实验要求
本试验要求基于第一次实验中访问某官网主页时所抓取到的数据包,用Python 3语言、Jupyter Notebook和Pyshark编写代码进行协议分析所需的开发环境,编写代码,以输出的方式列出首页以及其所包含的所有资源(至少包含如下类型 .html, .js, .css, .jpg, .jpeg, .png, .gif中每一类的所有资源)的URL。
实验内容
- 一、下载安装Anaconda3、Wireshark、Git Bash
由于下载步骤过于简单,这里不再赘述。自行百度。
- 1、wireshark环境配置
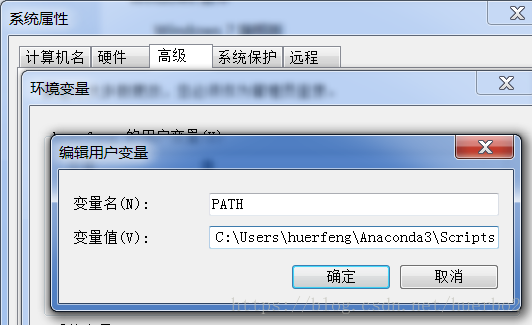
将wireshark相关的程序所在的目录的绝对路径(比如c:\Program Files\Wireshark\)配置于系统的PATH环境变量里。
- 2、Python(Anaconda)环境变量配置
为使Python能在任何目录下的cmd进行调用运行程序,需要在Anaconda3安装的过程中勾选如下选项
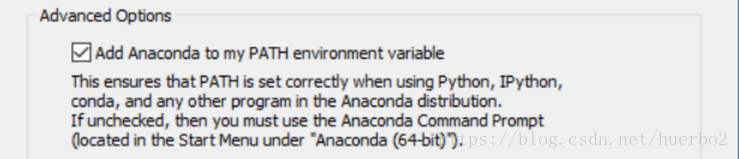
将Anaconda添加到系统环境变量中去。如果忘记勾选可以在计算机->右键属性->高级系统设置->环境变量->path,将anaconda的安装目录添加到path中去。
在开始菜单里找到 Anaconda3 ,点击 Anaconda Prompt ,然后在出来的cmd命令行窗口里输入下列命令并回车:python -m pip install -U pip

由于在很早之前就已经更新过,所以上图显示已经更新。
四、检出代码
