
Python 字符串
字符串是 Python 中最常用的数据类型。我们可以使用引号( ' 或 " )来创建字符串。
创建字符串很简单,只要为变量分配一个值即可。例如:
var1 = 'Hello World!' var2 = "Runoob"
Python 访问字符串中的值
Python 不支持单字符类型,单字符在 Python 中也是作为一个字符串使用。
Python 访问子字符串,可以使用方括号来截取字符串,如下实例:
var1 = 'Hello World!'
var2 = "Runoob"
print ("var1[0]: ", var1[0])
print ("var2[1:5]: ", var2[1:5])以上实例执行结果:
var1[0]: H var2[1:5]: unoo
Python 字符串更新
你可以截取字符串的一部分并与其他字段拼接,如下实例:
var1 = 'Hello World!'
print ("已更新字符串 : ", var1[:6] + 'Runoob!')
以上实例执行结果
已更新字符串 : Hello Runoob!
Python转义字符
在需要在字符中使用特殊字符时,python用反斜杠(\)转义字符。如下表:

Python字符串运算符
下表实例变量a值为字符串 "Hello",b变量值为 "Python":
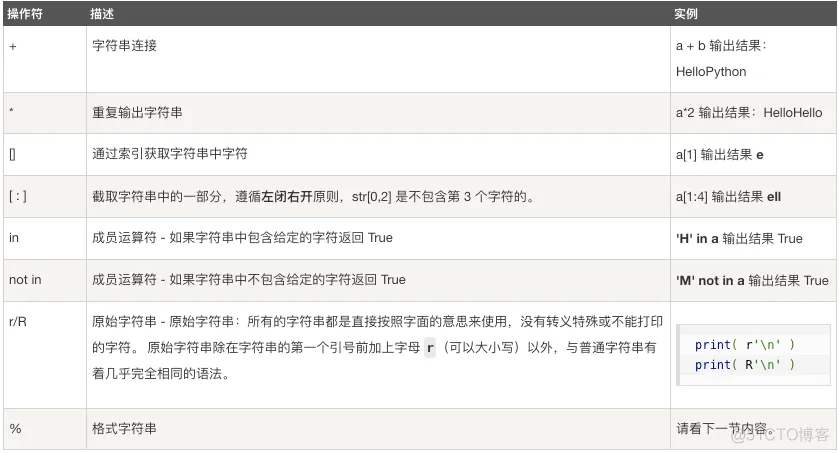
a = "Hello"
b = "Python"
print("a + b 输出结果:", a + b)
print("a * 2 输出结果:", a * 2)
print("a[1] 输出结果:", a[1])
print("a[1:4] 输出结果:", a[1:4])
if( "H" in a) :
print("H 在变量 a 中")
else :
print("H 不在变量 a 中")
if( "M" not in a) :
print("M 不在变量 a 中")
else :
print("M 在变量 a 中")
print (r'\n')
print (R'\n')
以上实例输出结果为:
a + b 输出结果: HelloPython
a * 2 输出结果: HelloHello
a[1] 输出结果: e
a[1:4] 输出结果: ell
H 在变量 a 中
M 不在变量 a 中
\n
\n
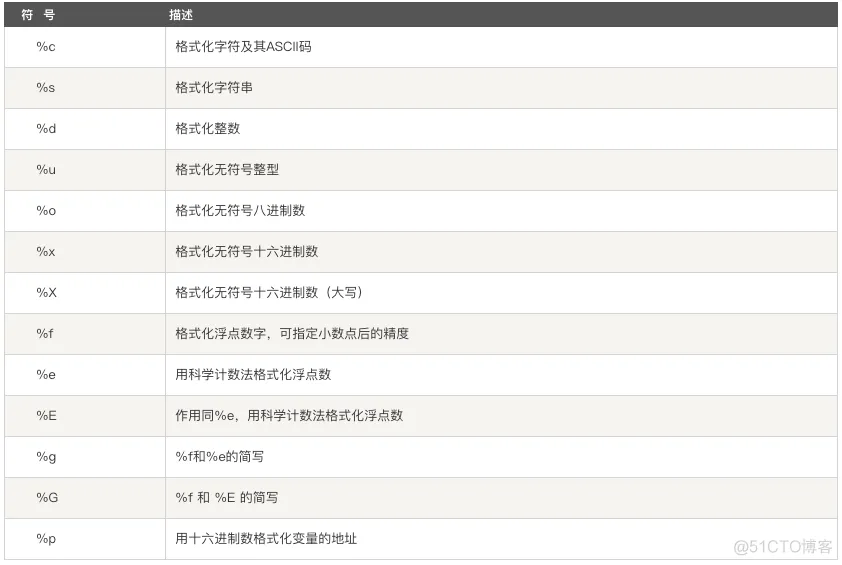
Python字符串格式化
Python 支持格式化字符串的输出 。尽管这样可能会用到非常复杂的表达式,但最基本的用法是将一个值插入到一个有字符串格式符 %s 的字符串中。
