
主要记录安装及使用过程中遇到的问题<包含4.4.x, 4.5.x>
设置engine管理页面可以通过IP访问
ssh连接engine服务器并在/etc/ovirt-engine/engine.conf.d新建99-custom-sso-setup.conf,添加engine节点的IP或出口IP
SSO_ALTERNATE_ENGINE_FQDNS="engine103.cluster.local 192.168.5.103 61.x.x.8"
重启engein服务
systemctl restart ovirt-engine
重启服务器后节点的9090端口服务无法访问
解决方法: 登录服务器确认ovirt-ha-agent服务是否启动成功
systemctl status ovirt-ha-agent
添加完集群后节点异常如下,此问题主机是集群内物理服务器硬件不一致引起的
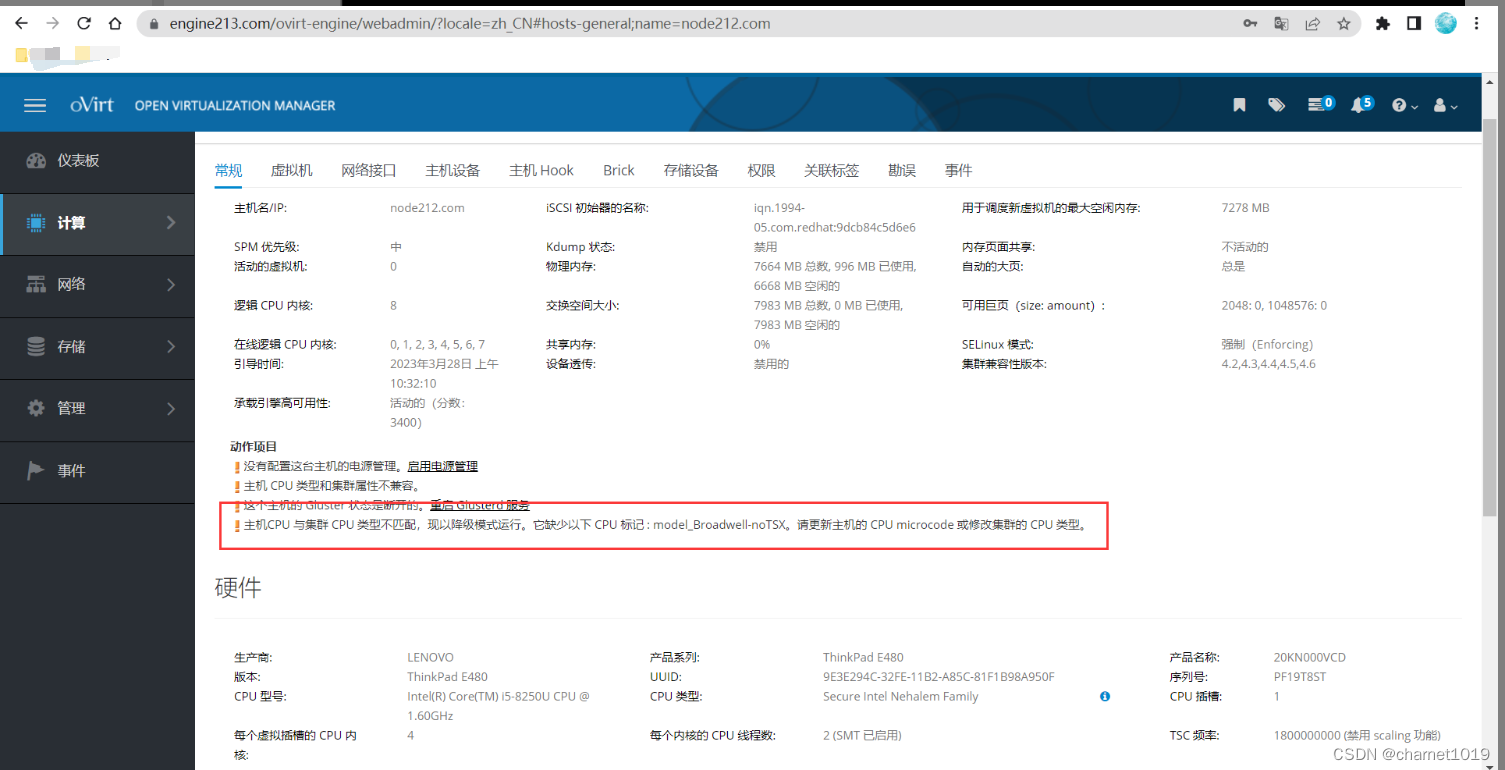
解决方法: 查看异常节点的CPU类型,然后将集群的CPU类型修改为异常节点CPU类型,生产环境保证硬件配置一致则没有此问题
这里异常节点node212.com的CPU类型为:Secure Intel Nehalem Family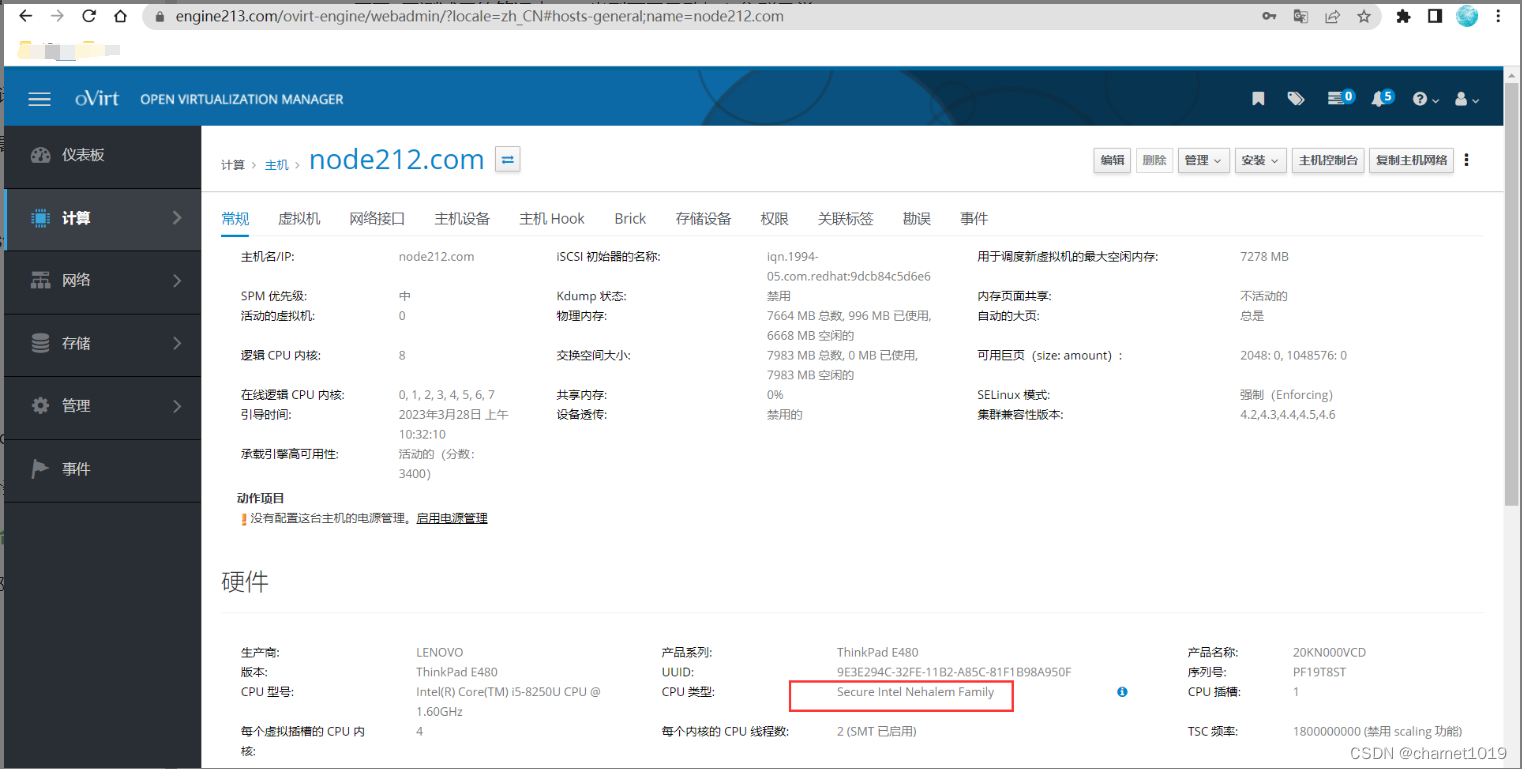
在”计算”->”集群”,选择当前集群后点击”编辑”,将CPU类型修改为Secure Intel Nehalem Family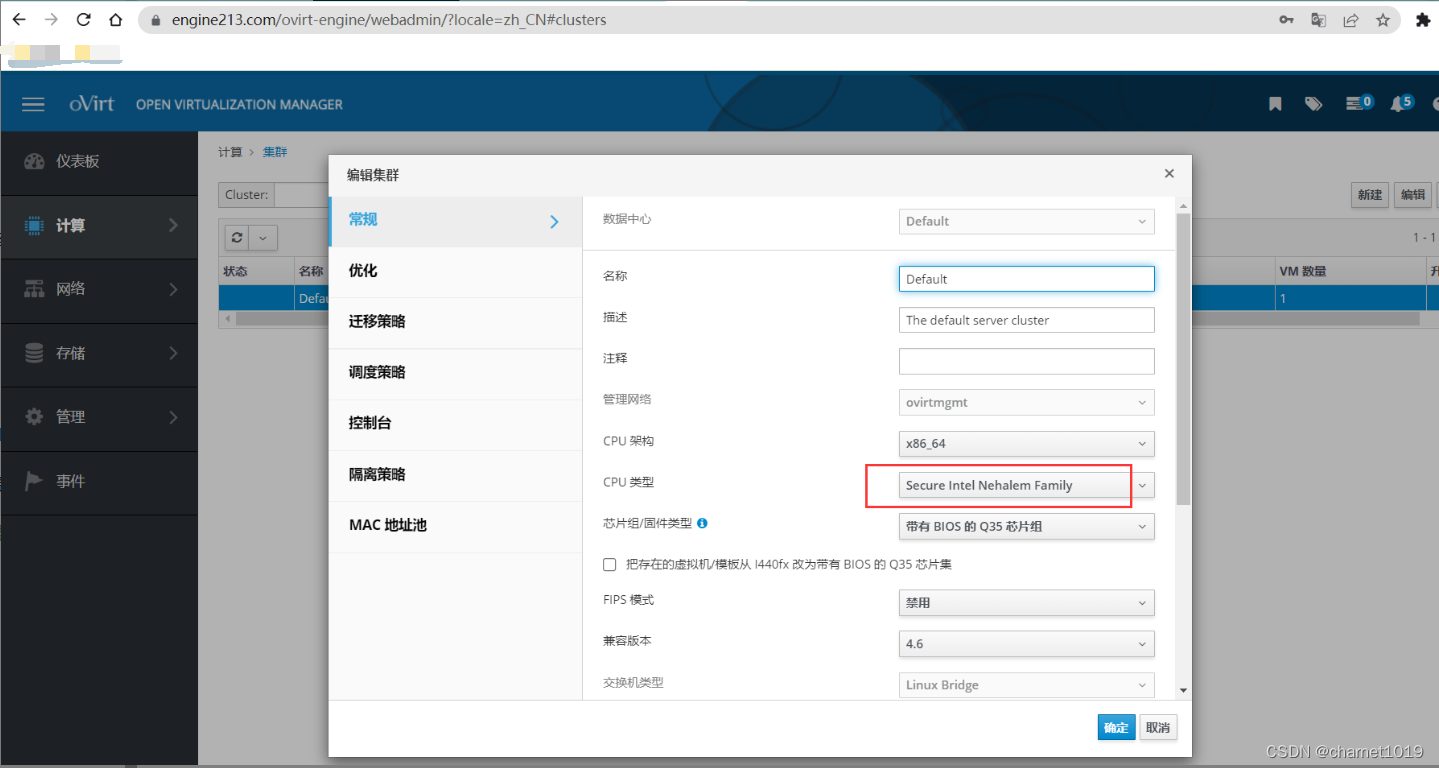
修改完成后自动更新节点信息,以下为正常节点信息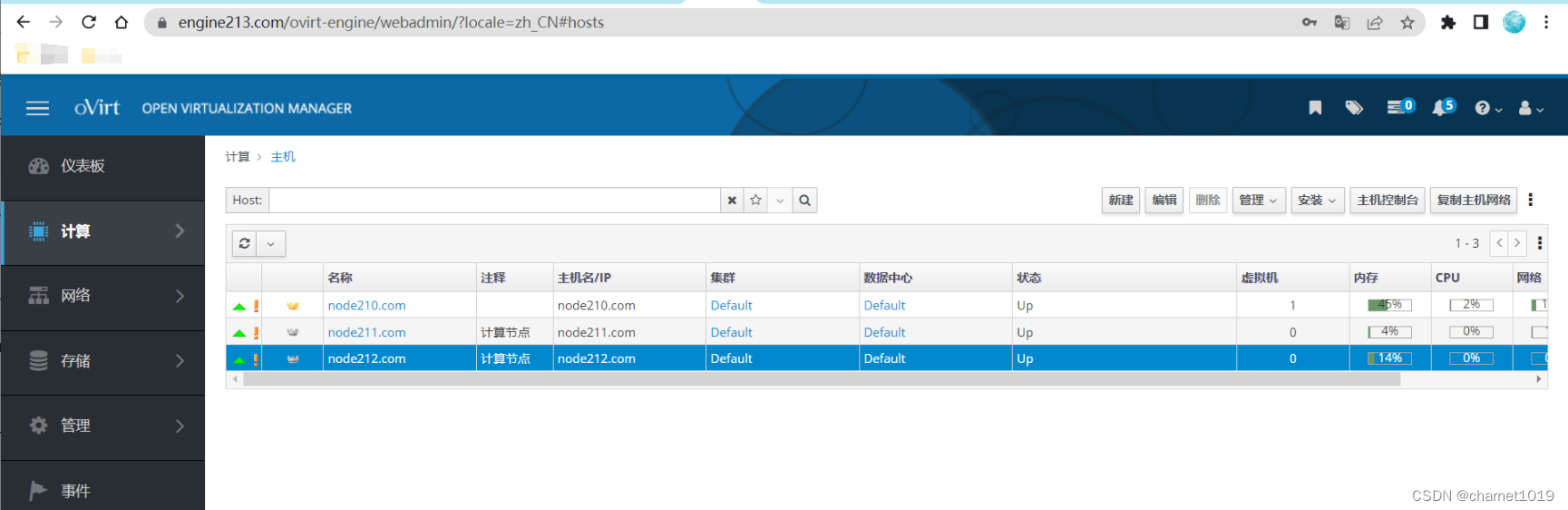
访问cockpit时提示”这个浏览器太老,无法运行 Web 控制台(缺少 selector(:is():where()))”
此问题主要是更新Chrome后引起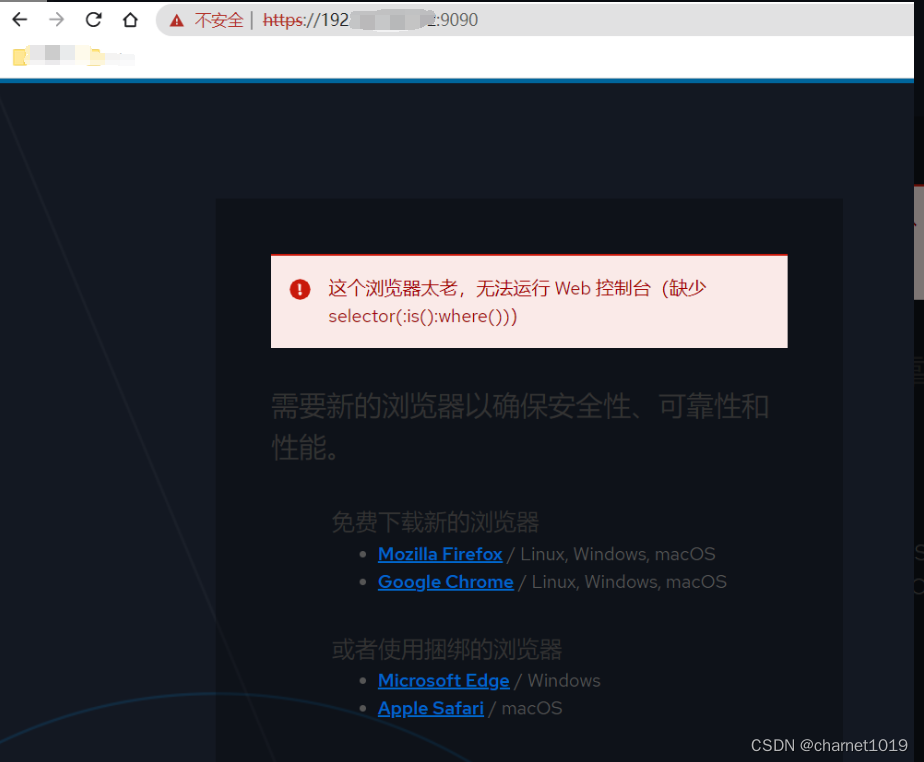
解决方法:
sed 's/selector(:is():where())/selector(:is(*):where(*))/' -i.bak /usr/share/cockpit/static/login.js
重启cockpit服务:
systemctl restart cockpit
出现数据有未同步的问题
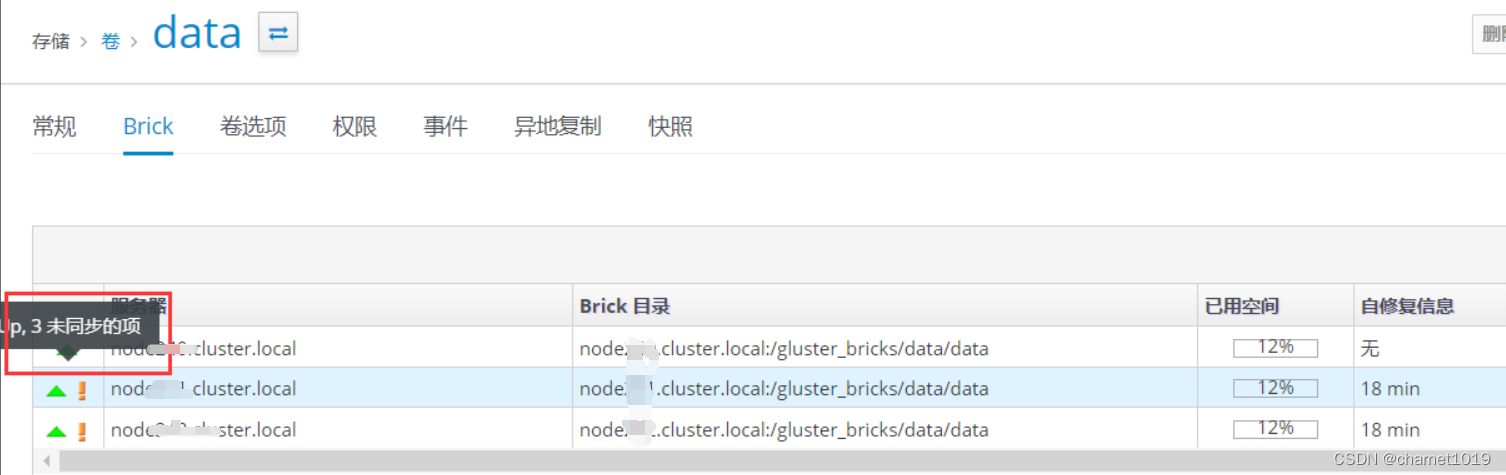
查看对应的gfs卷信息有未连接的节点
[root@node100 ~]# gluster volume heal data infoBrick node100.cluster.local:/gluster_bricks/data/data Status: Transport endpoint is not connected Number of entries: - Brick node101.cluster.local:/gluster_bricks/data/data /3ebbb7ec-6334-4dff-8c84-02868c732d53/dom_md/ids / /.shard/.remove_me Status: Connected Number of entries: 3Brick node102.cluster.local:/gluster_bricks/data/data /3ebbb7ec-6334-4dff-8c84-02868c732d53/dom_md/ids / /.shard/.remove_me Status: Connected Number of entries: 3
解决方法:
尝试在”存储”->”卷”下重启对应的卷
通过命令解决
gluster volume start data force gluster volume heal data full
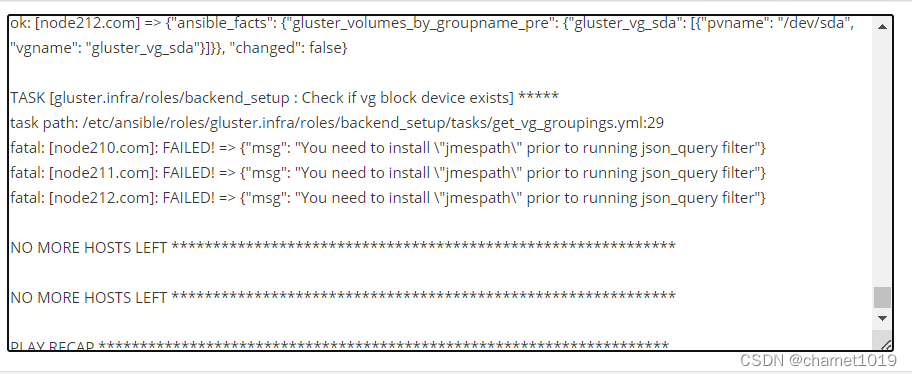
部署gfs时报如下错误
解决方法:
系统更新后python版本发生变化导致找不到jmespath模块,根据实际修改python版本
[root@node210 ~]# python3.11 -m ensurepip --default-pip[root@node210 ~]# python3.11 -m pip install jmespath
安装gfs时报The error was: ‘str object’ has no attribute ‘vgname’
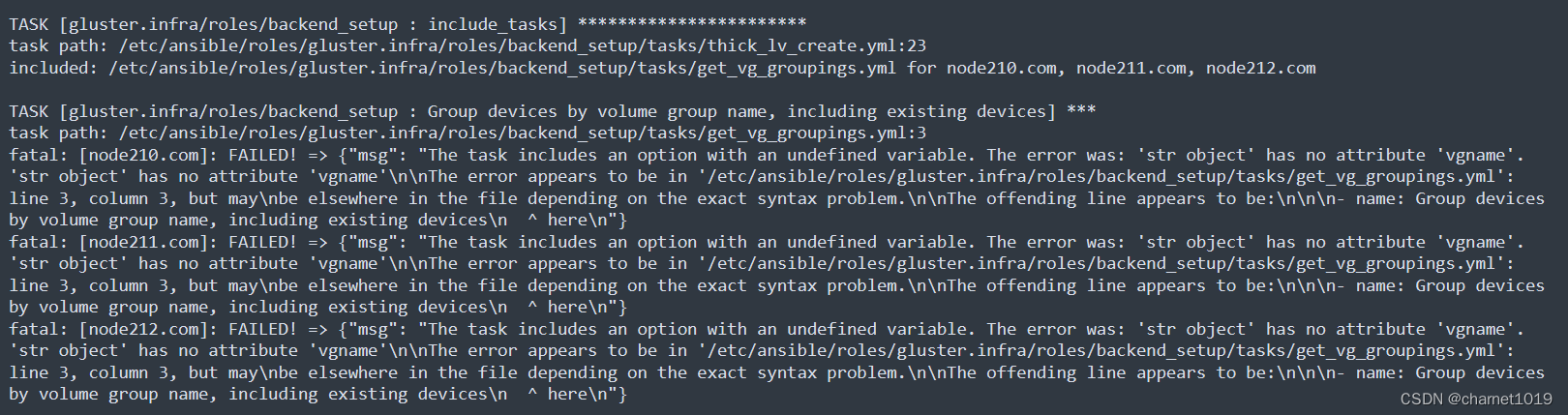
原因: ansible 2.12之前处理json语法问题
解决方法:
[root@node210 ~]# sed -i.bak 's/output | to_json/output/' /etc/ansible/roles/gluster.infra/roles/backend_setup/tasks/get_vg_groupings.yml[root@node210 ~]# sed -i.bak 's/output | to_json/output/' /etc/ansible/roles/gluster.infra/roles/backend_setup/tasks/thick_lv_create.yml[root@node210 ~]# sed -i.bak 's/output | to_json/output/' /etc/ansible/roles/gluster.infra/roles/backend_setup/tasks/thin_pool_create.yml[root@node210 ~]# sed -i.bak 's/output | to_json/output/' /etc/ansible/roles/gluster.infra/roles/backend_setup/tasks/thin_volume_create.yml
