
前言
目前写了两篇关于公众号采集的文章,一个是基于hook实时监听公众号的实时推送:更新一下公众号采集监控的程序;还有一个是基于http接口的公众号历史数据采集:【微信插件】公众号历史文章采集。
现在http接口的访问次数非常有限,甚至有的账号直接封死了这条路,例如我的微信号访问http接口会出现未知错误,请稍后再试,已经很多天都是这样了。
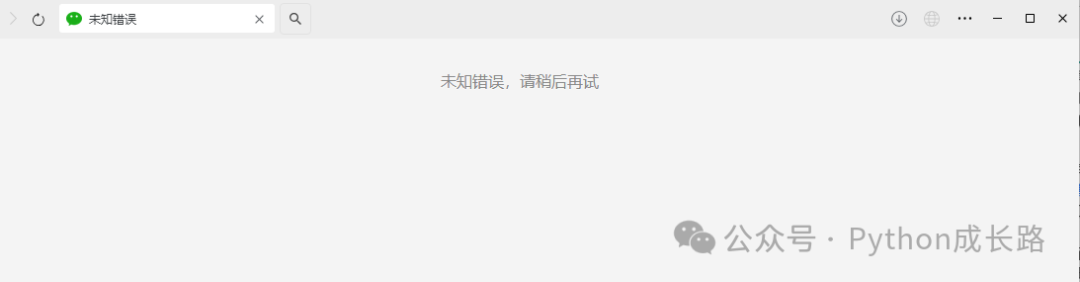
所以这里提供远程调用我服务器的接口来抓公众号历史的方式(按量付费),服务器部署的采集程序是我的一个付费项目,有兴趣的可以看文档:https://wqup3673wn.apifox.cn。
交流群
建了个交流群方便大家反馈和看热闹,看看哪些倒霉鬼被制裁了。后台回复机器人群获取群二维码(很多人进群不用插件也不发言,然后突然就出来发广告),所以限制只能加好友发送机器人群让机器人自动邀请你进群。
插件下载地址
使用方法和下载地址都放github了
github地址:https://github.com/kanadeblisst00/pywxrobot2.0
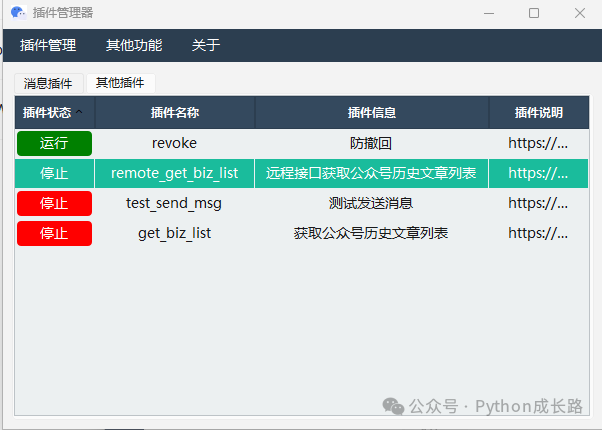
已有插件
更新一下公众号采集监控的程序 【微信插件】自动同意好友请求并邀请进群 【微信插件】自动下载微信聊天中的图片、文件和视频 防撤回 【微信插件】关键词自动回复 【微信插件】公众号历史文章采集 【微信插件】v免签的微信监控端
待更新插件
检测好友状态(拉黑,删除等) 群聊关键词监控 群成员监控(进群,退群等) 进群提示语
下载历史插件
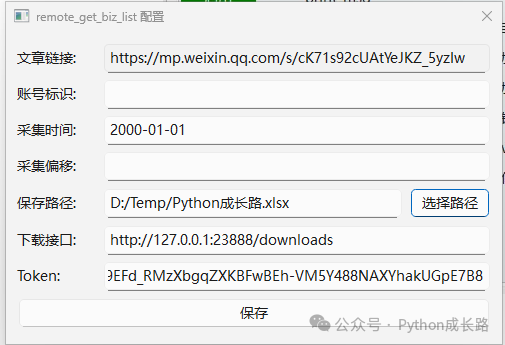
使用方法和之前的历史插件一样,只需要填写你需要下载的公众号的随便哪篇文章(用于提取账号标识,一般是以gh_开头的id),然后设置一下翻页到什么时间结束,想下载全部历史的话设置成2000-01-01就可以。
采集偏移这个不需要填,这个是用于断点续采的,程序会自动填。在填写下列表页数据保存路径,下载接口是用于将文章下载为mhtml和pdf的服务,具体看下面的下载文章介绍。如果你只需要标题链接和时间,可以不填。Token则是用于验证的,获取方法可以看上面的apifox文档。
接着保存点运行插件就会开始下载公众号历史文章里,如果你还配置了下载接口,就可以看到mhtml和pdf文件正在生成。
下载文章为pdf
监听日常和采集历史的接口都只能拿到文章的链接,有的不懂代码的不知道怎么使用文章链接下载成html或者pdf格式,所以顺便写了一个下载文章的服务。
原理比较简单,就是使用playwright打开链接,然后划到文章底部(为了加载所有图片),接着保存成mhtml和pdf即可,这样可以保存网页里的图片和样式,保存后的pdf基本和网页看到的一模一样。另外,为了更方便的和插件对接,还用fastapi写了个服务,这样当插件监听到公众号推送就将链接传给这个服务开始下载文章。采集历史的时候也可以在配置里填写该服务的接口。
这个服务的代码已经开源:https://github.com/kanadeblisst00/download_biz_article
可能有的人还想要其他格式,例如文档格式docx,因为涉及文件格式转换并且我也没有这个需求就不去实现了,有兴趣和能力的可以实现一下然后pr。
我下载了我公众号的所有历史文章,已经上传到了网盘,有兴趣的可以自行下载,下载地址看上面的github。
待添加功能
有的人可能还想下载文章的时候能保留文章的评论,因为有的评论也很有价值,这个后面会更新到pro插件里,敬请期待吧。
使用说明
如果你想从源码启动的话,请自行安装Python和requirements.txt里面的Python库。然后修改一下config.ini里面的配置项
api_port:服务开放在哪个端口,默认23888 save_path:下载的pdf保存到哪个路径,下载的时候还会按公众号名称创建文件夹 copyright:是否只下载原创文章,逻辑暂未实现 chrome_path:playwright驱动的浏览器路径,可以填系统自带的edge的路径 headless:是否使用无头模式,只测试过非无头模式,也就是会打开浏览器,能直观的看到playwright的操作
也打包成了exe方便其它用户使用,可以去github或者在插件的网盘链接里下载。另外如果有人需要打包成docker,方便部署到服务器上, 后面也会添加dockefile。
推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://hqyman.cn/post/11560.html 非本站原创文章欢迎转载,原创文章需保留本站地址!

 微信支付宝扫一扫,打赏作者吧~
微信支付宝扫一扫,打赏作者吧~休息一下~~