
大家好。简单的采集规则让不懂代码的同学通过简单学习掌握爬虫技巧是胖鼠采集的核心
来源: 胖鼠采集 (原文保持最新规则教程)
下面带领大家来创建一个自己采集规则。
视频版本 https://v.youku.com/v_show/id_XNDI5MTQ2NzkwMA==.html?spm=a2h3j.8428770.3416059.1
核心只需要填好五个参数
采集地址
采集范围
采集规则
详情页采集范围
详情页采集规则
地址: 顾名思义, 是我们大家目标页面的地址
采集范围: 你要采集目标页面的哪一块数据
采集规则: 你要怎么采
详情采集范围: 同上
详情采集规则: 同上
核心五部曲:

例子
采集目标地址: https://xx.qq.com/webplat/info/news_version3/154/2233/3889/m2702/list_1.shtml
右键 检查 即可看到页面代码
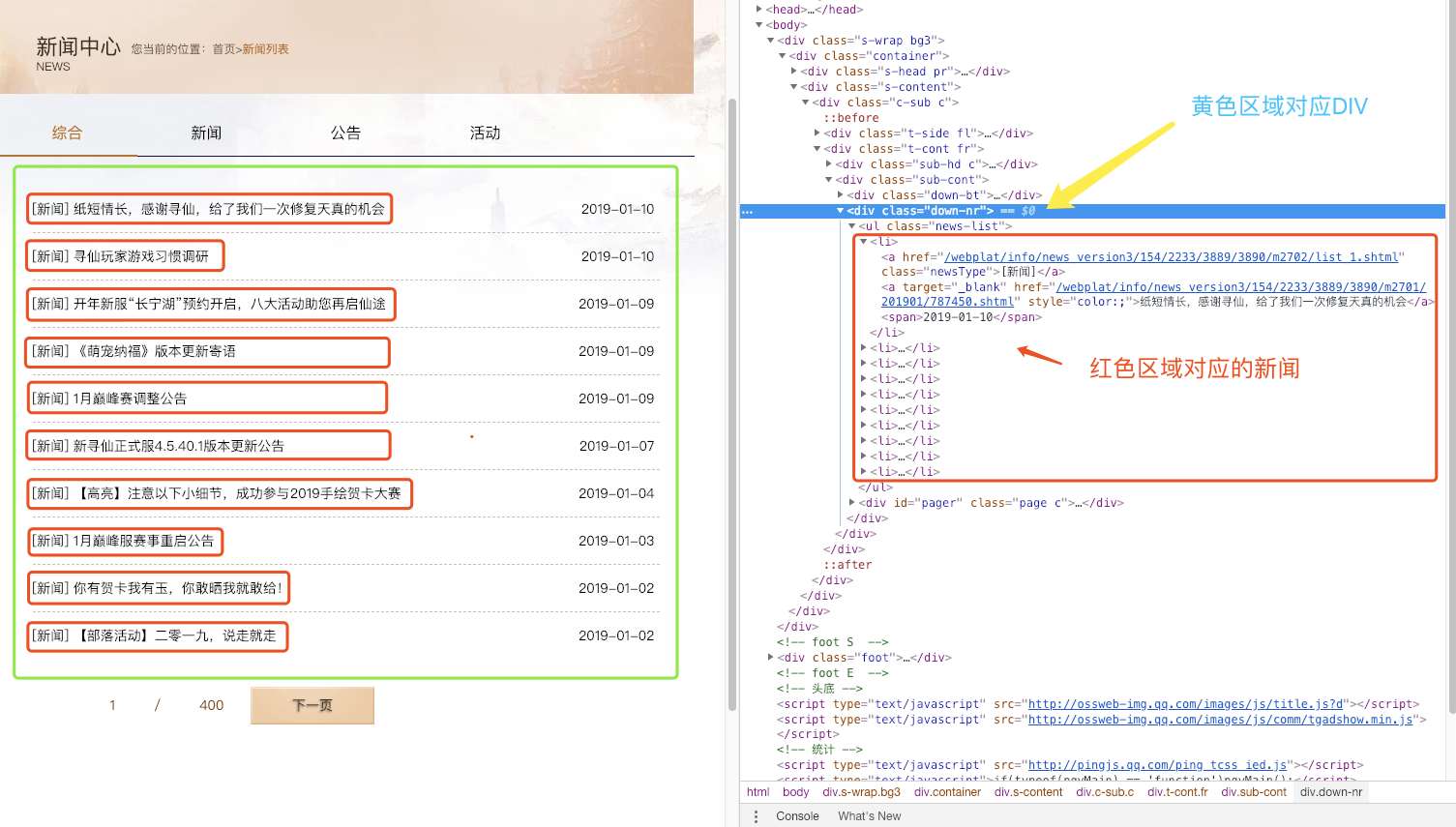
黄色区域就是我们要采集的范围,所以我们采集范围这么写
采集范围: .down-nr>ul>li
解释: 加上 ul li 会循环的采集每一个块。达到了我们列表采集的目的
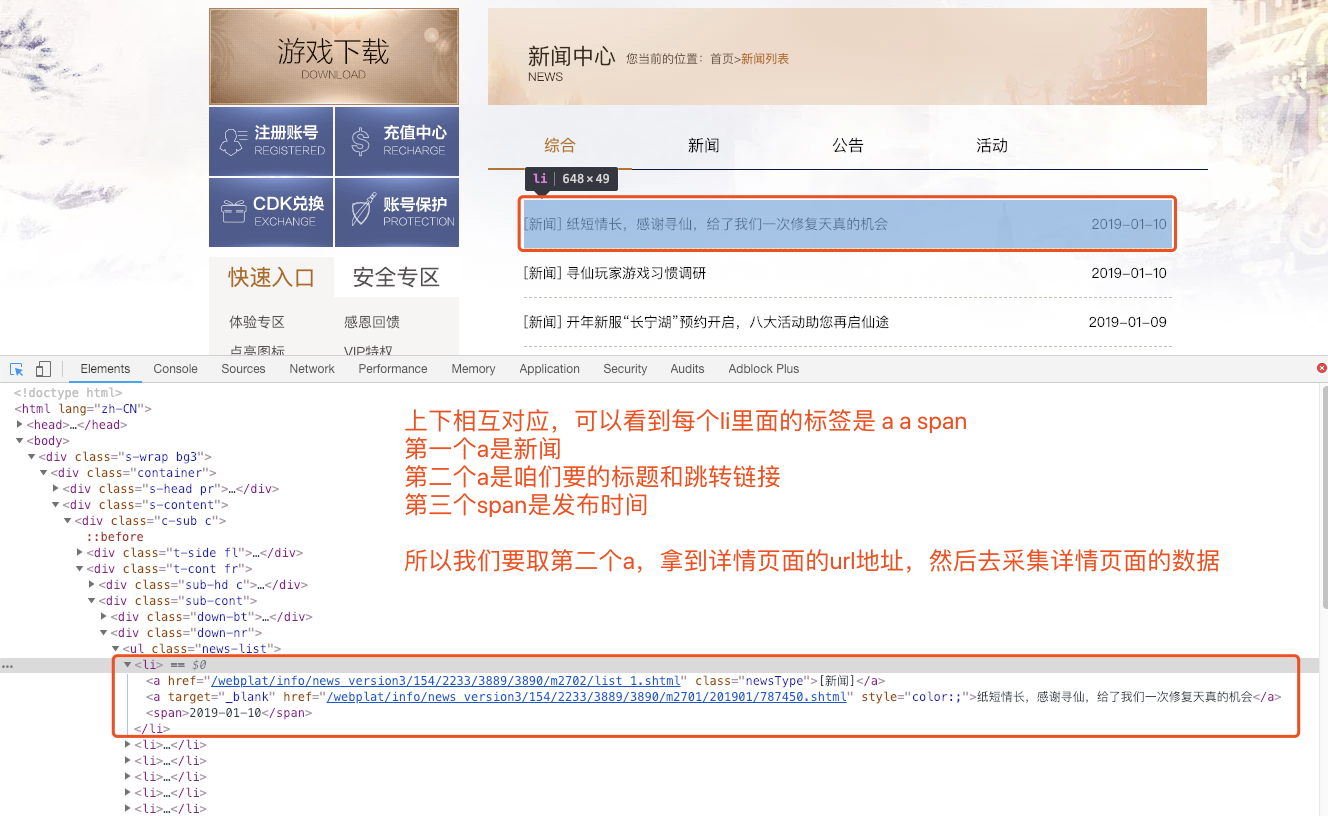
采集规则: a:eq(1)
解释: a 选中a标签 :eq(1) 是选中 li下面第1个a标签, 注: 数字是从0开始的。 第一个a是0 第二个a是1 懂了吧?
