

测得带宽为3.72 Gbps,转换为包转发速率为381 Kpps。相比于1C1G的3.62 Gbps和370.7 Kpps,稍微搞了一丢丢,白瞎了多出来的3C3G。
通过查阅资料,我们发现VPP可以在单线程和多线程两种不同的模式下工作。
而且,VPP默认还是工作在单线程模式下,此时,只有一个主线程负责数据包处理和转发,还要执行其他管理任务,如调试命令行界面(Command-Line Interface,CLI)、响应API调用或收集统计信息等,此时其他外部因素可能会影响转发性能。
所以,我们需要考虑使用带有工作线程的多线程模式,在这种模式下,主线程负责管理任务,其他一个或多个工作线程负责从数据包输入到输出的处理工作。每个工作线程通过轮询接口子集上的输入队列来进行负载,如果启用RSS(Receive Side Scaling,接收端缩放),还可以配置多个工作线程共同为一个物理接口提供服务,以在不同队列之间负载流量。
因此,即使单个CPU核心可以达到所需的性能目标,仍然推荐以“一个主线程加一个工作线程”的配置运行VPP,这将有助于减轻外部因素可能产生的影响,并允许一个工作线程交付更好和更一致的转发性能。
在配置文件/etc/vpp/startup.conf中,unix、dpdk和cpu属于基本配置参数。我们可以通过优化CPU部分的配置来分配线程、控制命名线程类型的创建及其CPU亲和性。
我们首先使用VPP调试命令显示线程来查看当前的内核分配情况。