重启3个node节点后进入emergency模式
解决方法: 按提示输入root用户密码后编辑/etc/fstab将gfs挂载配置先注释后再重启系统,重启完成后进入系统取消gfs挂载注释
访问每个node节点的后台管理启用逻辑卷并挂载gfs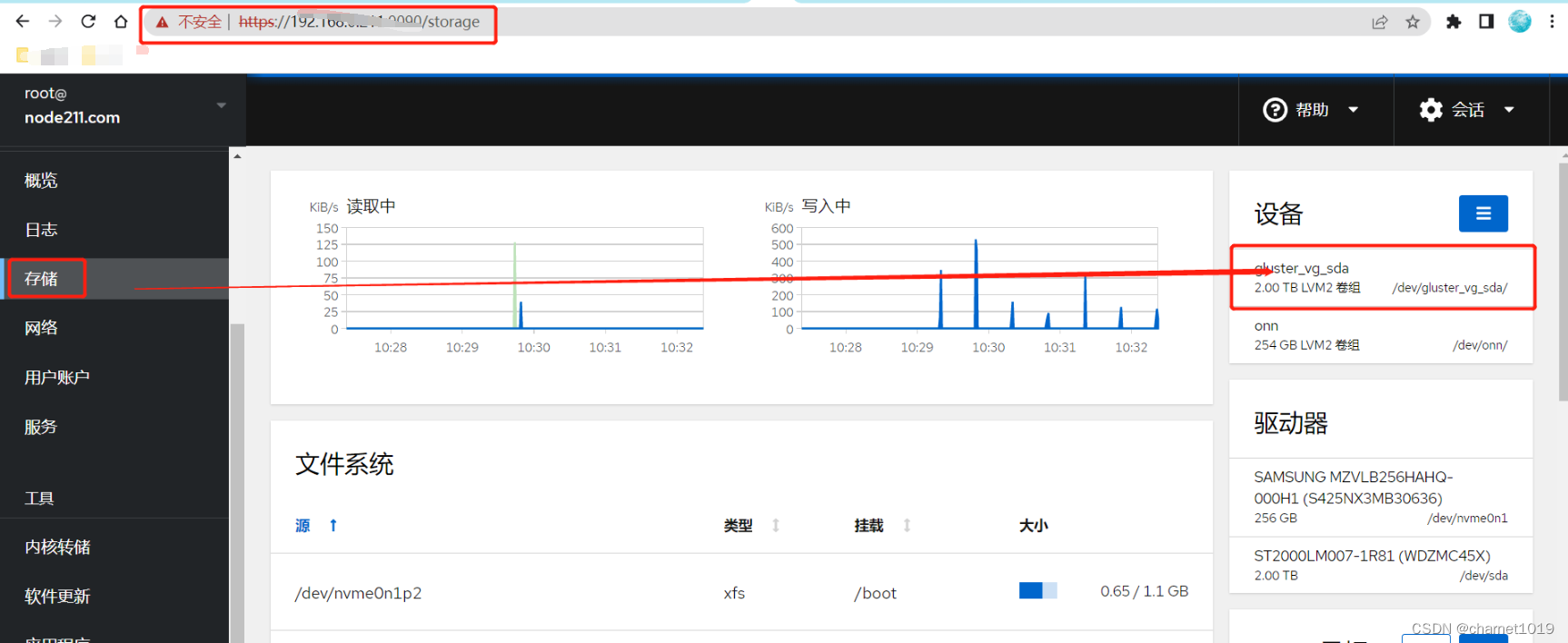
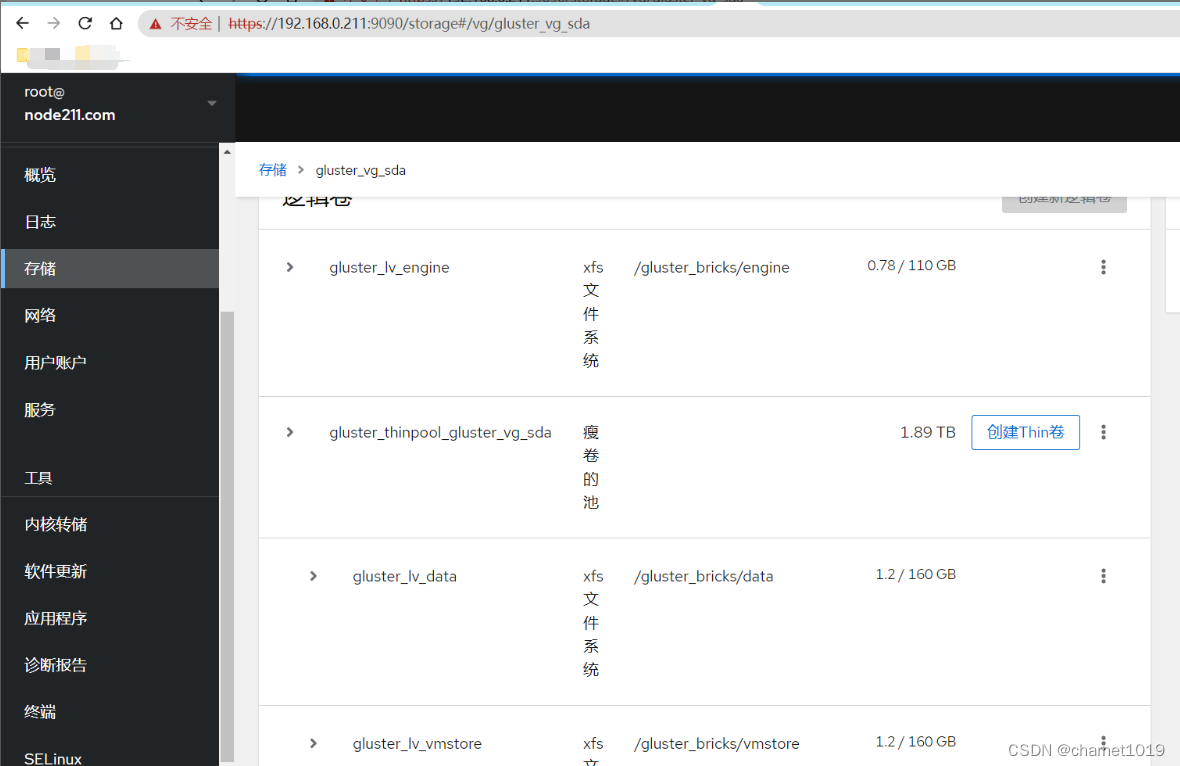
点击”启动逻辑卷”,如果是第一个执行的节点则需要再点击”挂载”,当第一个节点挂载完成后后续其他的节点只需启动逻辑卷即可: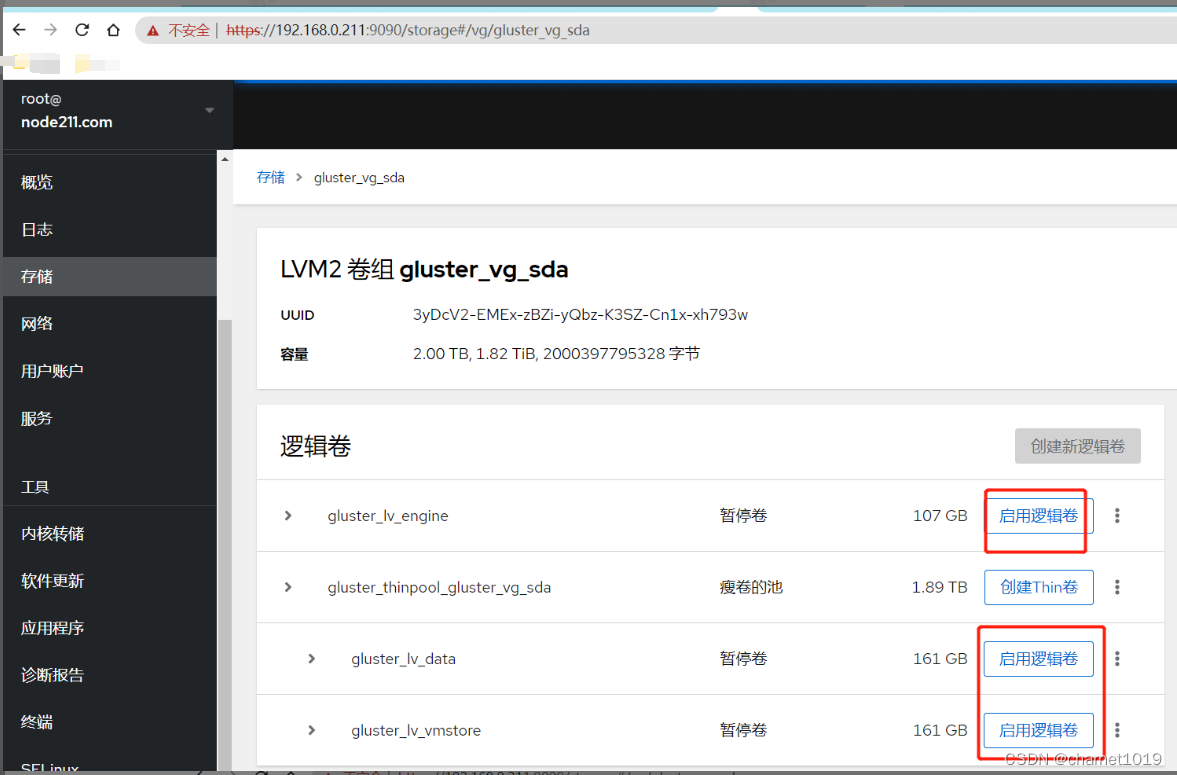
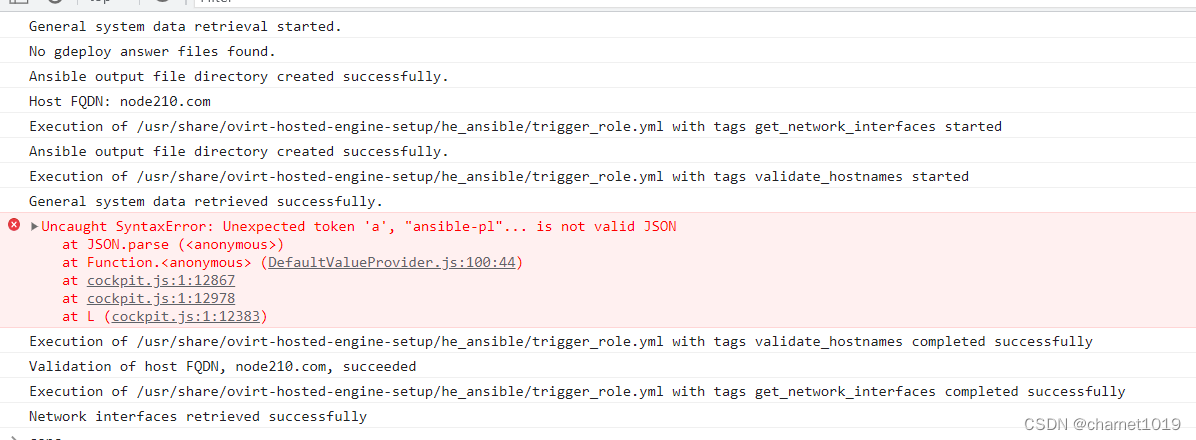
安装engine时报FQDN验证失败,是因检测网络时缺少netaddr库

解决方法:
[root@node210 ~]# python3.11 -m pip install netaddr
安装engine页面加载不出来报如下错误,未解决
安装完成gfs后进入engine安装界面时报如下错误,未解决
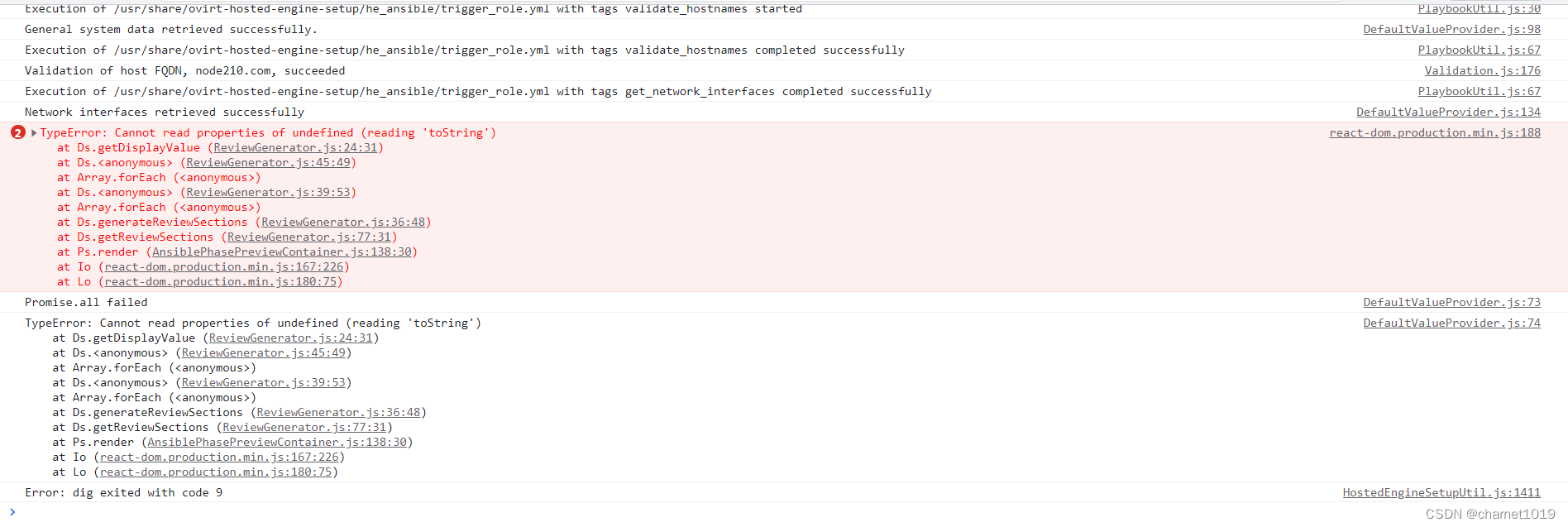
执行engine-setup后提示ovirt-imageio启动失败,此时在/etc/ovirt-imageio/conf.d增加如下配置开启debug
[root@ovirt454 conf.d]# cat /etc/ovirt-imageio/conf.d/99-local.conf [logger_root]level = DEBUG[root@ovirt454 conf.d]# systemctl start ovirt-imageio
执行启动命令后查看/var/log/ovirt-imageio/daemon.log
如果是没有ssl证书则执行以下命令后再重新执行一次engine-setup,执行前建议先执行一次清理并重启系统
[root@ovirt454 conf.d]# engine-cleanup[root@ovirt454 conf.d]# reboot[root@ovirt454 conf.d]# vdsm-tool configure --module certificatesChecking configuration status... Running configure... Reconfiguration of certificates is done. Done configuring modules to VDSM.
上传ISO镜像时提示注册CA证书,此问题可能和all-in-one安装模式有关
https://lists.ovirt.org/archives/list/users@ovirt.org/thread/W5WY4K45IA6O4NA2CTALVOSPUKLHESFB/
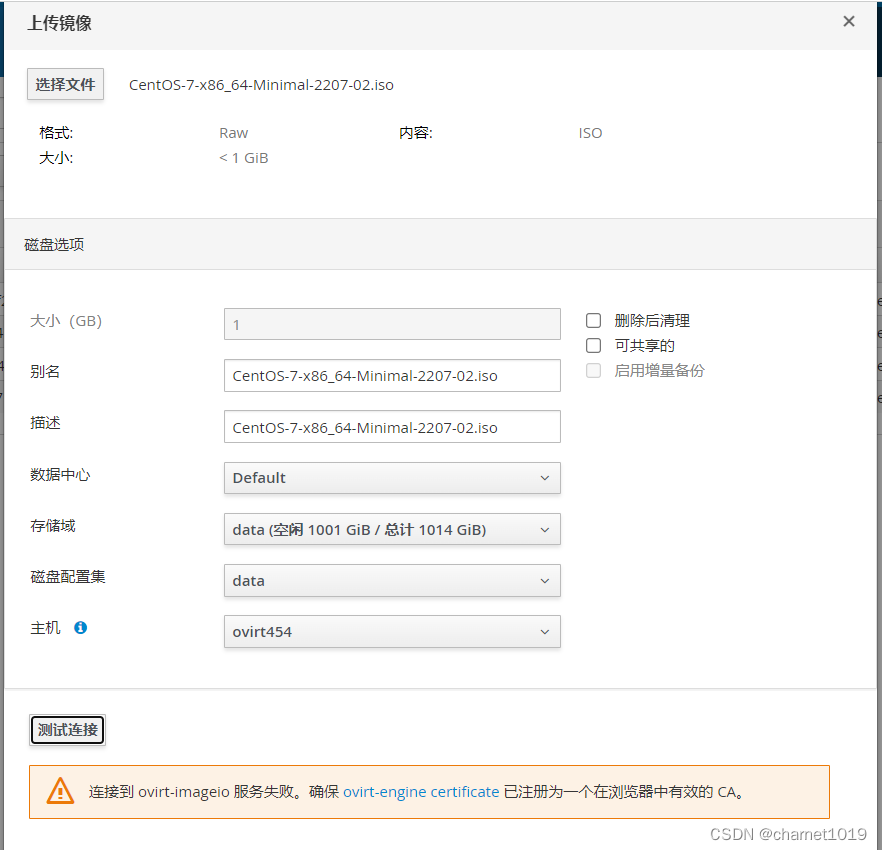
解决方法:
复制vdsm配置文件
[root@ovirt454 conf.d]# cp /etc/ovirt-imageio/conf.d/60-vdsm.conf /etc/ovirt-imageio/conf.d/99-local.conf
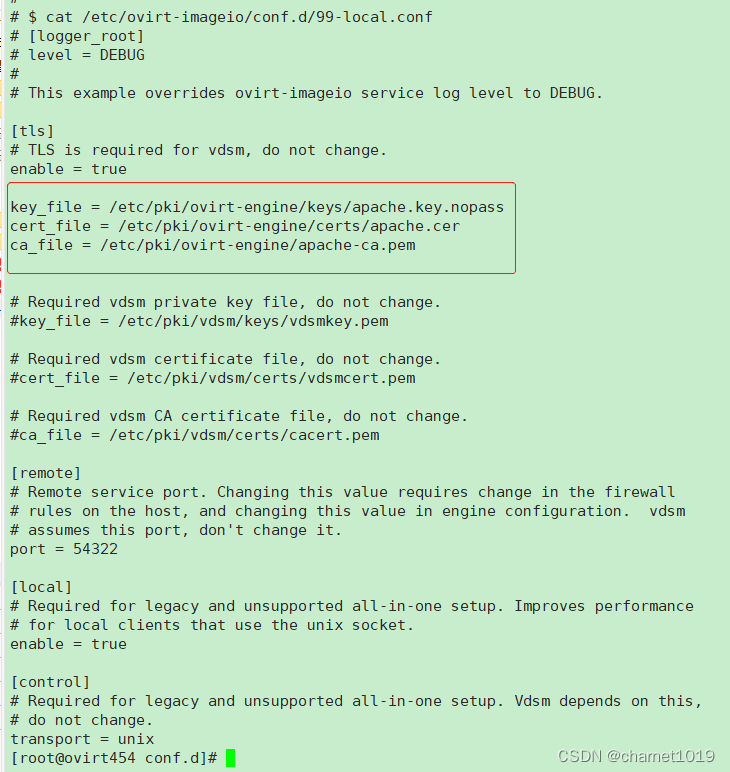
修改99-local.conf中ssl证书为/etc/ovirt-imageio/conf.d/50-engine.conf中的证书
# $ cat /etc/ovirt-imageio/conf.d/99-local.conf# [logger_root]# level = DEBUG## This example overrides ovirt-imageio service log level to DEBUG.[tls]# TLS is required for vdsm, do not change.enable = truekey_file = /etc/pki/ovirt-engine/keys/apache.key.nopass cert_file = /etc/pki/ovirt-engine/certs/apache.cer ca_file = /etc/pki/ovirt-engine/apache-ca.pem# Required vdsm private key file, do not change.#key_file = /etc/pki/vdsm/keys/vdsmkey.pem# Required vdsm certificate file, do not change.#cert_file = /etc/pki/vdsm/certs/vdsmcert.pem# Required vdsm CA certificate file, do not change.