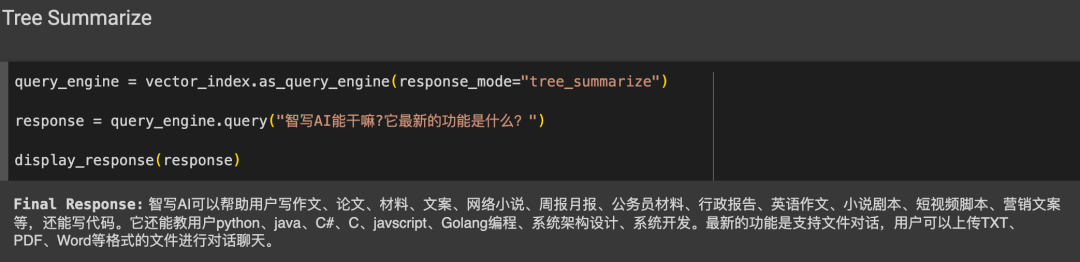 image.png
image.png
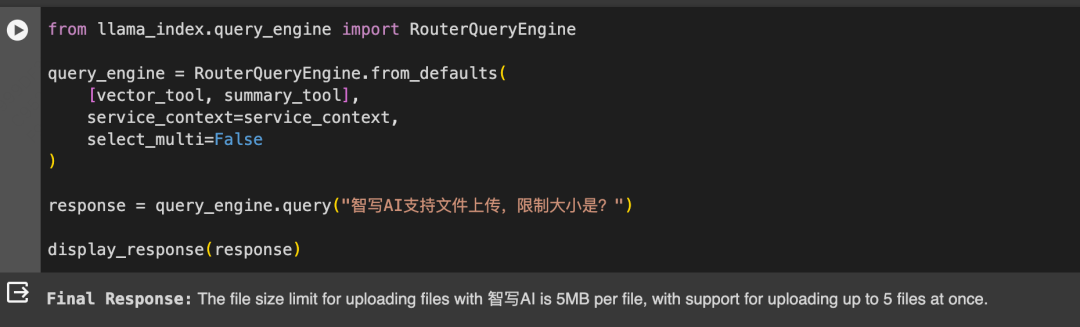 image.png
image.png
完整代码
可以复制我在Colab的notebook [6]直接运行。
推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://hqyman.cn/post/7443.html 非本站原创文章欢迎转载,原创文章需保留本站地址!
打赏

微信支付宝扫一扫,打赏作者吧~
休息一下~~
 HQY 一个和谐有爱的空间
HQY 一个和谐有爱的空间