
性能这个东西,我们可以说是已经测了无数遍了,现在我一直在用iperf3这个工具(我今天学习了一下3个perf:iperf、netperf和qperf),我感觉使用过程中的一些问题要深入理解一下。
首先先打个流。

通过前面的学习(数据中心基准测试术语),我们已经知道最终测得的这个10.9 Gbps一定程度上讲就是这两台主机组成的网络的应用吞吐量,它表明了一定条件下两台主机间的最大可用带宽。
当然,我们的目标是将吞吐量最大化,同时最小化损失。
例如iperf3使用的TCP连接,每个数据包都需要20字节的IP报文头和20字节的TCP报文头,在使用长度为1500字节的标准MTU时,每个数据包有1460字节可用于数据传输。如果是基于Linux操作系统,有效数据将进一步限制为1448字节,因为它们还带有12字节的时间戳。
这一点我们在打流时,可以使用-V命令来查看。
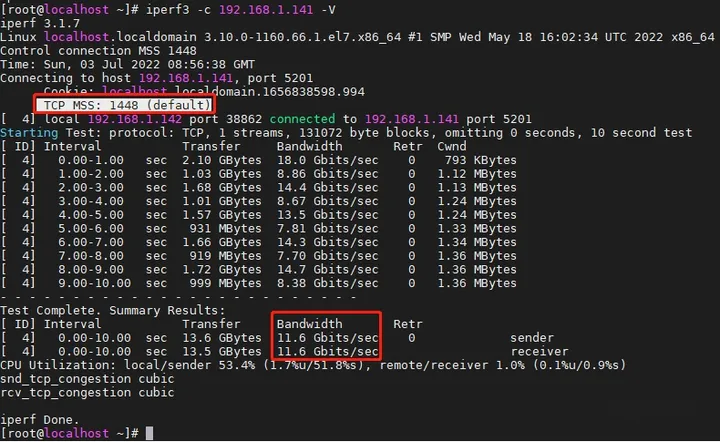
可以看到,默认的TCP MSS大小为1448字节。此时,数据通过以太网传输,每个数据包还要额外增加26字节的数据链路层封装,报文整体长度将增加到1526字节。此时,有效负载占比为1448/1526 = 94.9 %。也就是说,实际的转发能力比11.6 Gbps还要高。
而我们在10 Gbps的链路上通过TCP协议传输文件,最大速率可能只有1448/1526 * 10 = 9.49 Gbps或1.186 GBps。
然后我们测试一下不同TCP分片大小的传输带宽情况。
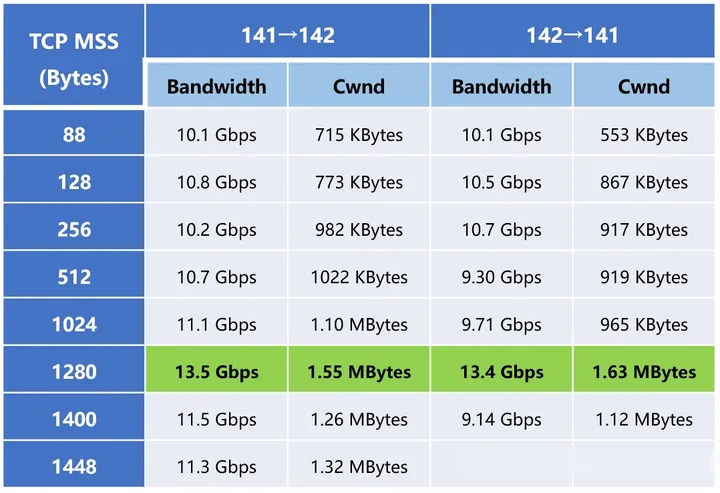
虽然不是很规律,但是我们还是可以看出,随着TCP MSS的增大,传输带宽有所增大,并且在1280字节时达到最大,大约为13.5 Gbps。如果照此计算,最大传输带宽的理论值大概为13.5 Gbps*(1280+20+20+12+26)/1280=14.32 Gbps。
但是,当转发小包时,需要更高的包转发速率,将上表转换为PPS如下所示:
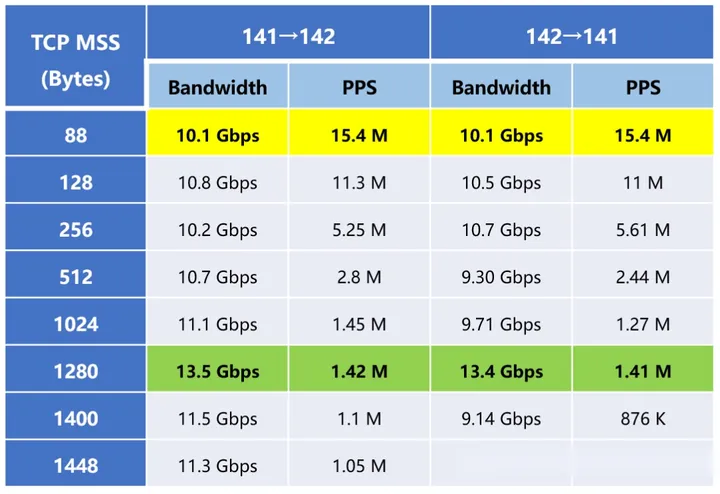