在 Python 中,字符串格式化使用与 C 中 sprintf 函数一样的语法。
print ("我叫 %s 今年 %d 岁!" % ('小明', 10))
以上实例输出结果:
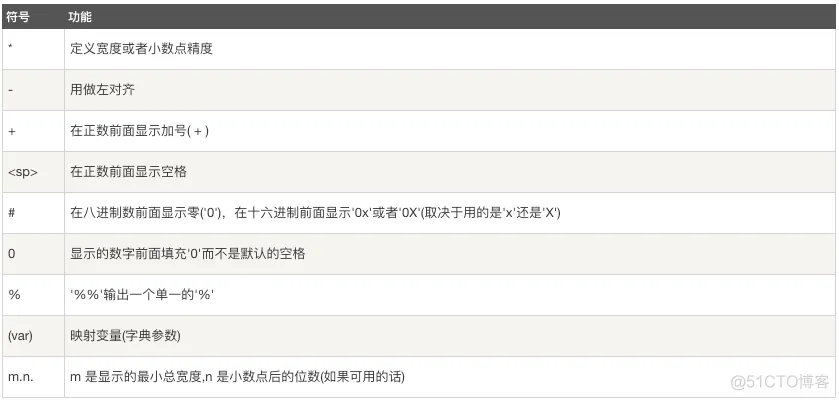
我叫 小明 今年 10 岁!python字符串格式化符号:
print("a的值:%c"%'a')
a的值:a格式化操作符辅助指令:
Python三引号
python三引号允许一个字符串跨多行,字符串中可以包含换行符、制表符以及其他特殊字符。实例如下
para_str = """这是一个多行字符串的实例 多行字符串可以使用制表符 TAB ( \t )。 也可以使用换行符 [ \n ]。 """ print (para_str) 以上实例执行结果为: 这是一个多行字符串的实例 多行字符串可以使用制表符 TAB ( )。 也可以使用换行符 [ ]。
三引号让程序员从引号和特殊字符串的泥潭里面解脱出来,自始至终保持一小块字符串的格式是所谓的WYSIWYG(所见即所得)格式的。
一个典型的用例是,当你需要一块HTML或者SQL时,这时用字符串组合,特殊字符串转义将会非常的繁琐。
errHTML = '''
<HTML><HEAD><TITLE>
Friends CGI Demo</TITLE></HEAD>
<BODY><H3>ERROR</H3>
<B>%s</B><P>
<FORM><INPUT TYPE=button VALUE=Back
ONCLICK="window.history.back()"></FORM>
</BODY></HTML>
'''
cursor.execute('''
CREATE TABLE users (
login VARCHAR(8),
uid INTEGER,
prid INTEGER)
''')
Unicode 字符串
在Python2中,普通字符串是以8位ASCII码进行存储的,而Unicode字符串则存储为16位unicode字符串,这样能够表示更多的字符集。使用的语法是在字符串前面加上前缀 u。
在Python3中,所有的字符串都是Unicode字符串。
Python 的字符串内建函数
Python 的字符串常用内建函数如下:
1、capitalize()
将字符串的第一个字符转换为大写
str = "this is string example from runoob....wow!!!"
print ("str.capitalize() : ", str.capitalize())
以上实例输出结果如下:
str.capitalize() : This is string example from runoob....wow!!!