1、运行git bash,用cd命令切换到D盘(前提是你系统有D盘),mkdir src创建src目录,用cd命令切换到想用来放源代码的目录/d/src里:cd /d/src
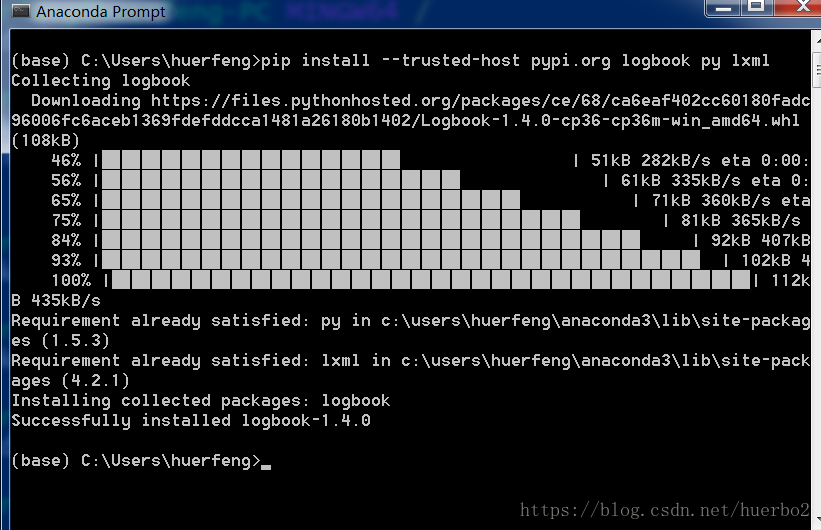
2、切换到anaconda prompt里去手动安装pyshark需要的依赖:pip install –trusted-host pypi.org logbook py lxml
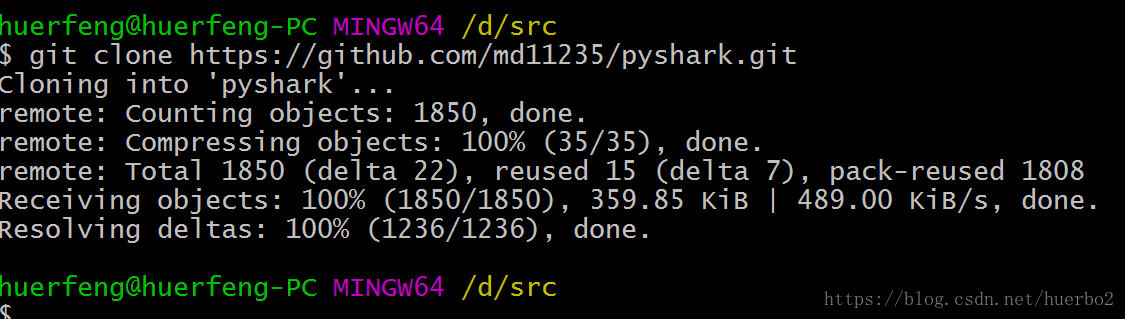
3、回到git bash从github.com克隆(检出)代码
git clone https://github.com/md11235/pyshark.git
五、卸载已有的pyshark,安装从github拿到的代码1、运行anaconda prompt
2、卸载pyshark:pip uninstall pyshark

由于我之前并未安装所以显示直接跳过
3、在anaconda prompt里从检出的源代码安装pyshark,用如下命令切换到d:\src :
d:
cd d:\src\pyshark\src
然后运行 python setup.py install
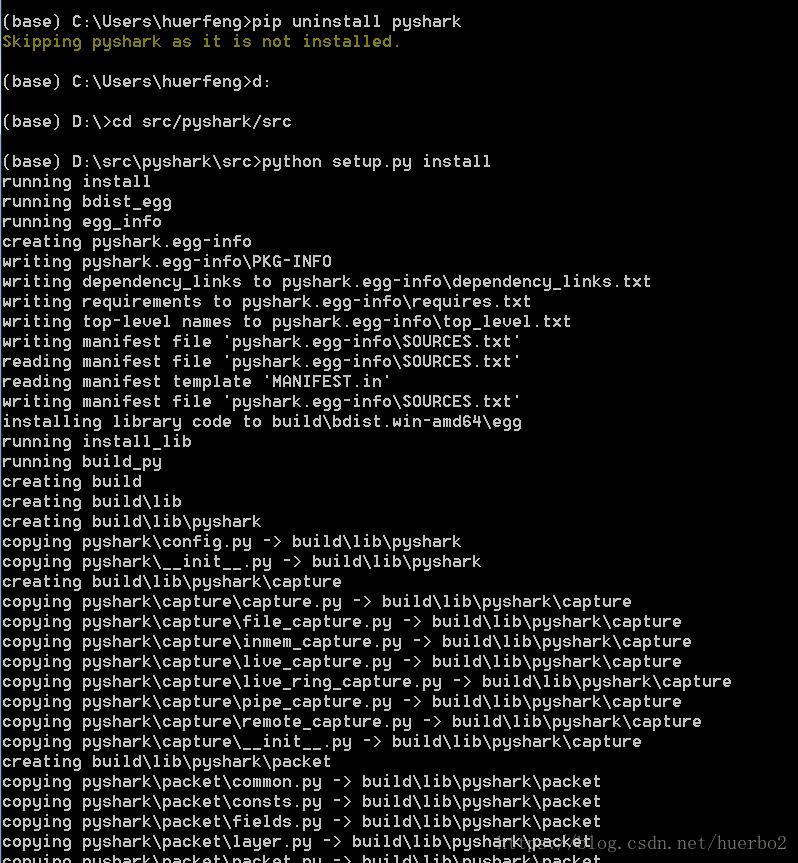
前期工作准备完毕。
代码实现
要想对抓取的数据包进行分析,方式之一就是导入pyshark模块,PyShark的强大在于可以调用tshark内建的所有数据包解码器。利用pyshark提供的FileCapture方法可获得一个Capture 对象。在捕获(capture)和数据包(packet)层面就会有多个方法和属性可用。其中就有一个数据包属性叫做http,再调用其request_full_uri属性就可以获得相应资源的完整URL。