可以看到,最大包转发速率高达15.4 Mpps。
再回顾一下我们在测试数据中心设备时,对“线速”的定义:“线速”或“物理层帧速率”是在DUT的传输时钟频率下发送特定大小的帧的最大容量,常用的端口最大速度能力包括:1 GE、10 GE、40 GE、100 GE等(GE表示为千兆以太网)。
最大传输数据速率由DUT中的“传输时钟”控制,这里提到的“传输时钟”,一般为物理模块,大多数以太网交换机使用密封的、内部温度补偿的、非常精确的“时钟模块”(也称为“振荡器模块”)。这些模块的输出频率是不可调节的,当然,很多测试仪也提供了由软件控制的传输时钟速率调整。
所以,线速似乎更应该以帧速率/每秒帧数 (frames per second,FPS) 来衡量。帧速率=时钟频率/(帧长度*8+最小间隔+前导帧+起始帧间隔)
例如,对于千兆以太网,具有64字节帧长的帧速率为:
1,000,000,000/(64*8+96+56+8)=1,488,095.2 帧/秒。考虑到传输时钟的容差(+/- 100 PPM),交换机可以“合法地”以的1,487,946.4到1,488,244 FPS 之间的帧速率传输流量。所以,在生产网络中,很难在很短的时间内看到精确的线速。以99 %的线速和100 %的线速转发数据包之间没有明显的区别。
VMWare中使用的模拟网络适配器VMXNET3接口,从转发速率来看,应该是没有达到模拟时钟的瓶颈的,所以转发速率有可能可以突破14.32 Gbps。
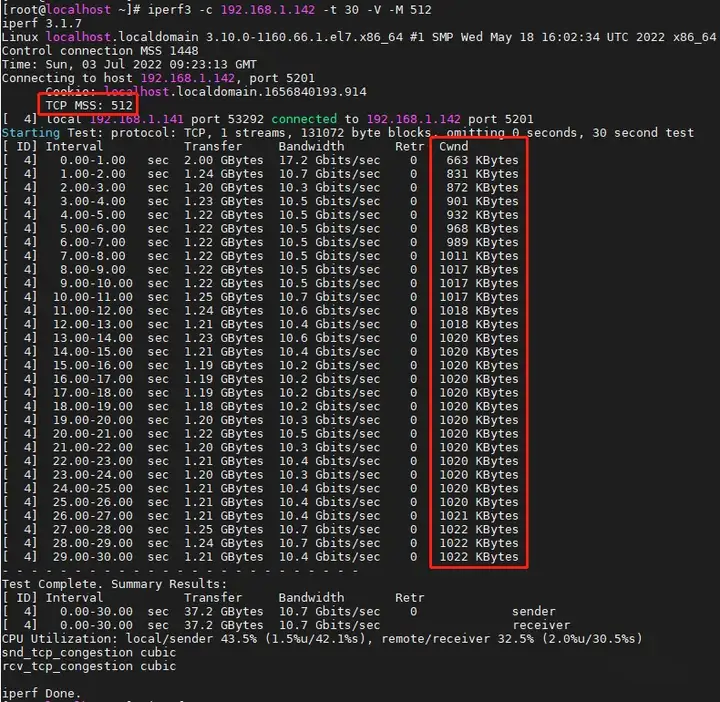
相信大家也注意到了,我在记录数据时还记录了一行Cwnd,在打流时也比较显眼,不同的TCP MSS它能达到的大小是不一样的。以某次打流过程为例,可以看到Cwnd从663 Kbytes一直上涨到1022 Kbytes。