2、center(width, fillchar)
返回一个指定的宽度 width 居中的字符串,fillchar 为填充的字符,默认为空格。
参数
width -- 字符串的总宽度。
fillchar -- 填充字符。
返回值
返回一个指定的宽度 width 居中的字符串,如果 width 小于字符串宽度直接返回字符串,否则使用 fillchar 去填充。
str = "[www.runoob.com]"
print ("str.center(40, '*') : ", str.center(40, '*'))以上实例输出结果如下: str.center(40, '*') : ************[www.runoob.com]************
3、count(sub, start= 0,end=len(string))
返回 sub 在 string 里面出现的次数,如果 start 或者 end 指定则返回指定范围内 str 出现的次数
参数
sub -- 搜索的子字符串
start -- 字符串开始搜索的位置。默认为第一个字符,第一个字符索引值为0。
end -- 字符串中结束搜索的位置。字符中第一个字符的索引为 0。默认为字符串的最后一个位置。
返回值
该方法返回子字符串在字符串中出现的次数。
str="www.runoob.com"
sub='o'
print ("str.count('o') : ", str.count(sub))
sub='run'
print ("str.count('run', 0, 10) : ", str.count(sub,0,10))
以上实例输出结果如下:
str.count('o') : 3
str.count('run', 0, 10) : 1
4、bytes.decode()
bytes.decode(encoding="utf-8", errors="strict")
Python3 中没有 decode 方法,但我们可以使用 bytes 对象的 decode() 方法来解码给定的 bytes 对象,这个 bytes 对象可以由 str.encode() 来编码返回。
参数
encoding -- 要使用的编码,如"UTF-8"。
errors -- 设置不同错误的处理方案。默认为 'strict',意为编码错误引起一个UnicodeError。 其他可能得值有 'ignore', 'replace', 'xmlcharrefreplace', 'backslashreplace' 以及通过 codecs.register_error() 注册的任何值。
返回值
该方法返回解码后的字符串。
str = "python教程";
str_utf8 = str.encode("UTF-8")
str_gbk = str.encode("GBK")
print(str)
print("UTF-8 编码:", str_utf8)
print("GBK 编码:", str_gbk)
print("UTF-8 解码:", str_utf8.decode('UTF-8','strict'))
print("GBK 解码:", str_gbk.decode('GBK','strict'))
以上实例输出结果如下:
python教程
UTF-8 编码: b'\xe8\x8f\x9c\xe9\xb8\x9f\xe6\x95\x99\xe7\xa8\x8b'
GBK 编码: b'\xb2\xcb\xc4\xf1\xbd\xcc\xb3\xcc'
UTF-8 解码: python教程
GBK 解码: python教程
5、encode(encoding='UTF-8',errors='strict')
以 encoding 指定的编码格式编码字符串,如果出错默认报一个ValueError 的异常,除非 errors 指定的是'ignore'或者'replace'
参数
encoding -- 要使用的编码,如: UTF-8。
errors -- 设置不同错误的处理方案。默认为 'strict',意为编码错误引起一个UnicodeError。 其他可能得值有 'ignore', 'replace', 'xmlcharrefreplace', 'backslashreplace' 以及通过 codecs.register_error() 注册的任何值。
返回值
str = "python教程";
str_utf8 = str.encode("UTF-8")
str_gbk = str.encode("GBK")
print(str)
print("UTF-8 编码:", str_utf8)
print("GBK 编码:", str_gbk)
print("UTF-8 解码:", str_utf8.decode('UTF-8','strict'))
print("GBK 解码:", str_gbk.decode('GBK','strict'))
以上实例输出结果如下:
python教程
UTF-8 编码: b'\xe8\x8f\x9c\xe9\xb8\x9f\xe6\x95\x99\xe7\xa8\x8b'
GBK 编码: b'\xb2\xcb\xc4\xf1\xbd\xcc\xb3\xcc'
UTF-8 解码: python教程
GBK 解码: python教程
该方法返回编码后的字符串,它是一个 bytes 对象。
6、endswith()
用于判断字符串是否以指定后缀结尾,如果以指定后缀结尾返回True,否则返回False。可选参数"start"与"end"为检索字符串的开始与结束位置。
endswith()方法语法: str.endswith(suffix[, start[, end]])
参数
suffix -- 该参数可以是一个字符串或者是一个元素。
start -- 字符串中的开始位置。
end -- 字符中结束位置。
返回值
如果字符串含有指定的后缀返回True,否则返回False。
Str='Runoob example....wow!!!' suffix='!!' print (Str.endswith(suffix)) print (Str.endswith(suffix,20)) suffix='run' print (Str.endswith(suffix)) print (Str.endswith(suffix, 0, 19)) 以上实例输出结果如下: True True False False
7、expandtabs()
把字符串中的 tab 符号('\t')转为空格,tab 符号('\t')默认的空格数是 8
语法
expandtabs()方法语法:
str.expandtabs(tabsize=8)
参数
tabsize -- 指定转换字符串中的 tab 符号('\t')转为空格的字符数。
返回值
该方法返回字符串中的 tab 符号('\t')转为空格后生成的新字符串。
str = "this is\tstring example....wow!!!"