Socket 0表示CPU插槽0,Core 0表示第0个核心,即表示VPP的主线程vpp_main运行在核心0上。
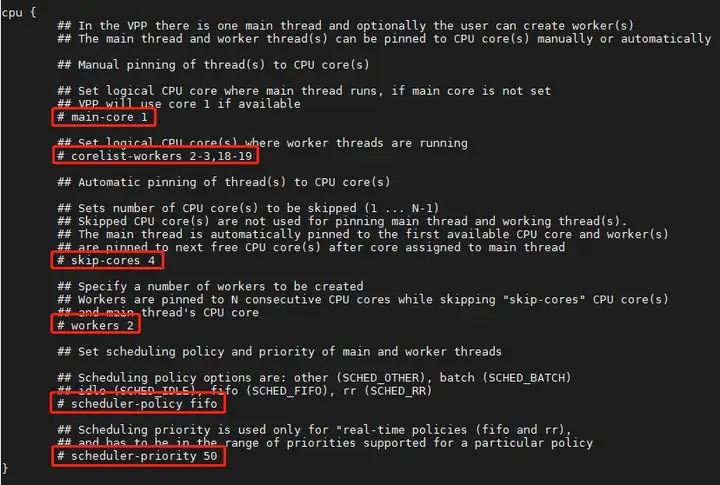
在配置文件/etc/vpp/startup.conf中,CPU的示例配置主要包含6条:
main-core 1
# 如果定义了“main-core X”,则VPP主线程将分配在第X个核心上,否则将使用第一个可用的核心。
corelist-workers 2-3,18-19
# 如果定义了“corelist-workers A,B1-Bn,C1-Cn”,VPP将自动将这些CPU核心分配作为工作线程。
skip-cores 4
# 如果定义了“skip-cores X”,则不会使用第X个核心。
workers 2
# 如果定义了“workers N”,VPP将分配前N个可用核心,并将它们作为工作线程。
scheduler-policy fifo
# 调度策略支持rr、fifo、batch、idle和other。
scheduler-priority 50
# 当“scheduler-policy”设置为“fifo”或“rr”时,可以设置调度程序优先级。取值范围通常为1到99。
简单调整一下,我们将VPP主线程将分配在第0个核心上,同时指定工作线程数量为3。
cpu { main-core 0 workers 3}
我们再使用VPP调试命令显示线程来查看当前的内核分配情况。