#ca_file = /etc/pki/vdsm/certs/cacert.pem[remote]# Remote service port. Changing this value requires change in the firewall# rules on the host, and changing this value in engine configuration. vdsm# assumes this port, don't change it.port = 54322[local]# Required for legacy and unsupported all-in-one setup. Improves performance# for local clients that use the unix socket.enable = true[control]# Required for legacy and unsupported all-in-one setup. Vdsm depends on this,# do not change.transport = unix
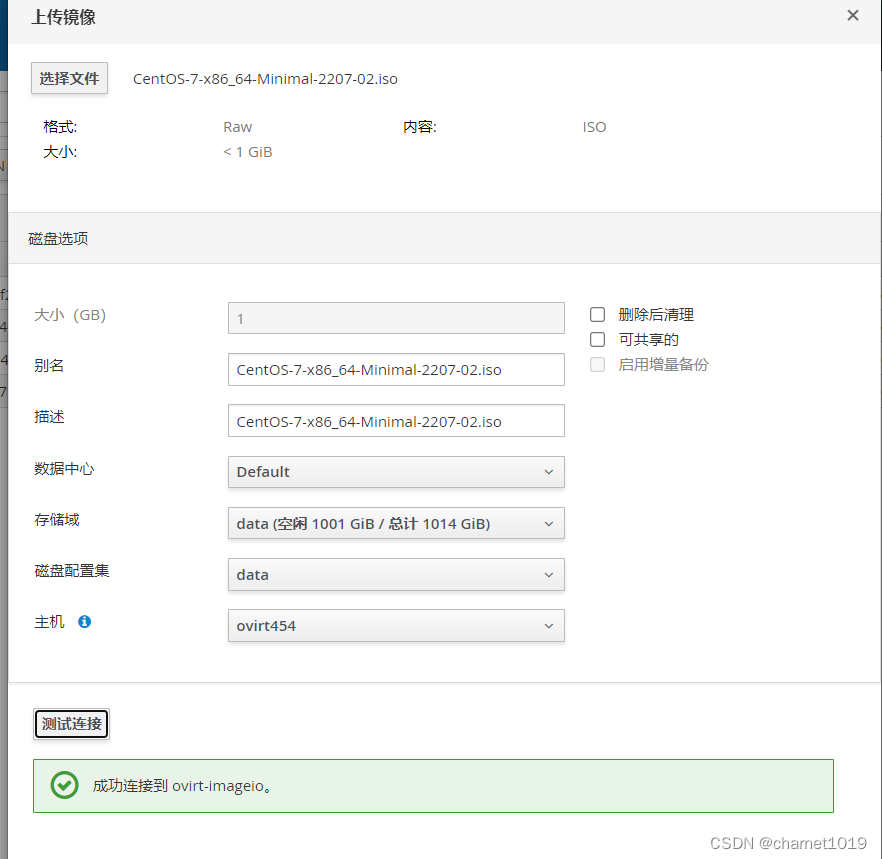
重启ovirt-imageio服务
[root@ovirt454 conf.d]# systemctl restart ovirt-imageio[root@ovirt454 conf.d]# netstat -nplt | grep 54322tcp6 0 0 :::54322 :::* LISTEN 69337/python3
将54322端口放开
[root@ovirt454 conf.d]# firewall-cmd --zone=public --permanent --add-port=54322/tcp[root@ovirt454 conf.d]# firewall-cmd --reload[root@ovirt454 conf.d]# firewall-cmd --list-ports --zone=public22/tcp 9986/tcp 54322/tcp 6081/udp
验证
创建虚拟机时给虚拟机设置静态IP
在"新建虚拟机"–> "初始运行"中设置虚拟机静态IP,如下所示: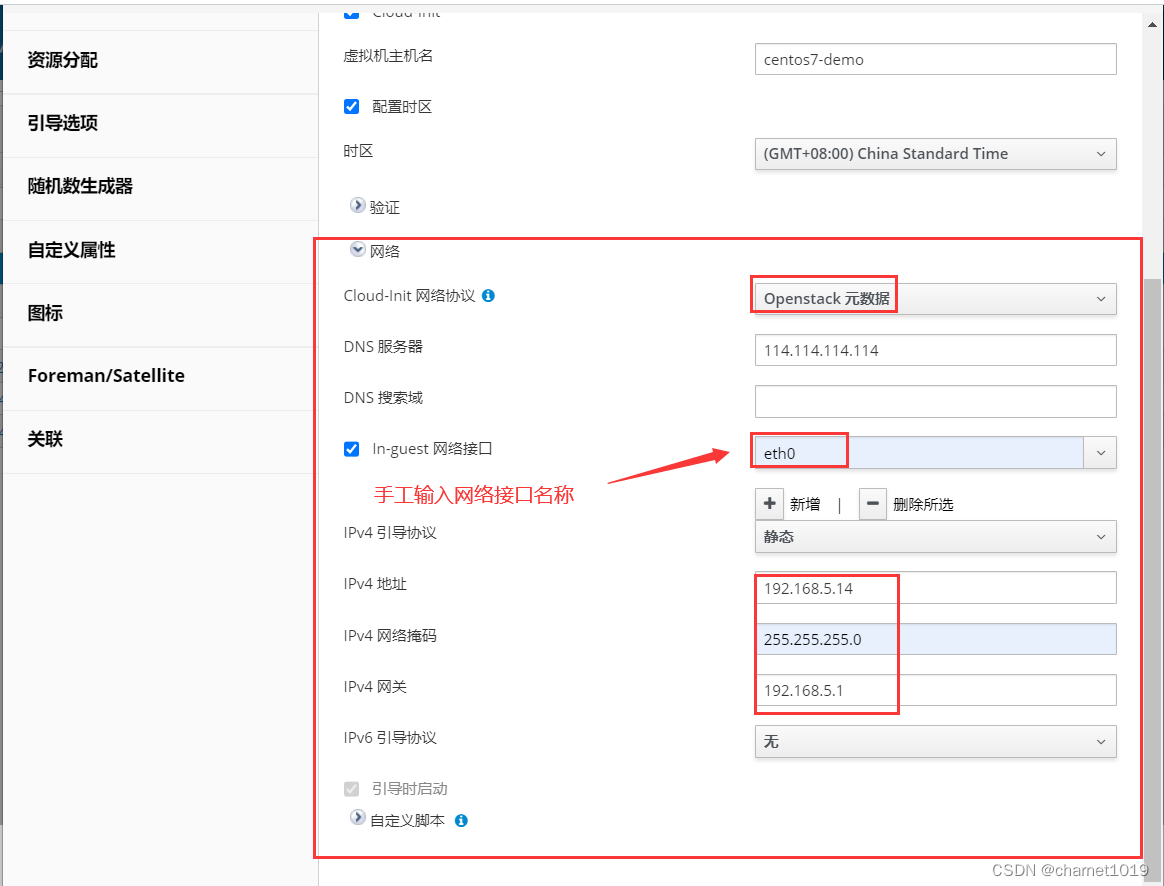
hosted engine运行一段时间后突然提示"因为ha的分数而不可用",且只在迁移hosted engine界面只能看到一个主机选项,此时查看所有主机的ovirt-ha-agent和ovirt-ha-broker都正常运行,查看ovirt-ha-agent日志有如下报错,重启agent和broker也无效,查看所有存储也显示正常,下面文章中提示99%都因存储问题引起的,因此重启engine存储域解决
https://bugzilla.redhat.com/show_bug.cgi?id=1639997
MainThread::ERROR::2023-09-12 15:07:00,147::hosted_engine::564::ovirt_hosted_engine_ha.agent.hosted_engine.HostedEngine::(_initialize_broker) Failed to start necessary monitors MainThread::ERROR::2023-09-12 15:07:00,148::agent::143::ovirt_hosted_engine_ha.agent.agent.Agent::(_run_agent) Traceback (most recent call last): File "/usr/lib/python3.6/site-packages/ovirt_hosted_engine_ha/lib/brokerlink.py", line 85, in start_monitor response = self._proxy.start_monitor(type, options) File "/usr/lib64/python3.6/xmlrpc/client.py", line 1112, in __call__ return self.__send(self.__name, args) File "/usr/lib64/python3.6/xmlrpc/client.py", line 1452, in __request verbose=self.__verbose File "/usr/lib64/python3.6/xmlrpc/client.py", line 1154, in request return self.single_request(host, handler, request_body, verbose) File "/usr/lib64/python3.6/xmlrpc/client.py", line 1166, in single_request http_conn = self.send_request(host, handler, request_body, verbose) File "/usr/lib64/python3.6/xmlrpc/client.py", line 1279, in send_request self.send_content(connection, request_body) File "/usr/lib64/python3.6/xmlrpc/client.py", line 1309, in send_content connection.endheaders(request_body) File "/usr/lib64/python3.6/http/client.py", line 1268, in endheaders