print ("原始字符串: " + str)
print ("替换 \\t 符号: " + str.expandtabs())
print ("使用16个空格替换 \\t 符号: " + str.expandtabs(16))
以上实例输出结果如下:
原始字符串: this is string example....wow!!!
替换 \t 符号: this is string example....wow!!!
使用16个空格替换 \t 符号: this is string example....wow!!!
8、find()
检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,如果指定范围内如果包含指定索引值,返回的是索引值在字符串中的起始位置。如果不包含索引值,返回-1。
语法
find()方法语法:
str.find(str, beg=0, end=len(string))
参数
str -- 指定检索的字符串
beg -- 开始索引,默认为0。
end -- 结束索引,默认为字符串的长度。
返回值
如果包含子字符串返回开始的索引值,否则返回-1。
str1 = "Runoob example....wow!!!" str2 = "exam"; print (str1.find(str2)) print (str1.find(str2, 5)) print (str1.find(str2, 10)) 以上实例输出结果如下: 7 7 -1
9、index()
检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,该方法与 python find()方法一样,只不过如果str不在 string中会报一个异常。
语法
index()方法语法:
str.index(str, beg=0, end=len(string))
参数
str -- 指定检索的字符串
beg -- 开始索引,默认为0。
end -- 结束索引,默认为字符串的长度。
返回值
如果包含子字符串返回开始的索引值,否则抛出异常。
str1 = "Runoob example....wow!!!" str2 = "exam"; print (str1.index(str2)) print (str1.index(str2, 5)) print (str1.index(str2, 10)) 以上实例输出结果如下(未发现的会出现异常信息): 7 7 Traceback (most recent call last): File "test.py", line 8, in <module> print (str1.index(str2, 10)) ValueError: substring not found
10、isalnum()
检测字符串是否由字母和数字组成。
语法
isalnum()方法语法:
str.isalnum()
参数
无。
返回值
如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False
str = "runoob2016" # 字符串没有空格 print (str.isalnum()) str = "www.runoob.com" print (str.isalnum()) 以上实例输出结果如下: True False
11、 isalpha()
检测字符串是否只由字母组成。
语法
isalpha()方法语法:
str.isalpha()
参数
无。
返回值
如果字符串至少有一个字符并且所有字符都是字母则返回 True,否则返回 False
str = "runoob" print (str.isalpha()) str = "Runoob example....wow!!!" print (str.isalpha()) 以上实例输出结果如下: True False
str.isalpha() 方法,汉字也会返回 True
>>> Str = '哈哈' >>> print(Str, Str.isalpha()) 哈哈 True
12、isdigit()
检测字符串是否只由数字组成。
语法
isdigit()方法语法:
str.isdigit()
参数
无。
返回值
如果字符串只包含数字则返回 True 否则返回 False。
str = "123456"; print (str.isdigit()) str = "Runoob example....wow!!!" print (str.isdigit()) 以上实例输出结果如下: True False
13、islower()
检测字符串是否由小写字母组成。
语法
islower()方法语法:
str.islower()
参数
无。
返回值
如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False
str = "RUNOOB example....wow!!!" print (str.islower()) str = "runoob example....wow!!!" print (str.islower()) 以上实例输出结果如下: False True
14、isnumeric()
检测字符串是否只由数字组成。这种方法是只针对unicode对象。
注:定义一个字符串为Unicode,只需要在字符串前添加 'u' 前缀即可,具体可以查看本章节例子。
语法
isnumeric()方法语法:
str.isnumeric()
参数
无。
返回值
如果字符串中只包含数字字符,则返回 True,否则返回 False
str = "runoob2016" print (str.isnumeric()) str = "23443434" print (str.isnumeric()) 以上实例输出结果如下: False True
15、isspace()
检测字符串是否只由空白字符组成。
语法
isspace()方法语法:
str.isspace()
参数
无。
返回值
如果字符串中只包含空格,则返回 True,否则返回 False.