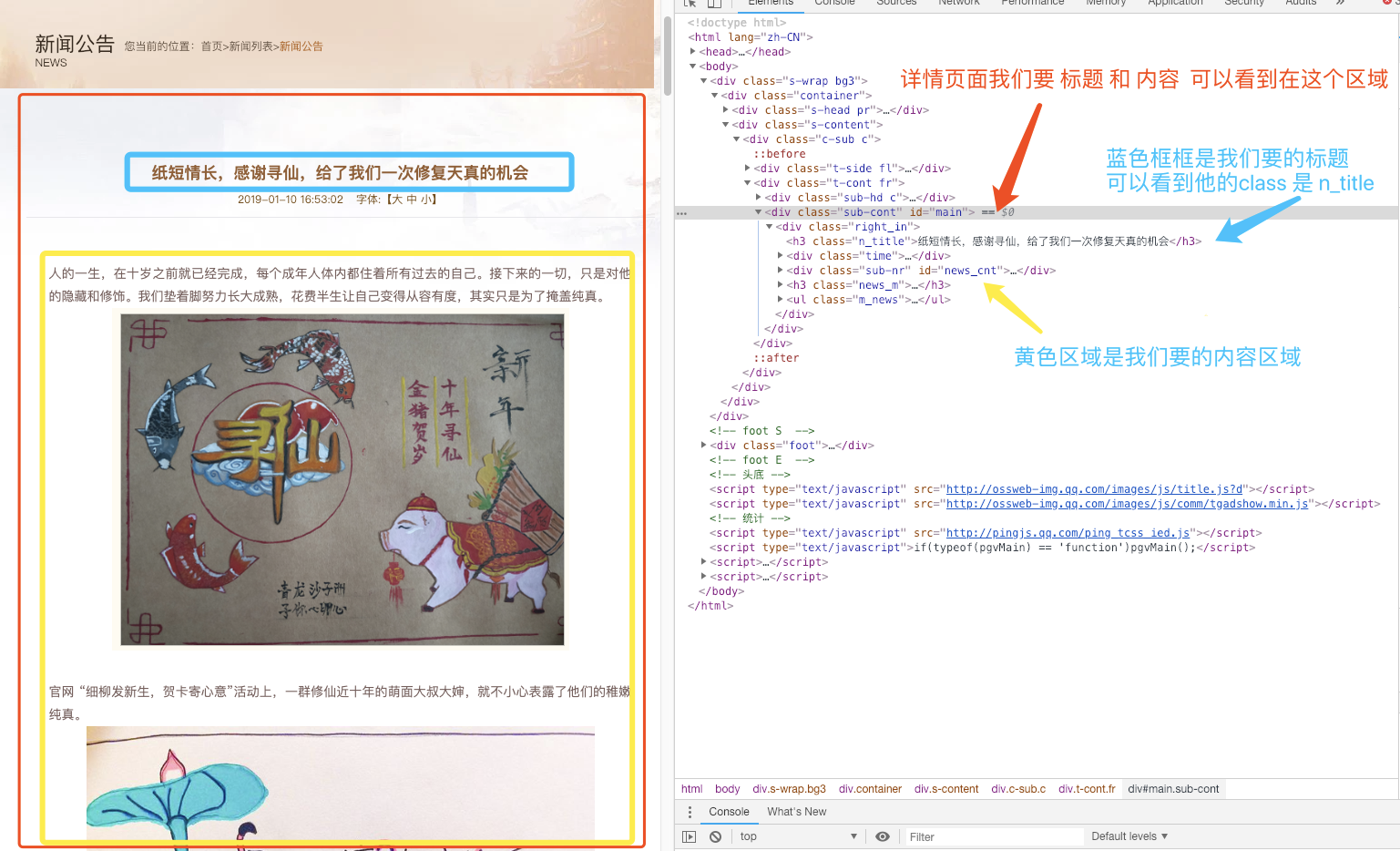
详情采集范围 .sub-cont
解释: 看图 .sub-cont 包括了 标题和内容。 所以我们选择这个区域
详情采集规则 title = .n_title
详情采集规则 content = .sub-nr
解释: 看图 .n_title 是文章的标题
解释: 看图 .sub-nr 使文章的内容
完成的配置

解释一下 规则名 目前默认三个值暂时够用
a href 取 a标签的 href(这个属性都是跳转地址) 值
xxx text 意指 取 xxx的text(文本的意思)值
xxx html 意指 去 xxx 那个区域的 所有的html 一般用到取内容,内容比较多。且内容有排版。所以要拿到所有的原始html
标签过滤怎么用呢?给大家描述一下
a 就是去除掉所有a标签保留a标签的文本 (去掉原文一些跳转规则)
-a 就是删除a标签 已经a标签里面所有的内容 (不建议使用,因为有些图片是在a里面的 删除a 图片也没了。)
-div 删除所有div
-.class1 删除内容中 class = class1 的标签
- #aaaa 删除文中 id = aaaa 的标签
-p 同上
-b 同上
-span 同上
-p:first 删除第一个 p标签
-p:last 删除最后一个 p标签
就是这个规律...