self._send_output(message_body, encode_chunked=encode_chunked) File "/usr/lib64/python3.6/http/client.py", line 1044, in _send_output self.send(msg) File "/usr/lib64/python3.6/http/client.py", line 982, in send self.connect() File "/usr/lib/python3.6/site-packages/ovirt_hosted_engine_ha/lib/unixrpc.py", line 76, in connect self.sock.connect(base64.b16decode(self.host))FileNotFoundError: [Errno 2] No such file or directory
异常情况下执行hosted-engine --vm-status信息:
[root@node246 ovirt-hosted-engine-ha]# hosted-engine --vm-status--== Host node240.cluster.local (id: 1) status ==--
Host ID : 1Host timestamp : 9384091Score : 3400Engine status : unknown stale-data
Hostname : node240.cluster.local
Local maintenance : False
stopped : False
crc32 : d6066bcd
conf_on_shared_storage : True
local_conf_timestamp : 9384091Status up-to-date : False
Extra metadata (valid at timestamp): metadata_parse_version=1
metadata_feature_version=1
timestamp=9384091 (Fri Sep 1 23:38:02 2023)
host-id=1
score=3400
vm_conf_refresh_time=9384091 (Fri Sep 1 23:38:03 2023)
conf_on_shared_storage=True maintenance=False state=EngineDown stopped=False
--== Host node241.cluster.local (id: 2) status ==--
Host ID : 2Host timestamp : 9385548Score : 3400Engine status : unknown stale-data
Hostname : node241.cluster.local
Local maintenance : False
stopped : False
crc32 : db1663f8
conf_on_shared_storage : True
local_conf_timestamp : 9385548Status up-to-date : False
Extra metadata (valid at timestamp): metadata_parse_version=1
metadata_feature_version=1
timestamp=9385548 (Fri Sep 1 23:38:01 2023)
host-id=2
score=3400
vm_conf_refresh_time=9385548 (Fri Sep 1 23:38:01 2023)
conf_on_shared_storage=True maintenance=False state=EngineDown stopped=False
--== Host node242.cluster.local (id: 3) status ==--
Host ID : 3Host timestamp : 9382595Score : 3400Engine status : unknown stale-data
Hostname : node242.cluster.local
Local maintenance : False
stopped : False
crc32 : d864f6c9
conf_on_shared_storage : True
local_conf_timestamp : 9382595Status up-to-date : False
Extra metadata (valid at timestamp): metadata_parse_version=1
metadata_feature_version=1
timestamp=9382595 (Fri Sep 1 23:38:08 2023)
host-id=3
score=3400
vm_conf_refresh_time=9382595 (Fri Sep 1 23:38:08 2023)
conf_on_shared_storage=True maintenance=False state=EngineDown stopped=False
--== Host node243.cluster.local (id: 4) status ==--
Host ID : 4Host timestamp : 9435290Score : 3400Engine status : unknown stale-data