str = " " print (str.isspace()) str = "Runoob example....wow!!!" print (str.isspace()) 以上实例输出结果如下: True False
16、istitle() 检测字符串中所有的单词拼写首字母是否为大写,且其他字母为小写。
语法
istitle()方法语法:
str.istitle()
参数
无。
返回值
如果字符串中所有的单词拼写首字母是否为大写,且其他字母为小写则返回 True,否则返回 False.
str = "This Is String Example...Wow!!!" print (str.istitle()) str = "This is string example....wow!!!" print (str.istitle()) str = 'ThiS Is StrinG' print (str.istitle()) str = "This Is String Example...Wow !!!" print (str.istitle()) 以上实例输出结果如下: True False False True
17、isupper()
检测字符串中所有的字母是否都为大写。
语法
isupper()方法语法:
str.isupper()
参数
无。
返回值
如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False
str = "THIS IS STRING EXAMPLE....WOW!!!" print (str.isupper()) str = "THIS is string example....wow!!!" print (str.isupper()) 以上实例输出结果如下: True False
18、 join()
用于将序列中的元素以指定的字符连接生成一个新的字符串。
语法
join()方法语法:
str.join(sequence)
参数
sequence -- 要连接的元素序列。
返回值
返回通过指定字符连接序列中元素后生成的新字符串。
s1 = "-"
s2 = ""
seq = ("r", "u", "n", "o", "o", "b") # 字符串序列
print (s1.join( seq ))
print (s2.join( seq ))
以上实例输出结果如下:
r-u-n-o-o-b
runoob
19、len()
返回对象(字符、列表、元组等)长度或项目个数。
语法
len()方法语法:
len( s )
参数
s -- 对象。
返回值
返回对象长度。
>>>str = "runoob" >>> len(str) # 字符串长度 6 >>> l = [1,2,3,4,5] >>> len(l) # 列表元素个数 5
20、ljust()
返回一个原字符串左对齐,并使用空格填充至指定长度的新字符串。如果指定的长度小于原字符串的长度则返回原字符串。
语法
ljust()方法语法:
str.ljust(width[, fillchar])
参数
width -- 指定字符串长度。
fillchar -- 填充字符,默认为空格。
返回值
返回一个原字符串左对齐,并使用空格填充至指定长度的新字符串。如果指定的长度小于原字符串的长度则返回原字符串。
str = "Runoob example....wow!!!" print (str.ljust(50, '*')) 以上实例输出结果如下: Runoob example....wow!!!**************************
21、lower()
转换字符串中所有大写字符为小写。
语法
lower()方法语法:
str.lower()
参数
无。
返回值
返回将字符串中所有大写字符转换为小写后生成的字符串。
str = "Runoob EXAMPLE....WOW!!!" print( str.lower() ) 以上实例输出结果如下: runoob example....wow!!!