可以看到,VPP的主线程vpp_main运行在核心0上,另外的类型为workers的工作线程分别运行在核心1-3上。
然后我们再来打流测试一下。
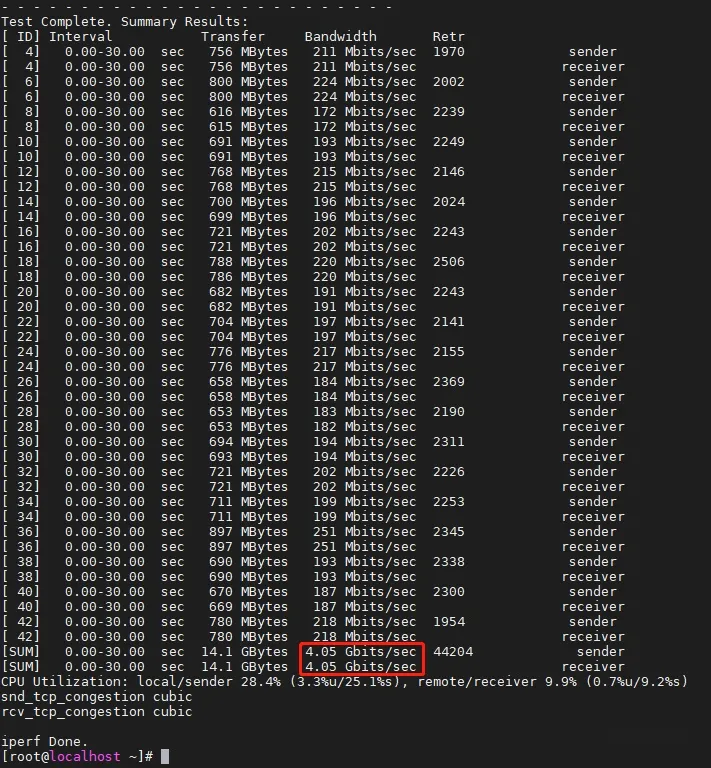
一顿操作猛如虎,一看战绩零杠五。才到4.05 Gbps,有点失望啊。相比于1C1G,提升幅度12%;比优化前提升8.9%。
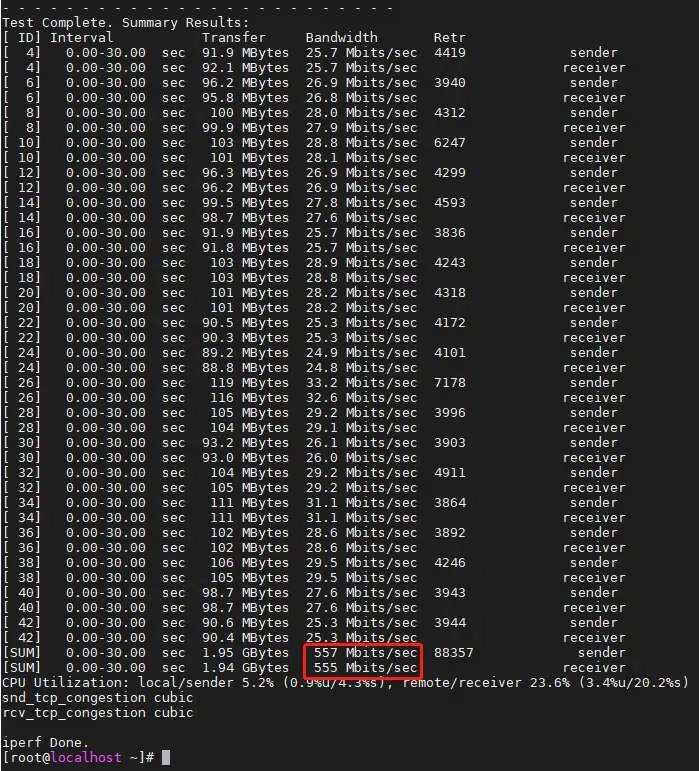
用小包试试,得到带宽为555 Mbps,转换为包转发速率为555 Kpps。相比于1C1G,提升幅度7.5%。
看配置说明,VPP平台支持NUMA(Non Uniform Memory Access,非统一内存访问),它可以为不同CPU套接字(NUMA节点)上的缓冲区分配内存。通过在dpdk { }部分中配置socket-mem语句,可以为每个CPU插槽定义分配的内存量。
但是,如果使用的是新版本的VPP,则无需手动指定socket-mem。VPP将发现所有NUMA节点,默认情况下会在每个节点上分配512M。只有在需要更大数量的mbufs时才需要socket-mem(默认为每个套接字16384,可以使用num-mbufs启动配置命令进行更改)。
VPP可以自动挂载/卸载大页面文件系统,因此无需手动执行此操作。如果条件允许,VPP更喜欢1G的大页面。如果条件不允许,VPP将使用2MB的小页面。那我们测试手工配置一下2 GB内存。