Hostname : node243.cluster.local
Local maintenance : False
stopped : False
crc32 : c87f5534
conf_on_shared_storage : True
local_conf_timestamp : 9435290Status up-to-date : False
Extra metadata (valid at timestamp): metadata_parse_version=1
metadata_feature_version=1
timestamp=9435290 (Fri Sep 1 23:38:04 2023)
host-id=4
score=3400
vm_conf_refresh_time=9435290 (Fri Sep 1 23:38:04 2023)
conf_on_shared_storage=True maintenance=False state=EngineDown stopped=False
--== Host node246.cluster.local (id: 5) status ==--
Host ID : 5Host timestamp : 10305546Score : 3400Engine status : {"vm": "down", "health": "bad", "detail": "unknown", "reason": "vm not running on this host"}Hostname : node246.cluster.local
Local maintenance : False
stopped : False
crc32 : 9d801281
conf_on_shared_storage : True
local_conf_timestamp : 10305546Status up-to-date : True
Extra metadata (valid at timestamp): metadata_parse_version=1
metadata_feature_version=1
timestamp=10305546 (Tue Sep 12 16:42:34 2023)
host-id=5
score=3400
vm_conf_refresh_time=10305546 (Tue Sep 12 16:42:34 2023)
conf_on_shared_storage=True maintenance=False state=EngineStarting stopped=False
--== Host node247.cluster.local (id: 6) status ==--
Host ID : 6Host timestamp : 9379415Score : 3400Engine status : unknown stale-data
Hostname : node247.cluster.local
Local maintenance : False
stopped : False
crc32 : cb8b9194
conf_on_shared_storage : True
local_conf_timestamp : 9379415Status up-to-date : False
Extra metadata (valid at timestamp): metadata_parse_version=1
metadata_feature_version=1
timestamp=9379415 (Fri Sep 1 23:38:04 2023)
host-id=6
score=3400
vm_conf_refresh_time=9379415 (Fri Sep 1 23:38:04 2023)
conf_on_shared_storage=True maintenance=False state=EngineUp stopped=False重启存储域命令:
gluster volume stop engine gluster volume start engine force
gfs运行一段时间后突然其中一个节点的Self-heal的PID显示为N/A
[root@node240 glusterfs]# gluster volume status dataStatus of volume: data Gluster process TCP Port RDMA Port Online Pid ------------------------------------------------------------------------------ Brick node240.cluster.local:/gluster_bricks /data/data 49154 0 Y 1302876Brick node241.cluster.local:/gluster_bricks /data/data 49154 0 Y 2959842Brick node242.cluster.local:/gluster_bricks /data/data 49154 0 Y 1931196Brick node243.cluster.local:/gluster_bricks /data/data 49152 0 Y 1963620Brick node246.cluster.local:/gluster_bricks /data/data 49152 0 Y 4049476Brick