
高可用指标
有多种方法可以提高可用性。最优雅的解决方案是重写您的软件,以便您可以同时在多个主机上运行它。软件本身需要有一种方法来检测错误并进行故障转移。如果您只想提供只读网页,那么这相对简单。但是,这通常很复杂,有时甚至是不可能的,因为您无法自己修改软件。以下解决方案无需修改软件即可工作:
使用可靠的“服务器”组件
具有相同功能的计算机组件可能具有不同的可靠性数字,具体取决于组件质量。大多数供应商将可靠性更高的组件作为“服务器”组件出售——通常价格更高。
消除单点故障(冗余组件)
使用不间断电源 (UPS)
在主板上使用冗余电源
使用 ECC-RAM
使用冗余网络硬件
使用 RAID 进行本地存储
为 VM 数据使用分布式冗余存储
减少停机时间
可快速响应的管理人员 (24/7)
备件的可用性(Proxmox VE 集群中的其他节点)
自动错误检测(由ha-manager 提供)
自动故障转移(由ha-manager 提供)
Proxmox VE 等虚拟化环境可以更轻松地实现高可用性,因为它们消除了“硬件”依赖性。它们还支持冗余存储和网络设备的设置和使用,因此如果一台主机出现故障,您只需在集群内的另一台主机上启动这些服务即可。
更好的是,Proxmox VE 提供了一个名为ha-manager的软件堆栈,它可以自动为您执行此操作。它能够自动检测错误并进行自动故障转移。
Proxmox VE ha-manager 的工作方式类似于“自动化”管理员。首先,您配置它应该管理哪些资源(VM、容器等)。然后,ha-manager观察正确的功能,并在出现错误时将服务故障转移到另一个节点。ha-manager还可以处理可能启动、停止、重新定位和迁移服务的普通用户请求。
但是高可用性是有代价的。高质量的组件更昂贵,并且使它们冗余至少会使成本增加一倍。额外的备件进一步增加了成本。所以你应该仔细计算收益,并与那些额外的成本进行比较。
高可用要求
在开始使用 HA 之前,您必须满足以下要求:
至少三个集群节点(以获得可靠的仲裁)
虚拟机和容器的共享存储
硬件冗余(无处不在)
使用可靠的“服务器”组件
硬件看门狗 - 如果不可用,我们回退到 linux 内核软件看门狗(softdog)
可选的硬件防护设备
其他注意事项
HA 堆栈完全异步工作,需要与其他集群成员通信。因此,您需要几秒钟才能看到操作结果。
为了提供 HA,每个节点上运行两个守护进程:
pve-ha-lrm
本地资源管理器 (LRM),它控制在本地节点上运行的服务。它从当前管理器状态文件中读取其服务的请求状态并执行相应的命令。
pve-ha-crm
集群资源管理器 (CRM),它进行集群范围的决策。它向 LRM 发送命令,处理结果,并在出现故障时将资源移动到其他节点。CRM 还处理节点防护。
[ 锁定 LRM 和 CRM ]
锁由我们的分布式配置文件系统 (pmxcfs) 提供。它们用于保证每个 LRM 激活一次并正常工作。由于 LRM 仅在持有锁时才执行操作,因此如果我们可以获取其锁,我们可以将故障节点标记为已防护。这让我们可以安全地恢复任何失败的 HA 服务,而不受现在未知的失败节点的任何干扰。这一切都由当前持有经理主锁的 CRM 监督。
[ 最大并发工作数调整技巧 ]
最多 4 个并发工作数的默认值可能不适合特定设置。例如,可能同时发生 4 个实时迁移,这可能会导致网络拥塞,并且网络速度较慢和/或大(内存方面)服务。此外,确保在最坏的情况下,拥塞最小,即使这意味着降低max_worker值。相反,如果您有一个特别强大的高端设置,您可能还想增加它。
在节点故障时,CRM 将服务分发到其余节点。这会增加这些节点上的服务数量,并可能导致高负载,尤其是在小型集群上。请设计您的集群,使其能够处理这种最坏的情况。
在关机时的迁移过程中,看门狗仍然处于活动状态。如果节点失去法定人数,它将被隔离并且服务将被恢复。
现在的硬件具有大量内存 (RAM)。所以我们停止所有资源,然后重新启动它们以避免所有 RAM 在线迁移。如果要使用在线迁移,则需要在关闭节点之前手动调用它。
请不要 kill 掉服务 pve-ha-crm,pve-ha-lrm 或 watchdog-mux。他们管理和使用 watchdog,因此这会导致节点立即重新启动甚至重置。
============================================================================================================
这里建了一个虚拟机centos7-1使用的是ceph分布式存储,具备虚拟机热迁移的条件,首先实现一下虚拟机热迁移,然后再模拟虚拟机所在物理机故障的情况下,虚拟机自动迁移是否能够实现。
热迁移测试
如下图,虚拟机从pve-1主机迁移到pve-2主机:
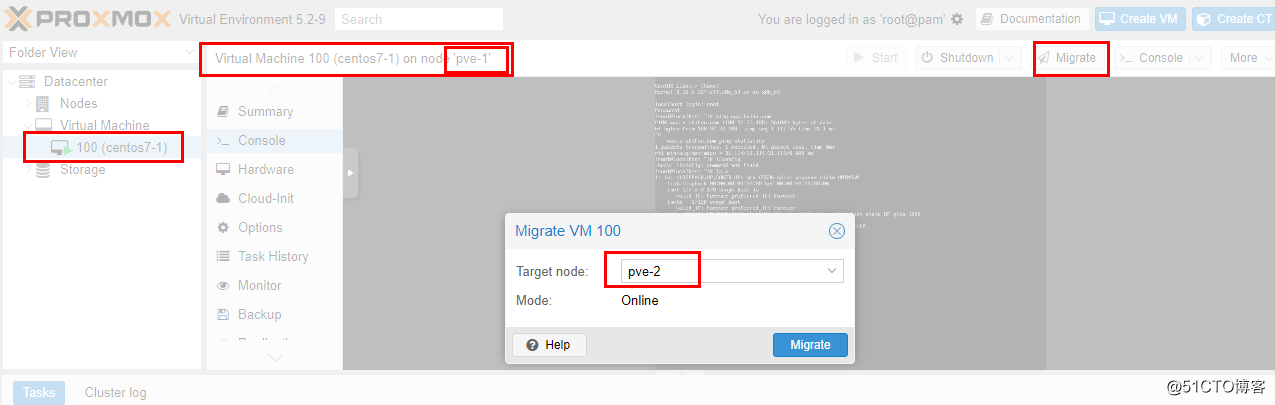
经过大概20秒钟左右,迁移完成,如下图:

虚拟机HA测试
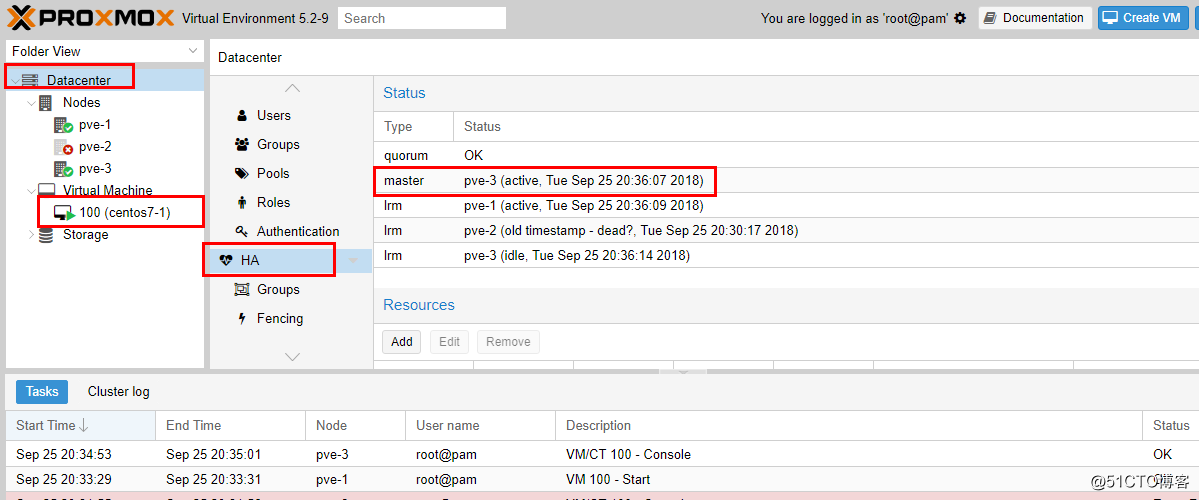
接下来将这个虚拟机加入HA,如下图:


模拟物理机故障,将pve-2强制stop,如下图:

大概过了4分钟左右,加入HA的虚拟机在另一台主机pve-3中自动启动了,如下图:
推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://hqyman.cn/post/5027.html 非本站原创文章欢迎转载,原创文章需保留本站地址!

 微信支付宝扫一扫,打赏作者吧~
微信支付宝扫一扫,打赏作者吧~休息一下~~