22、lstrip()
用于截掉字符串左边的空格或指定字符。
语法
lstrip()方法语法:
str.lstrip([chars])
参数
chars --指定截取的字符。
返回值
返回截掉字符串左边的空格或指定字符后生成的新字符串。
str = " this is string example....wow!!! ";
print( str.lstrip() );
str = "88888888this is string example....wow!!!8888888";
print( str.lstrip('8') );
以上实例输出结果如下:
this is string example....wow!!!
this is string example....wow!!!8888888
23、maketrans()
用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。
两个字符串的长度必须相同,为一一对应的关系。
注:Python3.4已经没有string.maketrans()了,取而代之的是内建函数: bytearray.maketrans()、bytes.maketrans()、str.maketrans()
语法
maketrans()方法语法:
str.maketrans(intab, outtab)
参数
intab -- 字符串中要替代的字符组成的字符串。
outtab -- 相应的映射字符的字符串。
返回值
返回字符串转换后生成的新字符串。
intab = "aeiou" outtab = "12345" trantab = str.maketrans(intab, outtab) str = "this is string example....wow!!!" print (str.translate(trantab)) 以上实例输出结果如下: th3s 3s str3ng 2x1mpl2....w4w!!!
24、max()
返回字符串中最大的字母。
语法
max()方法语法:
max(str)
参数
str -- 字符串。
返回值
返回字符串中最大的字母。
str = "runoob"
print ("最大字符: " + max(str))
以上实例输出结果如下:
最大字符: u
25、 min()
返回字符串中最小的字母。
语法
min()方法语法:
min(str)
参数
str -- 字符串。
返回值
返回字符串中最小的字母。
tr = "runoob";
print ("最小字符: " + min(str));
以上实例输出结果如下:
最小字符: b
26、replace()
把字符串中的 old(旧字符串) 替换成 new(新字符串),如果指定第三个参数max,则替换不超过 max 次。
语法
replace()方法语法:
str.replace(old, new[, max])
参数
old -- 将被替换的子字符串。
new -- 新字符串,用于替换old子字符串。
max -- 可选字符串, 替换不超过 max 次
返回值
返回字符串中的 old(旧字符串) 替换成 new(新字符串)后生成的新字符串,如果指定第三个参数max,则替换不超过 max 次。
str = "www.w3cschool.cc"
print ("菜鸟教程旧地址:", str)
print ("菜鸟教程新地址:", str.replace("w3cschool.cc", "runoob.com"))
str = "this is string example....wow!!!"
print (str.replace("is", "was", 3))
以上实例输出结果如下:
菜鸟教程旧地址: www.w3cschool.cc
菜鸟教程新地址: www.runoob.com
thwas was string example....wow!!!
str1 = 'abacadaea'
str2 = str1.replace('a','s',3)
print(str2)
sbscsdaea
27、rfind()
返回字符串最后一次出现的位置,如果没有匹配项则返回-1。
语法
rfind()方法语法:
str.rfind(str, beg=0 end=len(string))
参数
str -- 查找的字符串
beg -- 开始查找的位置,默认为0
end -- 结束查找位置,默认为字符串的长度。
返回值
返回字符串最后一次出现的位置,如果没有匹配项则返回-1。
str1 = "this is really a string example....wow!!!" str2 = "is" print (str1.rfind(str2)) print (str1.rfind(str2, 0, 10)) print (str1.rfind(str2, 10, 0)) print (str1.find(str2)) print (str1.find(str2, 0, 10)) print (str1.find(str2, 10, 0)) 以上实例输出结果如下: 5 5 -1 2 2 -1
28、rindex()
返回子字符串 str 在字符串中最后出现的位置,如果没有匹配的字符串会报异常,你可以指定可选参数[beg:end]设置查找的区间。
语法
rindex()方法语法:
str.rindex(str, beg=0 end=len(string))
参数
str -- 查找的字符串
beg -- 开始查找的位置,默认为0
end -- 结束查找位置,默认为字符串的长度。
返回值
返回子字符串 str 在字符串中最后出现的位置,如果没有匹配的字符串会报异常。
str1 = "this is really a string example....wow!!!" str2 = "is" print (str1.rindex(str2)) print (str1.rindex(str2,10)) 以上实例输出结果如下: 5 Traceback (most recent call last): File "test.py", line 6, in <module> print (str1.rindex(str2,10)) ValueError: substring not found
29、rjust()
返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串。如果指定的长度小于字符串的长度则返回原字符串。
语法
rjust()方法语法:
str.rjust(width[, fillchar])
参数
width -- 指定填充指定字符后中字符串的总长度.
fillchar -- 填充的字符,默认为空格。
返回值
返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串。如果指定的长度小于字符串的长度则返回原字符串
str = "this is string example....wow!!!" print (str.rjust(50, '*')) 以上实例输出结果如下: ******************this is string example....wow!!!