node247.cluster.local:/gluster_bricks /data/data 49152 0 Y 1764914Self-heal Daemon on localhost N/A N/A Y 6636 Self-heal Daemon on node241.cluster.local N/A N/A Y 6430 Self-heal Daemon on node246.cluster.local N/A N/A N N/A Self-heal Daemon on node242.cluster.local N/A N/A Y 6782 Self-heal Daemon on node243.cluster.local N/A N/A Y 5672 Self-heal Daemon on node247.cluster.local N/A N/A Y 6093 Task Status of Volume data ------------------------------------------------------------------------------ Task : Rebalance ID : fcfd1e37-7938-410c-81d7-59fdfb61b30d Status : completed
解决方法:
强制启动对应的存储
[root@node240 glusterfs]# gluster volume start data forcevolume start: data: success
强制启动后到对应的节点查看glustershd.log日志或查看glusterd进程状态,若有报内存问题,如下所示:
[2024-04-29 01:08:06.478850] I [MSGID: 100041] [glusterfsd-mgmt.c:1034:glusterfs_handle_svc_attach] 0-glusterfs: received attach request for volfile [{volfile-id=shd/data}] [2024-04-29 01:08:06.481393] A [MSGID: 0] [mem-pool.c:154:__gf_calloc] : no memory available for size (224984) current memory usage in kilobytes 941540 [call stack follows]/lib64/libglusterfs.so.0(+0x2a1a4)[0x7fa6434601a4]/lib64/libglusterfs.so.0(_gf_msg_nomem+0x292)[0x7fa643460652]/lib64/libglusterfs.so.0(__gf_calloc+0x118)[0x7fa6434883a8]/lib64/libglusterfs.so.0(inode_table_with_invalidator+0x145)[0x7fa643472ce5]/usr/lib64/glusterfs/8.6/xlator/cluster/replicate.so(+0x7abaf)[0x7fa63a7ffbaf][2024-04-29 01:08:06.481890] E [MSGID: 101019] [xlator.c:623:xlator_init] 0-data-replicate-0: Initialization of volume failed. review your volfile again. [{name=data-replicate-0}] [2024-04-29 01:08:06.481907] E [MSGID: 101066] [graph.c:425:glusterfs_graph_init] 0-data-replicate-0: initializing translator failed
[2024-04-29 01:08:06.481916] W [MSGID: 101219] [graph.c:1719:glusterfs_process_svc_attach_volfp] 0-glusterfsd: failed to initialize graph for xlator data [Invalid argument][2024-04-29 01:08:06.484528] I [io-stats.c:4057:fini] 0-data: io-stats translator unloaded尝试将对应存储的client-io-threads设置为off.
gluster volume set volname client-io-threads off
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
用户管理
添加用户
[root@engine243 ~]# ovirt-aaa-jdbc-tool user add pch --attribute=firstName=ch --attribute=lastName=pPicked up JAVA_TOOL_OPTIONS: -Dcom.redhat.fips=false adding user pch... user added successfully Note: by default created user cannot log in. see: /usr/bin/ovirt-aaa-jdbc-tool user password-reset --help.