dpdk { socket-mem 2048,2048,2048,2048,2048,2048 dev 0000:13:00.0 { name eth1 } dev 0000:1b:00.0 { name eth2 }}
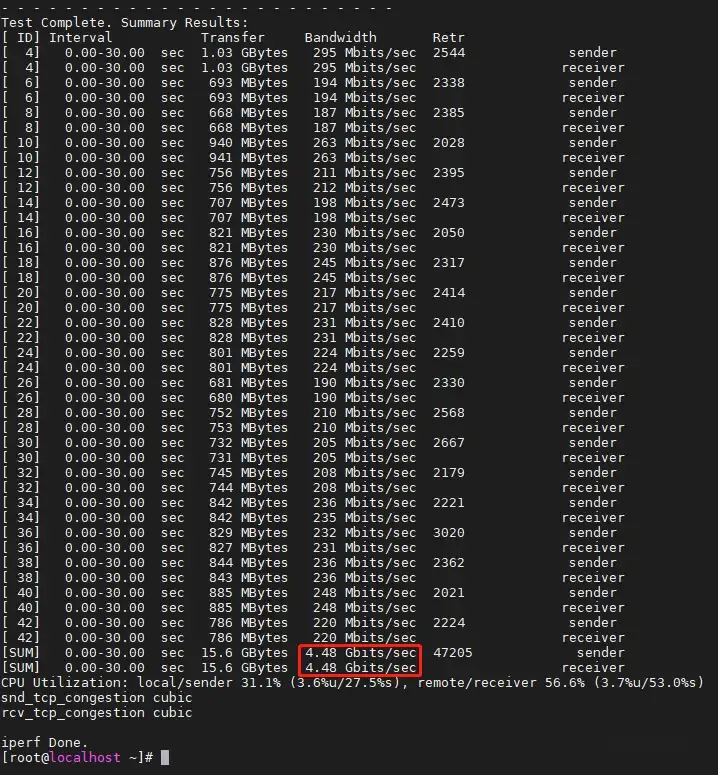
应该是有点效果,现在性能提升到了4.48 Gbps。
我想,这大概就是我们做到的最高水平了,从3.72 Gbps到4.48 Gbps,提升大概20.4%,用4倍的配置来实现20%的涨幅,好像有点说不过去。
我们把配置减到2C4G再测试一下。
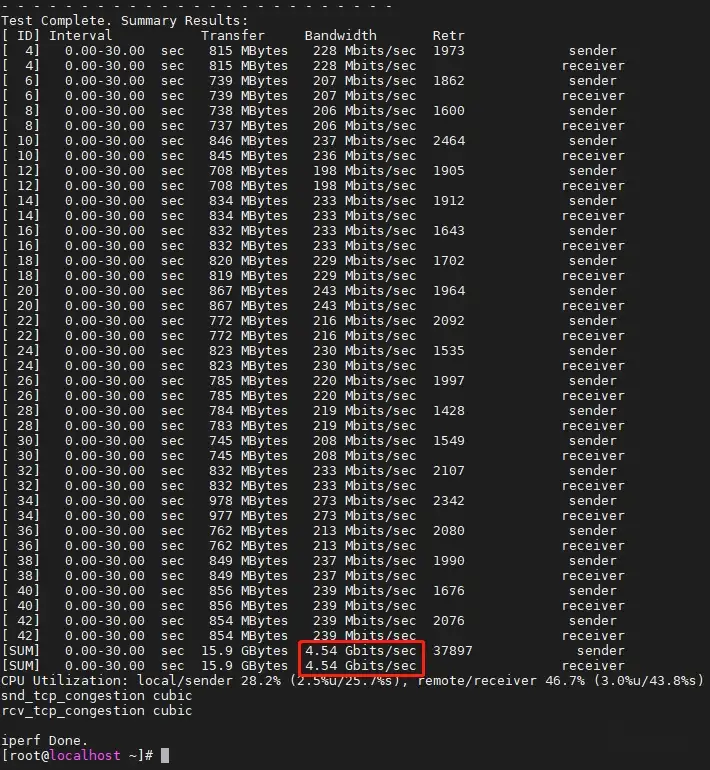
降本增效啊!现在性能都到了4.54 Gbps,比3.72 Gbps高了大概22 %。
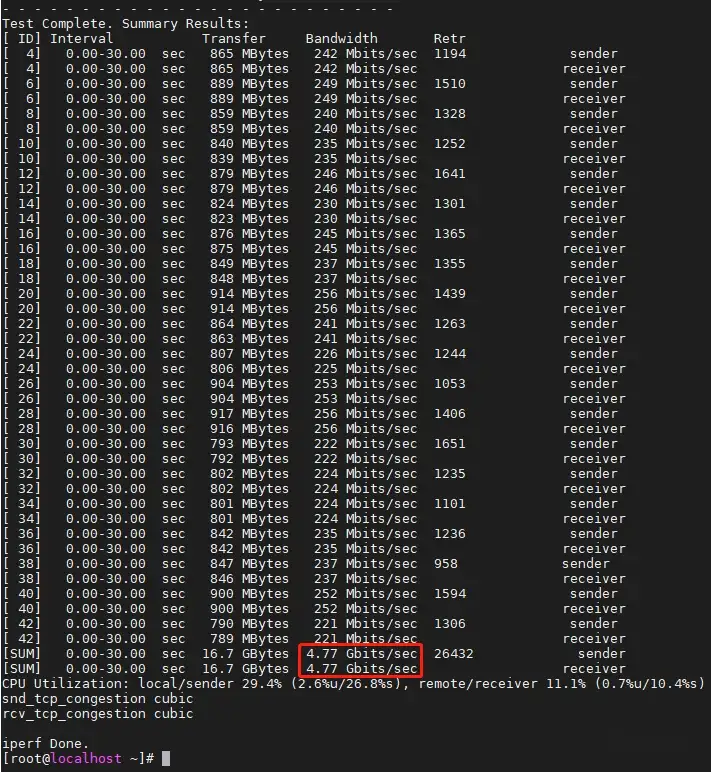
把TCP MSS修改为1300,性能达到4.77 Gbps,折合481 Kpps。
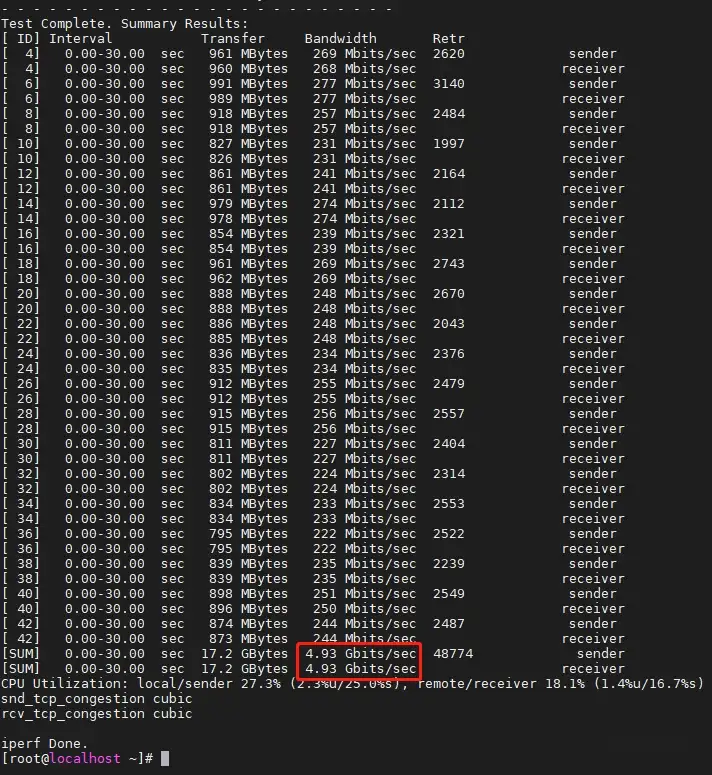
把TCP MSS修改为1350,性能达到4.93 Gbps,折合478.7 Kpps。
差一点不到5 Gbps。算了,毁灭吧,累了!

推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://hqyman.cn/post/6494.html 非本站原创文章欢迎转载,原创文章需保留本站地址!

 微信支付宝扫一扫,打赏作者吧~
微信支付宝扫一扫,打赏作者吧~休息一下~~