我们先来看下URL构成:模式(或协议)+服务器主机地址(IP地址)+端口+路径+参数。它指向的是某台服务器上资源的超链接。我们都知道每个文件都会有他独有的后缀名来标记他是何种类型的文件。
def getUrlList():
urlList = [] for pkt in cap: try:
url = pkt.http.request_full_uri if (url[len(url) - 1] == "/"):
urlList.append(("html", url))#首页HTML资源,应考虑网站省略的文件部分路径,此处默认为HTML文件资源(其实不一定默认为HTML文件)
else:
urlList.append((url.split(".")[len(url.split(".")) - 1].split("?")[0], url)) except: continue
return urlList所以在上面定义了getUrlList函数,主要功能是获取所有资源URL列表并返回。利用了字符串的分割函数split以“.”来分割,取出其返回的字符串列表中的最后一个便是请求的文件的类型。由于我们不知道到底能够获得多少种资源类型的文件,即使知道,我们也不建议把它写死。然后将获取的文件类型和URL存入列表中返回,以供后面的排序查重使用。
为显示结果,定义了printUrlList函数:
def printUrlList(obj):
i = 1
for tup in obj:
print(i, tup[0], tup[1])
i += 1
运行,调用方式:printUrlList(getUrlList())
程序运行结果部分截图:
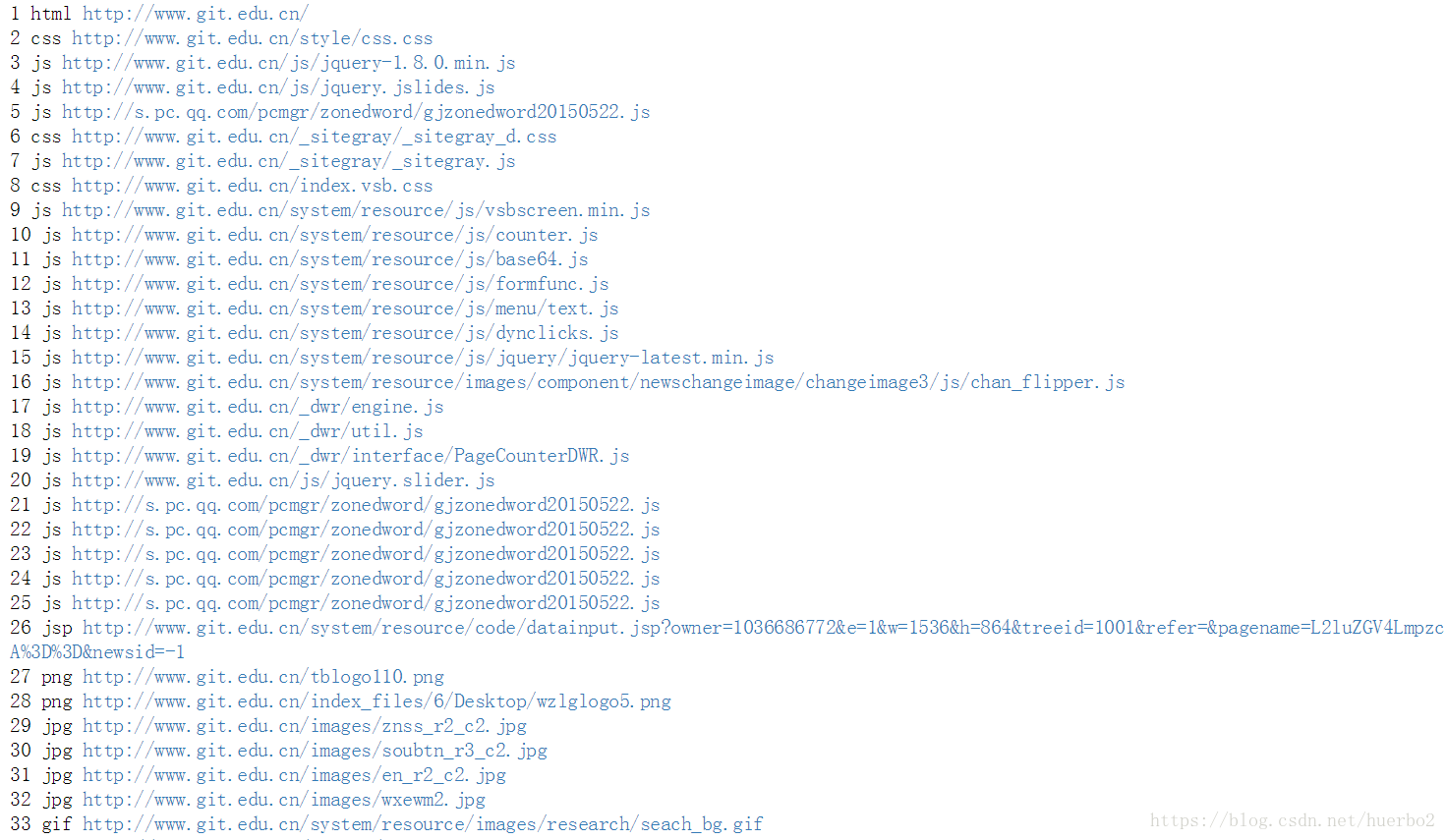
由上面的运行结果可以看出,默认是以请求的时间排序的。个人感觉非常的不爽,非常凌乱,所以想能不能对其进行分类和排个序呢?于是自己写了个函数,以文件的类型来排序。
def sort(obj, isReverse):
if (isReverse):
print("以类型逆序排列") else:
print("以类型顺序排列") return sorted(obj, key=lambda x: x[0], reverse=isReverse)函数有两个参数:obj是要进行排序的元组,isReverse代表是否逆序排列,为True时逆序,False顺序排列。
运行,调用方式:printUrlList(sort(getUrlList(),True))
运行结果部分截图:
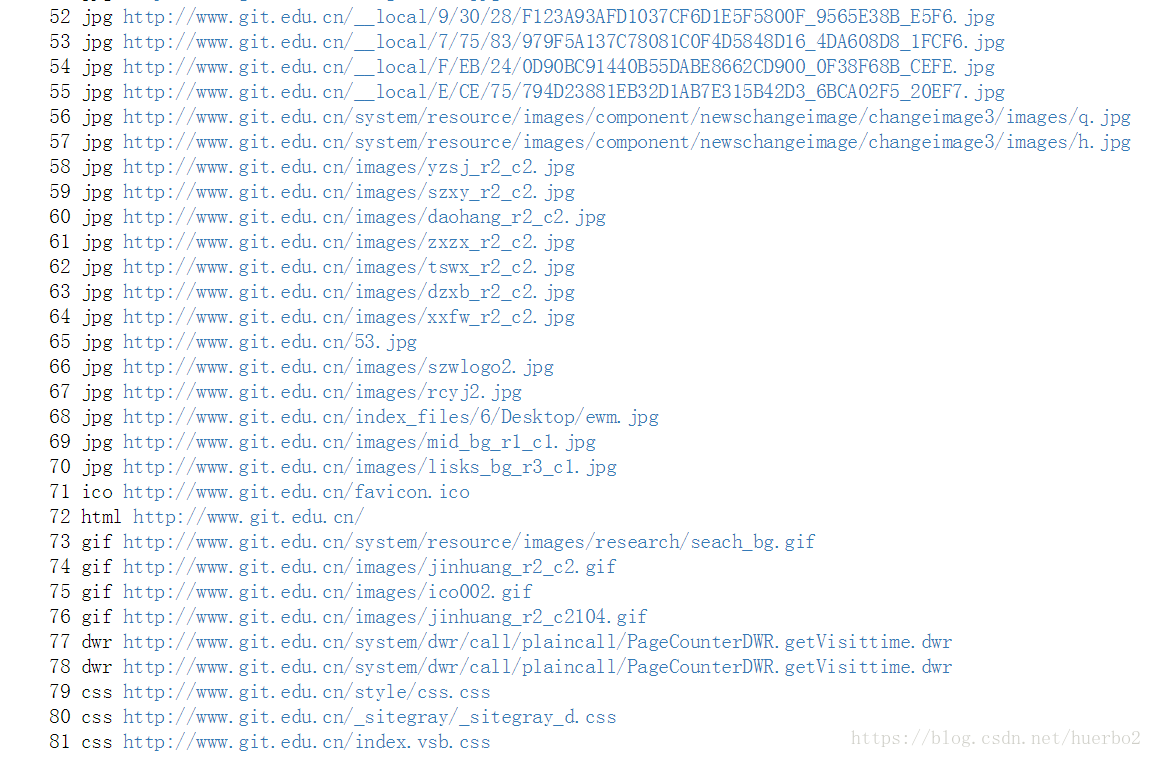
由运行结果可以看出我们在做排序的时候,同时也对其进行了分类。
在上面运行结果中
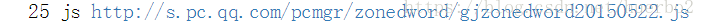

我们发现http://s.pc.qq.com/pcmgr/zonedword/gjzonedword20150522.js出现了多次,这不经意间让我想起,在我们在抓包的时候可能会访问某个网址多次,然而我们在整理资源的时候并不希望出现重复的数据。所以又定义了一个函数对其进行了过滤去重,并对其进行了按类型顺序排列。