给添加的用户设置密码,必须设置–password-valid-to过期参数,否则为当前时间
[root@engine243 ~]# ovirt-aaa-jdbc-tool user password-reset pch --password-valid-to="2023-08-01 12:00:00+0800"Picked up JAVA_TOOL_OPTIONS: -Dcom.redhat.fips=false Password: Reenter password: updating user pch... user updated successfully
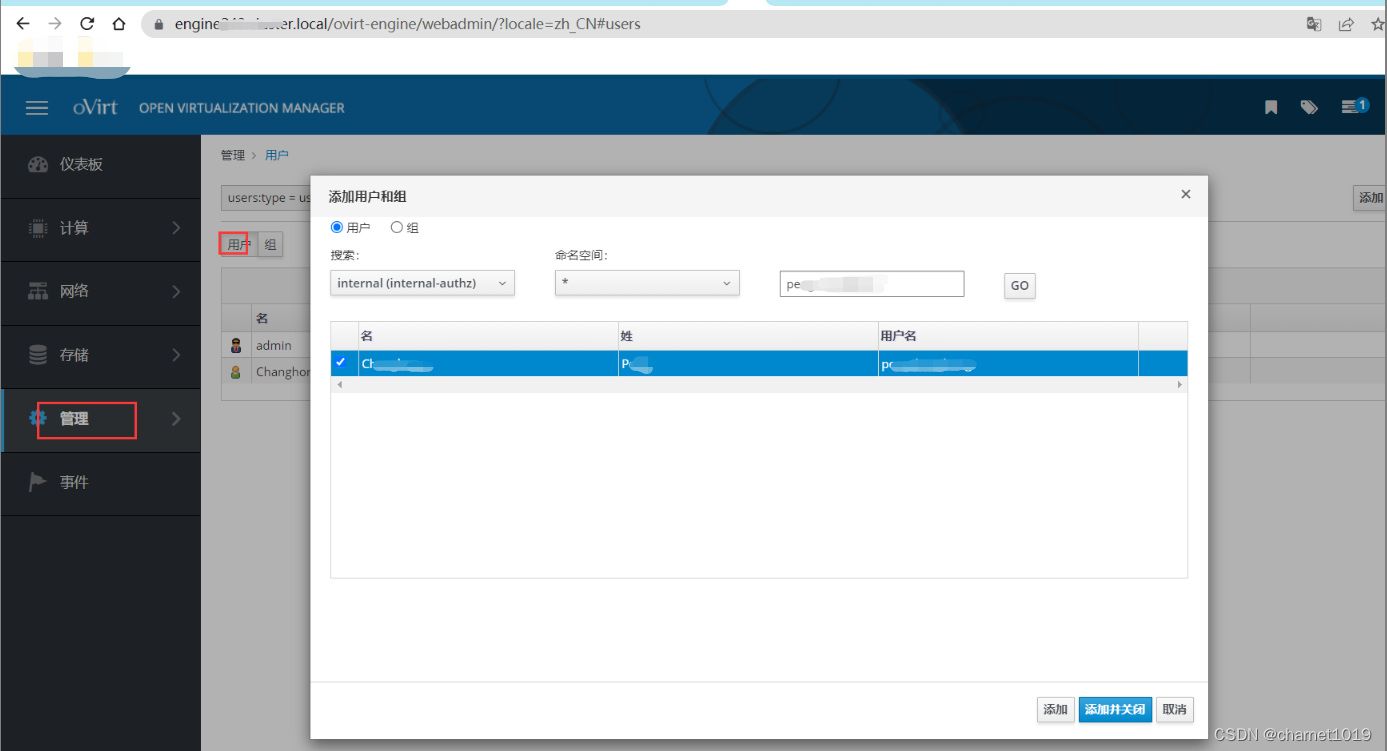
在管理页面添加用户
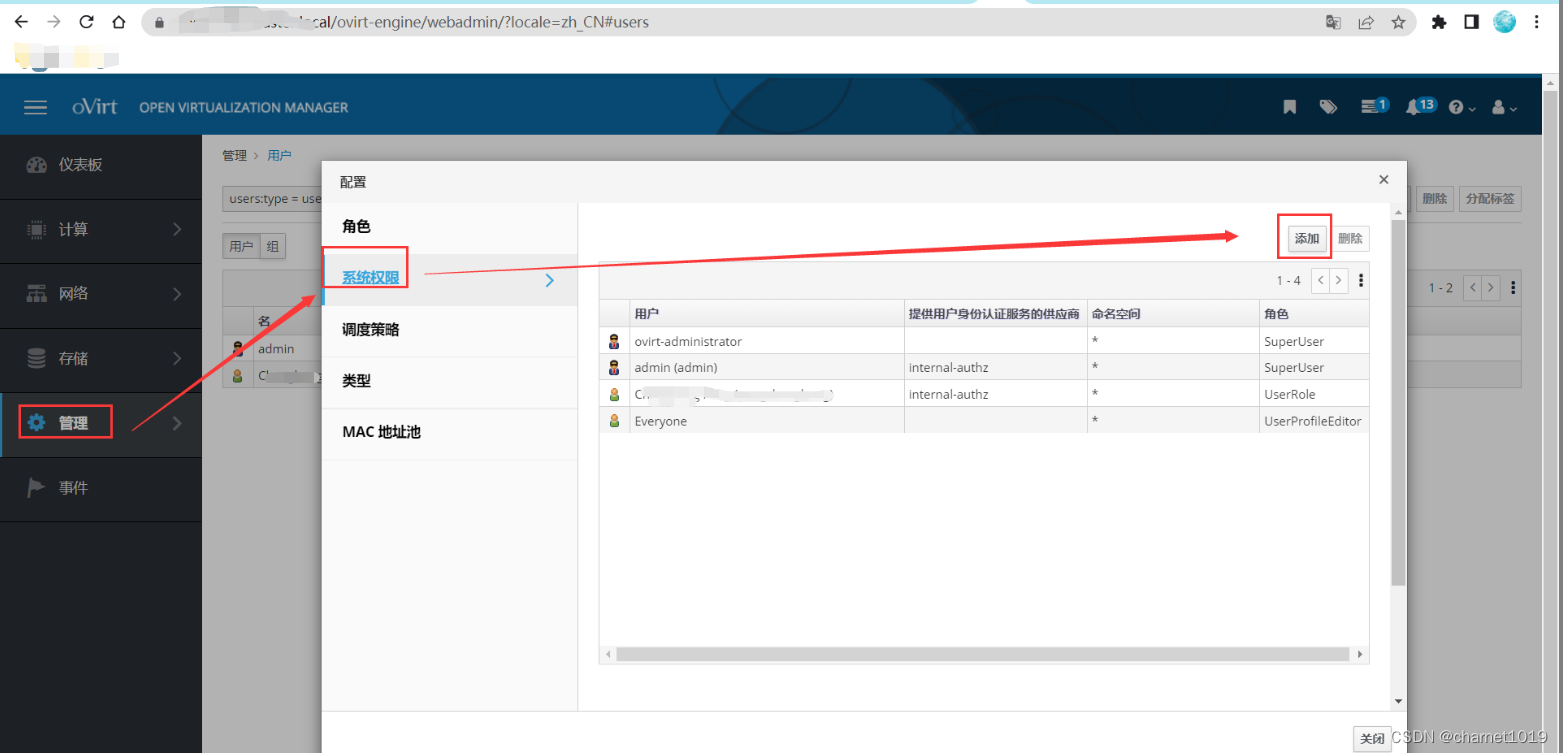
在”管理”->”配置”->”系统权限”给用户授权
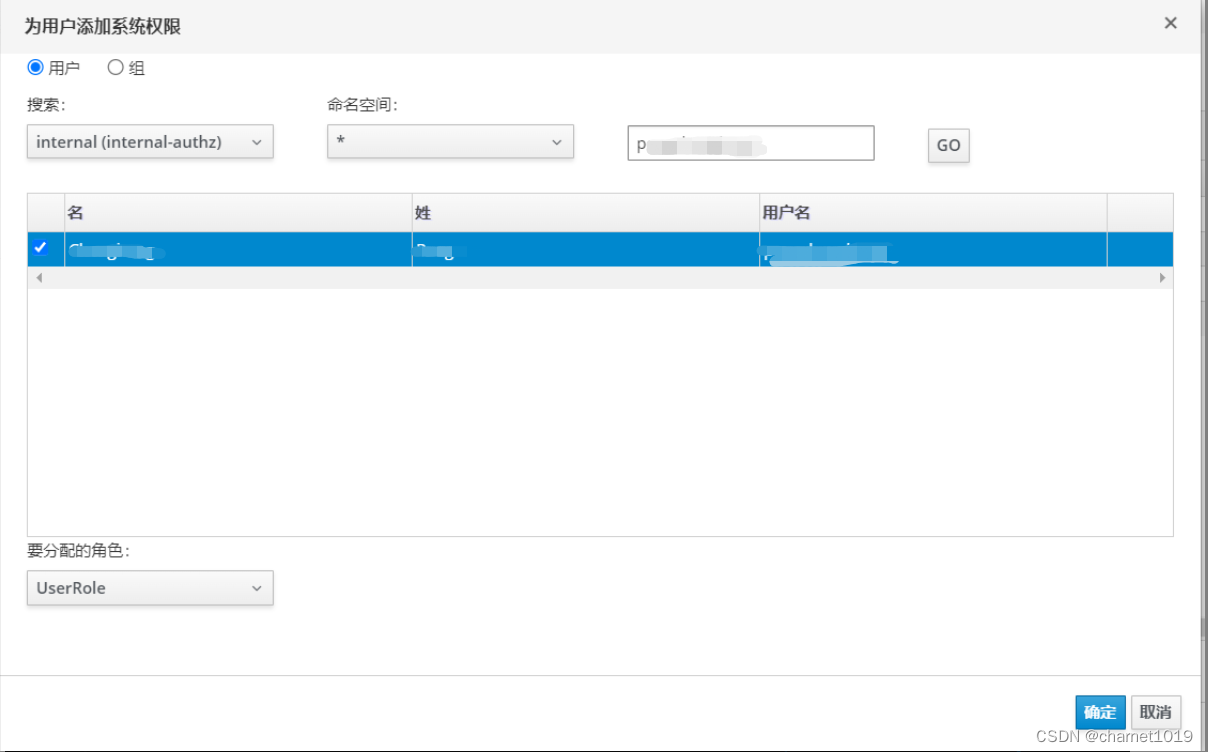
给对应的用户授权相关的权限并确定
查看所有用户
[root@engine243 ~]# ovirt-aaa-jdbc-tool query --what=userPicked up JAVA_TOOL_OPTIONS: -Dcom.redhat.fips=false -- User pch(1675543f-8d7c-4484-a8b3-29208142b74a) -- Namespace: * Name: pch ID: 1675543f-8d7c-4484-a8b3-29208142b74a Display Name: Email: First Name: ch Last Name: p Department: Title: Description: Account Disabled: falseAccount Locked: falseAccount Unlocked At: 1970-01-01 00:00:00Z Account Valid From: 2023-05-09 06:05:13Z Account Valid To: 2223-05-09 06:05:13Z Account Without Password: falseLast successful Login At: 2023-05-10 02:16:36Z Last unsuccessful Login At: 1970-01-01 00:00:00Z Password Valid To: 2023-08-01 04:00:00Z -- User admin(7218e9e2-90b3-4d21-8334-14685183e88d) -- Namespace: * Name: admin ID: 7218e9e2-90b3-4d21-8334-14685183e88d Display Name: Email: root@localhost First Name: admin Last Name: Department: Title: Description: Account Disabled: falseAccount Locked: falseAccount Unlocked At: 1970-01-01 00:00:00Z Account Valid From: 2023-05-06 09:15:44Z Account Valid To: 2223-05-06 09:15:44Z Account Without Password: falseLast successful Login At: 2023-05-10 02:52:33Z Last unsuccessful Login At: 1970-01-01 00:00:00Z Password Valid To: 2223-03-19 09:15:47Z
更新用户密码
[root@engine248 ~]# ovirt-aaa-jdbc-tool user password-reset admin --password-valid-to="2050-11-16 12:00:00+0800"Picked up JAVA_TOOL_OPTIONS: -Dcom.redhat.fips=false Password: Reenter password: updating user admin... user updated successfully
禁用用户
ovirt-aaa-jdbc-tool user edit admin --flag=+disabled
启用用户
ovirt-aaa-jdbc-tool user edit admin --flag=-disabled
设置用户登录失败几次后锁定用户,默认5次,全局配置
ovirt-aaa-jdbc-tool settings set --name=MAX_FAILURES_SINCE_SUCCESS --value=3
解锁用户
ovirt-aaa-jdbc-tool user unlock admin
用户组管理
添加用户组
[root@engine243 ~]# ovirt-aaa-jdbc-tool group add opsPicked up JAVA_TOOL_OPTIONS: -Dcom.redhat.fips=false adding group ops... group added successfully
添加用户到组
[root@engine243 ~]# ovirt-aaa-jdbc-tool group-manage useradd ops --user=pchPicked up JAVA_TOOL_OPTIONS: -Dcom.redhat.fips=false updating user ops... user updated successfully
查看组信息
[root@engine243 ~]# ovirt-aaa-jdbc-tool query --what=opsPicked up JAVA_TOOL_OPTIONS: -Dcom.redhat.fips=false Pattern for argument 'what' does not match, pattern is 'user|group', value is 'ops'[root@engine243 ~]# [root@engine243 ~]# [root@engine243 ~]# ovirt-aaa-jdbc-tool query --what=groupPicked up JAVA_TOOL_OPTIONS: -Dcom.redhat.fips=false -- Group ops(c37f6bf3-559a-446d-bf6d-f3a10b693db2) -- Namespace: * Name: ops ID: c37f6bf3-559a-446d-bf6d-f3a10b693db2 Display Name: Description:
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
GFS常用命令
查看节点状态
[root@node100 ~]# gluster peer statusNumber of Peers: 2Hostname: node101.com Uuid: 8a1adcef-323a-4f34-ae6f-e12ab7e1c02d State: Peer in Cluster (Connected)Hostname: node102.com Uuid: df319280-dde2-48a3-8e86-9cfff76384b8 State: Peer in Cluster (Connected)
查看集群节点信息
[root@node100 ~]# gluster pool listUUID Hostname State 8a1adcef-323a-4f34-ae6f-e12ab7e1c02d node101.com Connected df319280-dde2-48a3-8e86-9cfff76384b8 node102.com Connected d0dc72bb-4f5a-48a3-93dc-1dbb7c0fba55 localhost Connected
查看集群中所有的卷
[root@node100 ~]# gluster volume listdata engine vmstore
查看某个卷的状态
[root@node100 ~]# gluster volume status dataStatus of volume: data Gluster process TCP Port RDMA Port Online Pid ------------------------------------------------------------------------------ Brick node100.com:/gluster_bricks/data/data 49155 0 Y 386797Brick node101.com:/gluster_bricks/data/data 49152 0 Y 7510 Brick node102.com:/gluster_bricks/data/data 49152 0 Y 2219 Self-heal Daemon on localhost N/A N/A Y 389738Self-heal Daemon on node211.com N/A N/A Y 7785 Self-heal Daemon on node212.com N/A N/A Y 20415 Task Status of Volume data ------------------------------------------------------------------------------ There are no active volume tasks
查看某个卷的信息
[root@node100 ~]# gluster volume info data Volume Name: data Type: Replicate Volume ID: 18d13836-b0ba-44ba-845f-b4ab46f6a2e3 Status: Started Snapshot Count: 0Number of Bricks: 1 x 3 = 3Transport-type: tcp Bricks: Brick1: node100.com:/gluster_bricks/data/data Brick2: node101.com:/gluster_bricks/data/data Brick3: node102.com:/gluster_bricks/data/data Options Reconfigured: performance.client-io-threads: on nfs.disable: on transport.address-family: inet storage.fips-mode-rchecksum: on performance.quick-read: off performance.read-ahead: off performance.io-cache: off performance.low-prio-threads: 32network.remote-dio: off performance.strict-o-direct: on cluster.eager-lock: enablecluster.quorum-type: auto cluster.server-quorum-type: server cluster.data-self-heal-algorithm: full cluster.locking-scheme: granular cluster.shd-max-threads: 8cluster.shd-wait-qlength: 10000features.shard: on user.cifs: off cluster.choose-local: off client.event-threads: 4server.event-threads: 4network.ping-timeout: 30server.tcp-user-timeout: 20server.keepalive-time: 10server.keepalive-interval: 2server.keepalive-count: 5cluster.lookup-optimize: off storage.owner-uid: 36storage.owner-gid: 36cluster.granular-entry-heal: enable
查看集群所有卷的信息