30、rstrip()
删除 string 字符串末尾的指定字符(默认为空格).
语法
rstrip()方法语法:
str.rstrip([chars])
参数
chars -- 指定删除的字符(默认为空格)
返回值
返回删除 string 字符串末尾的指定字符后生成的新字符串。
str = " this is string example....wow!!! "
print (str.rstrip())
str = "*****this is string example....wow!!!*****"
print (str.rstrip('*'))
以上实例输出结果如下:
this is string example....wow!!!
*****this is string example....wow!!!
31、split()
通过指定分隔符对字符串进行切片,如果参数 num 有指定值,则仅分隔 num+1 个子字符串
语法
split()方法语法:
str.split(str="", num=string.count(str))
参数
str -- 分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。
num -- 分割次数。默认为 -1, 即分隔所有。
返回值
返回分割后的字符串列表。
str = "this is string example....wow!!!"
print (str.split( )) # 以空格为分隔符
print (str.split('i',1)) # 以 i 为分隔符
print (str.split('w')) # 以 w 为分隔符
以上实例输出结果如下:
['this', 'is', 'string', 'example....wow!!!']
['th', 's is string example....wow!!!']
['this is string example....', 'o', '!!!']以下实例以 # 号为分隔符,指定第二个参数为 1,返回两个参数列表。
txt = "Google#Runoob#Taobao#Facebook"
# 第二个参数为 1,返回两个参数列表
x = txt.split("#", 1)
print(x)
以上实例输出结果如下:
['Google', 'Runoob#Taobao#Facebook']
32、splitlines()
按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。
语法
splitlines()方法语法:
str.splitlines([keepends])
参数
keepends -- 在输出结果里是否去掉换行符('\r', '\r\n', \n'),默认为 False,不包含换行符,如果为 True,则保留换行符。
返回值
返回一个包含各行作为元素的列表。
>>> 'ab c\n\nde fg\rkl\r\n'.splitlines() ['ab c', '', 'de fg', 'kl'] >>> 'ab c\n\nde fg\rkl\r\n'.splitlines(True) ['ab c\n', '\n', 'de fg\r', 'kl\r\n'] >>>
33、startswith()
用于检查字符串是否是以指定子字符串开头,如果是则返回 True,否则返回 False。如果参数 beg 和 end 指定值,则在指定范围内检查。
语法
startswith()方法语法:
str.startswith(substr, beg=0,end=len(string));
参数
str -- 检测的字符串。
substr -- 指定的子字符串。
strbeg -- 可选参数用于设置字符串检测的起始位置。
strend -- 可选参数用于设置字符串检测的结束位置。
返回值
如果检测到字符串则返回True,否则返回False。
str = "this is string example....wow!!!" print (str.startswith( 'this' )) # 字符串是否以 this 开头 print (str.startswith( 'string', 8 )) # 从第八个字符开始的字符串是否以 string 开头 print (str.startswith( 'this', 2, 4 )) # 从第2个字符开始到第四个字符结束的字符串是否以 this 开头 以上实例输出结果如下: True True False
34、strip()
用于移除字符串头尾指定的字符(默认为空格)或字符序列。
注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
语法
strip()方法语法:
str.strip([chars]);
参数
chars -- 移除字符串头尾指定的字符序列。
返回值
返回移除字符串头尾指定的字符序列生成的新字符串。
str = "*****this is **string** example....wow!!!*****" print (str.strip( '*' )) # 指定字符串 * 以上实例输出结果如下: this is **string** example....wow!!!