def getNoAndRepeatUrl(ls, isReverse):
d = {}
noRepeatUrl = []
repeatUrl = [] for k in ls: if k[1] in d:
d[k[1]] += 1
else:
d[k[1]] = 1
for k in d: if d[k] > 1:
repeatUrl.append(("重复URL:" + str(k), "重复数:" + str(d[k]-1))) if (k[len(k) - 1] == "/"):
noRepeatUrl.append(("html", k)) else:
noRepeatUrl.append((k.split(".")[len(k.split(".")) - 1].split("?")[0], k))
printUrlList(repeatUrl)
print("去重后所有资源URL")
printUrlList(sort(noRepeatUrl, isReverse))函数包含两个参数:ls表示要传入的url列表,函数有两个参数:obj是要进行排序的元组,isReverse代表是否逆序排列,为True时逆序,False顺序排列。
运行,调用方式:getNoAndRepeatUrl(getUrlList(),False)
运行结果部分截图:
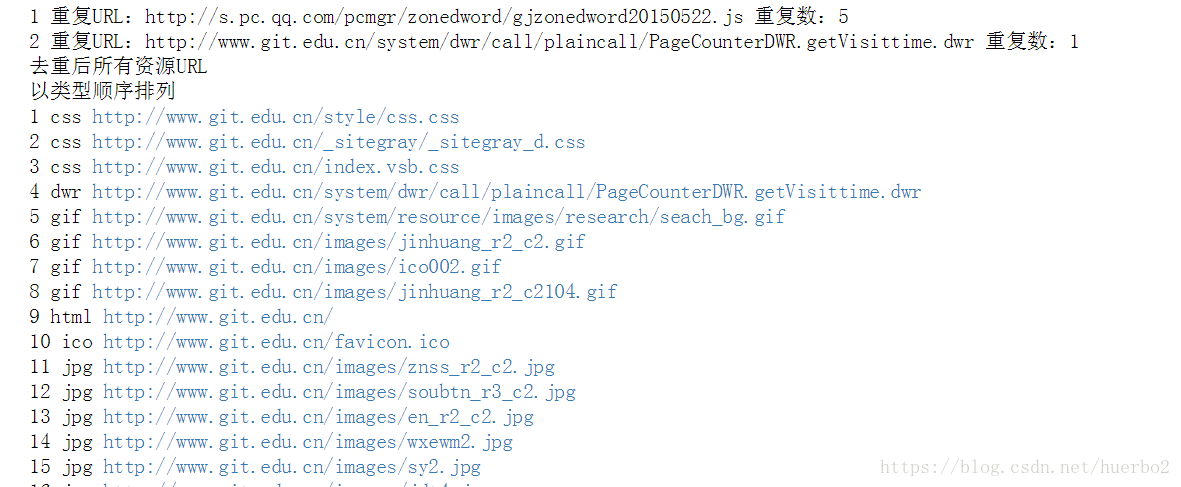
…………………………………………………………………………………………………..
