HTTP Error 418
在学习爬虫时,我们首先学习获取网站页面的html代码:
from urllib import request
resp = request.urlopen('https://movie.douban.com/nowplaying/hangzhou/')html_data = resp.read().decode('utf-8')print(html_data)一般来说,我们通过以上的代码会爬取到网站页面的html代码。
但,通过运行后报错HTTP Error 418。
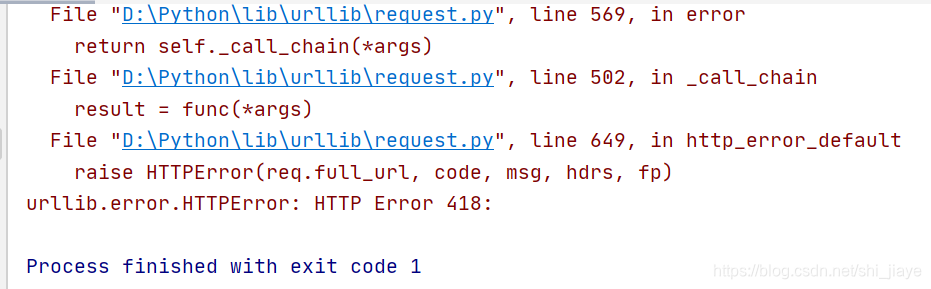
418是个啥!!!当然就是访问的网站有反爬虫机制,而解决方法就是通过模拟浏览器来访问。
首先我们要通过下面的方法获得header中user-agent的内容。
检查(fn+f12)->网络(network)->名称(name)选中一个文件->user-agent
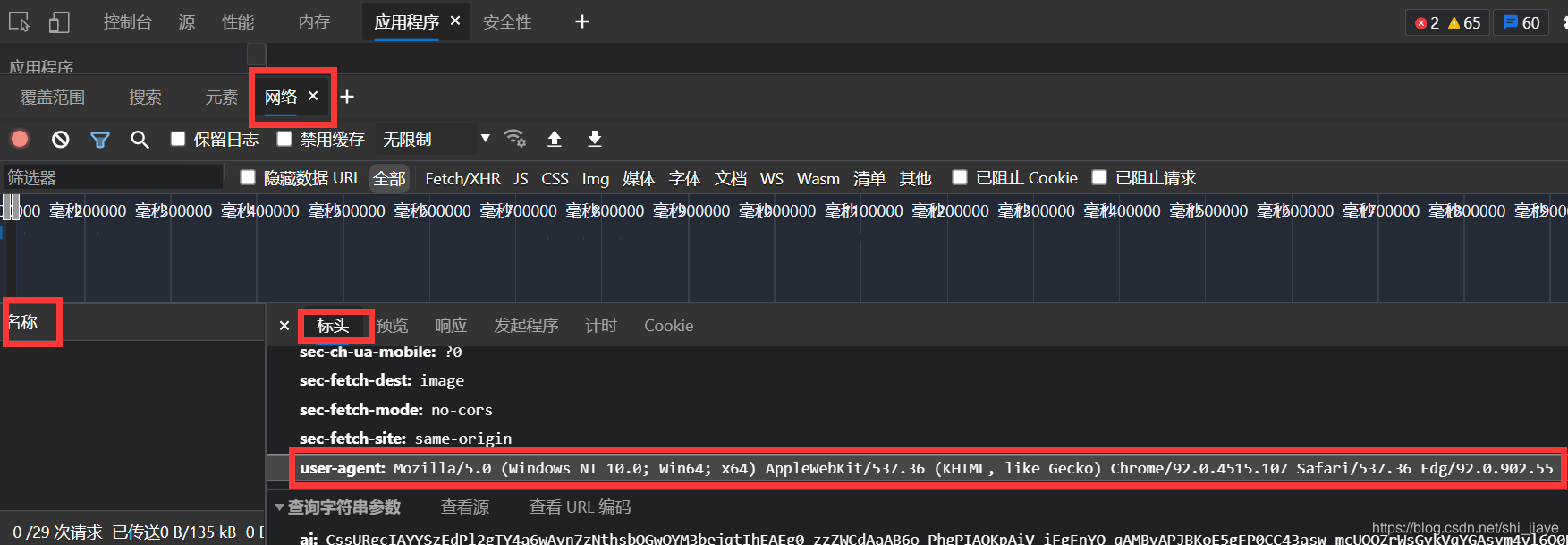
获取header:
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.55'}通过Request(url, headers=header) 就能模仿浏览器访问网站。Request!!!
from urllib import requestfrom urllib.request import Request
url = 'https://movie.douban.com/nowplaying/hangzhou/'header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.55'}ret = Request(url, headers=header)resp = request.urlopen(ret)html_data = resp.read().decode('utf-8')print(html_data)运行结果为:
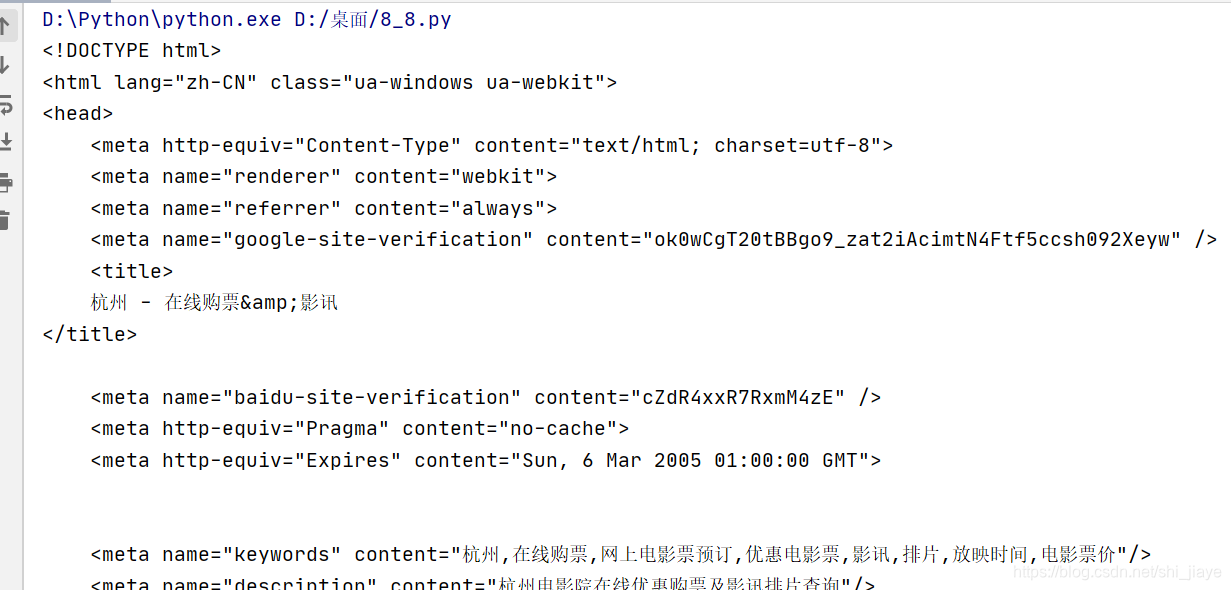
ok 了。
推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://hqyman.cn/post/10137.html 非本站原创文章欢迎转载,原创文章需保留本站地址!
打赏

微信支付宝扫一扫,打赏作者吧~
休息一下~~
 HQY 一个和谐有爱的空间
HQY 一个和谐有爱的空间