从结果上看,可以注意到中间部分的字符并未删除。
以上下例演示了只要头尾包含有指定字符序列中的字符就删除:
str = "123abcrunoob321" print (str.strip( '12' )) # 字符序列为 12 以上实例输出结果如下: 3abcrunoob3
35、swapcase() 用于对字符串的大小写字母进行转换。
语法
swapcase()方法语法:
str.swapcase();
参数
NA。
返回值
返回大小写字母转换后生成的新字符串。
str = "this is string example....wow!!!" print (str.swapcase()) str = "This Is String Example....WOW!!!" print (str.swapcase()) 以上实例输出结果如下: THIS IS STRING EXAMPLE....WOW!!! tHIS iS sTRING eXAMPLE....wow!!!
36、title()
返回"标题化"的字符串,就是说所有单词的首个字母转化为大写,其余字母均为小写(见 istitle())。
语法
title()方法语法:
str.title();
参数
NA。
返回值
返回"标题化"的字符串,就是说所有单词的首字母都转化为大写。
str = "this is string example from runoob....wow!!!" print (str.title()) 以上实例输出结果如下: This Is String Example From Runoob....Wow!!!
请注意,非字母后的第一个字母将转换为大写字母:
txt = "hello b2b2b2 and 3g3g3g" x = txt.title() print(x) 输出结果为: Hello B2B2B2 And 3G3G3G
37、translate()
根据参数table给出的表(包含 256 个字符)转换字符串的字符,要过滤掉的字符放到 deletechars 参数中。
语法
translate()方法语法:
str.translate(table) bytes.translate(table[, delete]) bytearray.translate(table[, delete])
参数
table -- 翻译表,翻译表是通过 maketrans() 方法转换而来。
deletechars -- 字符串中要过滤的字符列表。
返回值
返回翻译后的字符串,若给出了 delete 参数,则将原来的bytes中的属于delete的字符删除,剩下的字符要按照table中给出的映射来进行映射 。
intab = "aeiou" outtab = "12345" trantab = str.maketrans(intab, outtab) # 制作翻译表 str = "this is string example....wow!!!" print (str.translate(trantab)) 以上实例输出结果如下: th3s 3s str3ng 2x1mpl2....w4w!!!
以下实例演示如何过滤掉的字符 o:
# 制作翻译表 bytes_tabtrans = bytes.maketrans(b'abcdefghijklmnopqrstuvwxyz', b'ABCDEFGHIJKLMNOPQRSTUVWXYZ') # 转换为大写,并删除字母o print(b'runoob'.translate(bytes_tabtrans, b'o')) 以上实例输出结果: b'RUNB'
38、upper()
将字符串中的小写字母转为大写字母。
语法
upper()方法语法:
str.upper()
参数
NA。
返回值
返回小写字母转为大写字母的字符串。
str = "this is string example from runoob....wow!!!";
print ("str.upper() : ", str.upper())
以上实例输出结果如下:
str.upper() : THIS IS STRING EXAMPLE FROM RUNOOB....WOW!!!
39、zfill()
返回指定长度的字符串,原字符串右对齐,前面填充0。
语法
zfill()方法语法:
str.zfill(width)
参数
width -- 指定字符串的长度。原字符串右对齐,前面填充0。
返回值
返回指定长度的字符串。
print ("str.zfill : ",str.zfill(43))
print ("str.zfill : ",str.zfill(44))
print ("str.zfill : ",str.zfill(45))
print ("str.zfill : ",str.zfill(50))
#输出结果
str.zfill : this is string example from runoob....wow!!!
str.zfill : this is string example from runoob....wow!!!
str.zfill : 0this is string example from runoob....wow!!!
str.zfill : 000000this is string example from runoob....wow!!!
40、isdecimal()
检查字符串是否只包含十进制字符。这种方法只存在于unicode对象。
注意:定义一个十进制字符串,只需要在字符串前添加 'u' 前缀即可。
语法
isdecimal()方法语法:
str.isdecimal()
参数
无
返回值
如果字符串是否只包含十进制字符返回True,否则返回False。
str = "runoob2016" print (str.isdecimal()) str = "23443434" print (str.isdecimal()) 以上实例输出结果如下: False True
推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://hqyman.cn/post/4918.html 非本站原创文章欢迎转载,原创文章需保留本站地址!

 微信支付宝扫一扫,打赏作者吧~
微信支付宝扫一扫,打赏作者吧~休息一下~~