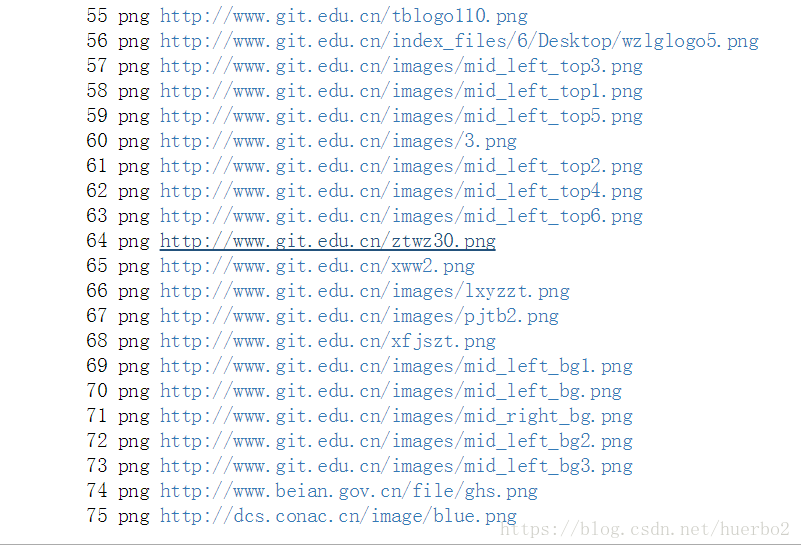
由以上运行结果可以看出http://s.pc.qq.com/pcmgr/zonedword/gjzonedword20150522.js重复了5次,http://www.git.edu.cn/system/dwr/call/plaincall/PageCounterDWR.getVisittime.dwr重复了一次,去重后的总数为75,加上重复的6条刚好等于没去重前的81条。完美!
实验进行到这,我的内心并没有得到满足。我们在管理一大堆事情的时候总期待得到一个统计的结果。
于是三下五除二,手写了个函数
def getAllTypeCount(ls):
d = {} for k in ls: if k[0] in d:
d[k[0]] += 1
else:
d[k[0]] = 1
return d函数只有一个参数ls:需要传入的资源URL列表
运行,调用方式:getAllTypeCount(getUrlList())
运行结果截图:
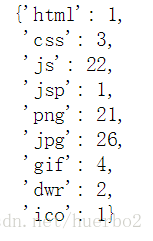
完整代码
import pyshark
cap= pyshark.FileCapture("C:\\Users\\huerfeng\\Desktop\\计算机网络助理任务\\实验一\\la1_data3.pcapng", display_filter="http",tshark_path="D:\\Program Files\\Wireshark\\tshark.exe")def getUrlList():
urlList=[] for pkt in cap: try:
url=pkt.http.request_full_uri if(url[len(url)-1]=="/"):
urlList.append(("html",url)) else:
urlList.append((url.split(".")[len(url.split("."))-1].split("?")[0],url)) except: continue
return urlListdef sort(obj,isReverse):
if(isReverse):
print("以类型逆序排列") else:
print("以类型顺序排列") return sorted(obj,key = lambda x:x[0],reverse = isReverse)def getAllTypeCount(ls):
d={} for k in ls: if k[0] in d:
d[k[0]]+=1
else:
d[k[0]]=1
return ddef getNoAndRepeatUrl(ls,isReverse):
d={}
noRepeatUrl=[]
repeatUrl=[] for k in ls: if k[1] in d:
d[k[1]]+=1
else:
d[k[1]]=1
for k in d: if d[k]>1:
repeatUrl.append(("重复URL:"+str(k),"重复数:"+str(d[k]-1))) if(k[len(k)-1]=="/"):
noRepeatUrl.append(("html",k)) else:
noRepeatUrl.append((k.split(".")[len(k.split("."))-1].split("?")[0],k))
printUrlList(repeatUrl)
print("去重后所有资源URL")
printUrlList(sort(noRepeatUrl,isReverse))def printUrlList(obj):
i=1
for tup in obj:
print(i,tup[0],tup[1])
i+=1 print("所有资源类型数量统计(未去重):",getAllTypeCount(getUrlList()))
print("默认以时间排序")
printUrlList(getUrlList())
printUrlList(sort(getUrlList(),True))
getNoAndRepeatUrl(getUrlList(),False)总结
本文主要涉及了Python列表、元祖、lambda 表达式,pyshark模块的使用,代码较为简单,存在诸多不足,如果你有更好的代码实现和建议,请在下方进行评论,交流。
推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://hqyman.cn/post/5826.html 非本站原创文章欢迎转载,原创文章需保留本站地址!
打赏

微信支付宝扫一扫,打赏作者吧~
休息一下~~