[root@node100 ~]# gluster volume info Volume Name: data Type: Replicate Volume ID: 18d13836-b0ba-44ba-845f-b4ab46f6a2e3 Status: Started Snapshot Count: 0Number of Bricks: 1 x 3 = 3Transport-type: tcp Bricks: Brick1: node100.com:/gluster_bricks/data/data Brick2: node101.com:/gluster_bricks/data/data Brick3: node102.com:/gluster_bricks/data/data Options Reconfigured: performance.client-io-threads: on nfs.disable: on transport.address-family: inet storage.fips-mode-rchecksum: on performance.quick-read: off performance.read-ahead: off performance.io-cache: off performance.low-prio-threads: 32network.remote-dio: off performance.strict-o-direct: on cluster.eager-lock: enablecluster.quorum-type: auto cluster.server-quorum-type: server cluster.data-self-heal-algorithm: full cluster.locking-scheme: granular cluster.shd-max-threads: 8cluster.shd-wait-qlength: 10000features.shard: on user.cifs: off cluster.choose-local: off client.event-threads: 4server.event-threads: 4network.ping-timeout: 30server.tcp-user-timeout: 20server.keepalive-time: 10server.keepalive-interval: 2server.keepalive-count: 5cluster.lookup-optimize: off storage.owner-uid: 36storage.owner-gid: 36cluster.granular-entry-heal: enable Volume Name: engine Type: Replicate Volume ID: c9d72bc2-9cc5-4619-b0e9-aa095b2f066f Status: Started Snapshot Count: 0Number of Bricks: 1 x 3 = 3Transport-type: tcp Bricks: Brick1: node100.com:/gluster_bricks/engine/engine Brick2: node101.com:/gluster_bricks/engine/engine Brick3: node102.com:/gluster_bricks/engine/engine Options Reconfigured: performance.client-io-threads: on nfs.disable: on transport.address-family: inet storage.fips-mode-rchecksum: on performance.quick-read: off performance.read-ahead: off performance.io-cache: off performance.low-prio-threads: 32network.remote-dio: off performance.strict-o-direct: on cluster.eager-lock: enablecluster.quorum-type: auto cluster.server-quorum-type: server cluster.data-self-heal-algorithm: full cluster.locking-scheme: granular cluster.shd-max-threads: 8cluster.shd-wait-qlength: 10000features.shard: on user.cifs: off cluster.choose-local: off client.event-threads: 4server.event-threads: 4network.ping-timeout: 30server.tcp-user-timeout: 20server.keepalive-time: 10server.keepalive-interval: 2server.keepalive-count: 5cluster.lookup-optimize: off storage.owner-uid: 36storage.owner-gid: 36cluster.granular-entry-heal: enable Volume Name: vmstore Type: Replicate Volume ID: a2c90ea2-ae1c-4c2d-8558-0b3d5db17c2b Status: Started Snapshot Count: 0Number of Bricks: 1 x 3 = 3Transport-type: tcp Bricks: Brick1: node100.com:/gluster_bricks/vmstore/vmstore Brick2: node101.com:/gluster_bricks/vmstore/vmstore Brick3: node102.com:/gluster_bricks/vmstore/vmstore Options Reconfigured: performance.client-io-threads: on nfs.disable: on transport.address-family: inet storage.fips-mode-rchecksum: on performance.quick-read: off performance.read-ahead: off performance.io-cache: off performance.low-prio-threads: 32network.remote-dio: off performance.strict-o-direct: on cluster.eager-lock: enablecluster.quorum-type: auto cluster.server-quorum-type: server cluster.data-self-heal-algorithm: full cluster.locking-scheme: granular cluster.shd-max-threads: 8cluster.shd-wait-qlength: 10000features.shard: on user.cifs: off cluster.choose-local: off client.event-threads: 4server.event-threads: 4network.ping-timeout: 30server.tcp-user-timeout: 20server.keepalive-time: 10server.keepalive-interval: 2server.keepalive-count: 5cluster.lookup-optimize: off storage.owner-uid: 36storage.owner-gid: 36cluster.granular-entry-heal: enable
查看集群所有卷的状态
[root@node100 ~]# gluster volume statusStatus of volume: data Gluster process TCP Port RDMA Port Online Pid ------------------------------------------------------------------------------ Brick node100.com:/gluster_bricks/data/data 49155 0 Y 386797Brick node101.com:/gluster_bricks/data/data 49152 0 Y 7510 Brick node102.com:/gluster_bricks/data/data 49152 0 Y 2219 Self-heal Daemon on localhost N/A N/A Y 389738Self-heal Daemon on node211.com N/A N/A Y 7785 Self-heal Daemon on node212.com N/A N/A Y 20415 Task Status of Volume data ------------------------------------------------------------------------------ There are no active volume tasks Status of volume: engine Gluster process TCP Port RDMA Port Online Pid ------------------------------------------------------------------------------ Brick node100.com:/gluster_bricks/engine/en gine 49156 0 Y 389713Brick node101.com:/gluster_bricks/engine/en gine 49153 0 Y 7566 Brick node102.com:/gluster_bricks/engine/en gine 49153 0 Y 2263 Self-heal Daemon on localhost N/A N/A Y 389738Self-heal Daemon on node211.com N/A N/A Y 7785 Self-heal Daemon on node212.com N/A N/A Y 20415 Task Status of Volume engine ------------------------------------------------------------------------------ There are no active volume tasks Status of volume: vmstore Gluster process TCP Port RDMA Port Online Pid ------------------------------------------------------------------------------ Brick node100.com:/gluster_bricks/vmstore/v mstore 49157 0 Y 386819Brick node101.com:/gluster_bricks/vmstore/v mstore 49154 0 Y 7655 Brick node102.com:/gluster_bricks/vmstore/v mstore 49154 0 Y 2282 Self-heal Daemon on localhost N/A N/A Y 389738Self-heal Daemon on node211.com N/A N/A Y 7785 Self-heal Daemon on node212.com N/A N/A Y 20415 Task Status of Volume vmstore ------------------------------------------------------------------------------ There are no active volume tasks
启动一个卷,加force强制启动
[root@node100 ~]# gluster volume start data [force]
查看卷详细信息
[root@node100 ~]# gluster volume heal <volume_name> info
启动 GlusterFS 卷的自动修复功能
[root@node100 ~]# gluster volume heal <volume_name> full
推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://hqyman.cn/post/7028.html 非本站原创文章欢迎转载,原创文章需保留本站地址!

 微信支付宝扫一扫,打赏作者吧~
微信支付宝扫一扫,打赏作者吧~休息一下~~