Cwnd就是拥塞窗口(Congestion Window),它是一个TCP状态变量,它可以限制TCP在收到ACK之前可以发送到网络的数据量。对应的,还有一个rwnd(接收窗口,Receiver Window),也是一个变量,用于通告目标端可以接收的数据量。拥塞窗口和接收窗口通过交互ACK来指示成功接收到的最后一个片段之外的可接受序列号的范围,用来指示发送方在接收进一步许可之前可以传输的允许的八位字节数。这样一来,接收方就可以控制发送方发送的数据量,以达到调节TCP连接中的数据流、最小化拥塞和提高网络性能的效果。
我们也可以通过-w参数来指定窗口大小,简单测试一下。
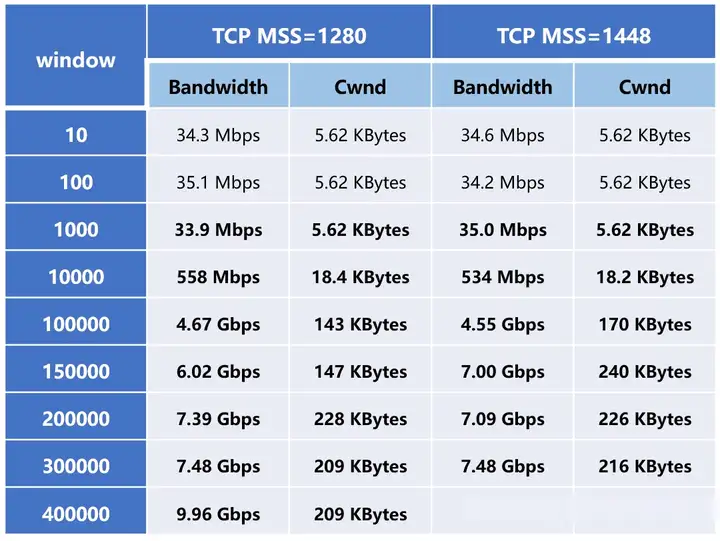
可以看到,当窗口在1000以下时,速率变化不明显;而在1000以上时,速率增长比较明显,而且几乎成线性增长,并在窗口大小为15万-20万时趋于稳定。
当缓冲区在目的地被填满时,数据包在等待转发到上层时临时存储在源和目的地的缓冲区中。这可能导致拥塞并导致数据包丢失、重传、数据吞吐量降低、性能下降,甚至在极端情况下网络崩溃。这时,我们就要关注Retr这个参数了,Retr代表重传,证明网络中可能出现了数据包丢失。
在实际使用中,使用较大的分片可能会实现更好的性能,避免小窗口的建议是让接收方推迟更新窗口,直到附加分配达到连接可能的一定比例(如20%到40%)。另一个建议是发送方通过等待窗口足够大再发送数据来避免发送小分片报文,如果用户发出推送功能的信号,那么即使是小分片报文也必须发送数据。必要时,要积极尝试将小窗口分配组合到更大的窗口中,因为在最简单的实现中管理窗口的机制往往会导致许多小窗口。
然后我们结合-P测一下在30个并发时,分片大小为1280,TCP传输窗口为10万时的转发性能。
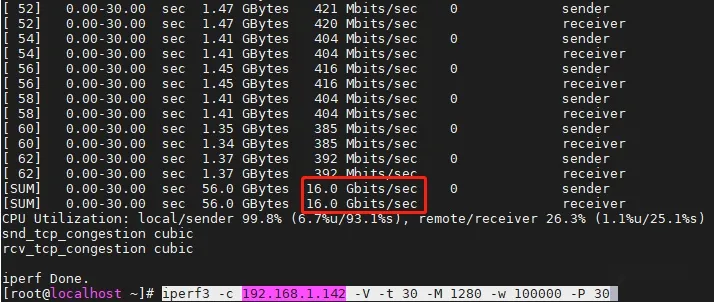
OK,终于到16 Gbps了。
总结一下,在后面的测试中,我们将通过-M来对报文进行分片,通过大包来测试应用吞吐带宽,通过小包来测试包转发速率PPS。
推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://hqyman.cn/post/6491.html 非本站原创文章欢迎转载,原创文章需保留本站地址!

 微信支付宝扫一扫,打赏作者吧~
微信支付宝扫一扫,打赏作者吧~休息一下~~