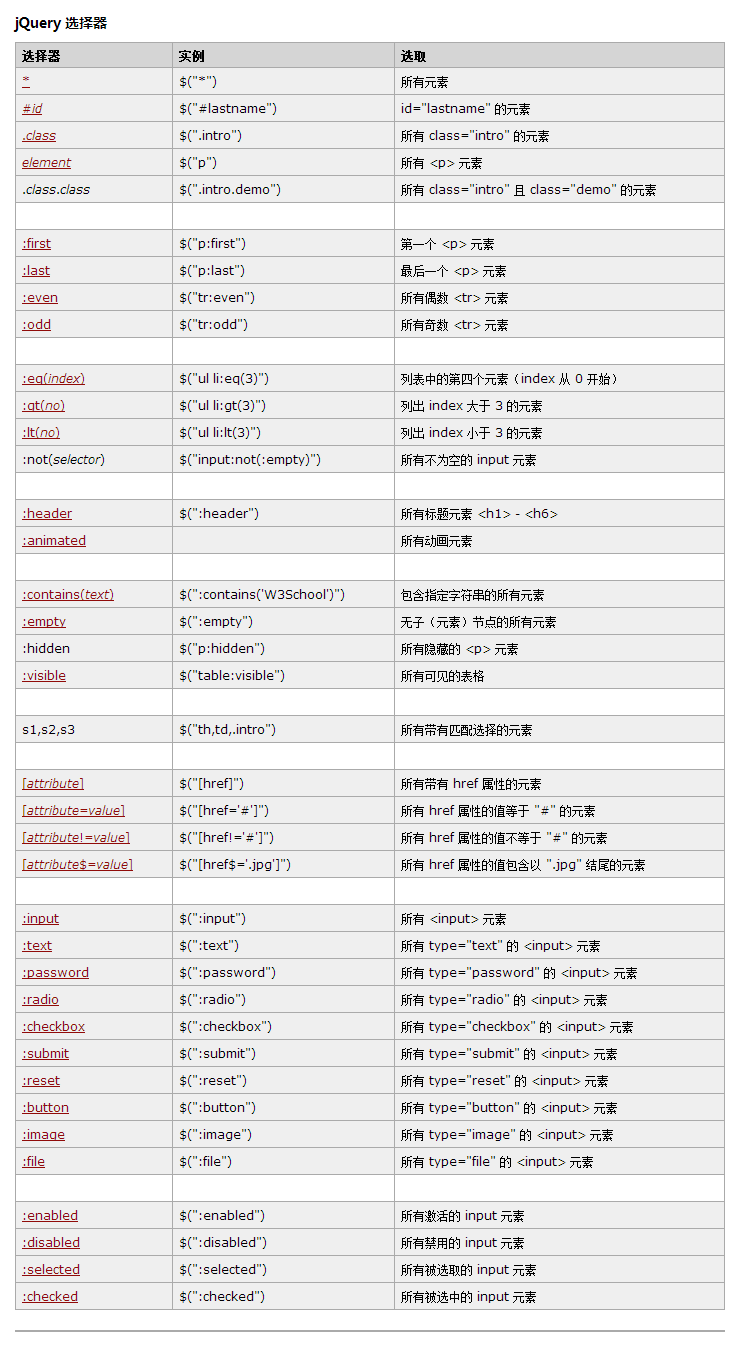
看这里这个只是一部分。大家自行百度,所以说胖鼠采集过滤功能 很强大。
这个例子在导入默认例子按钮里面有。大家可以导入自己品尝!
还有一个debug功能要告诉大家
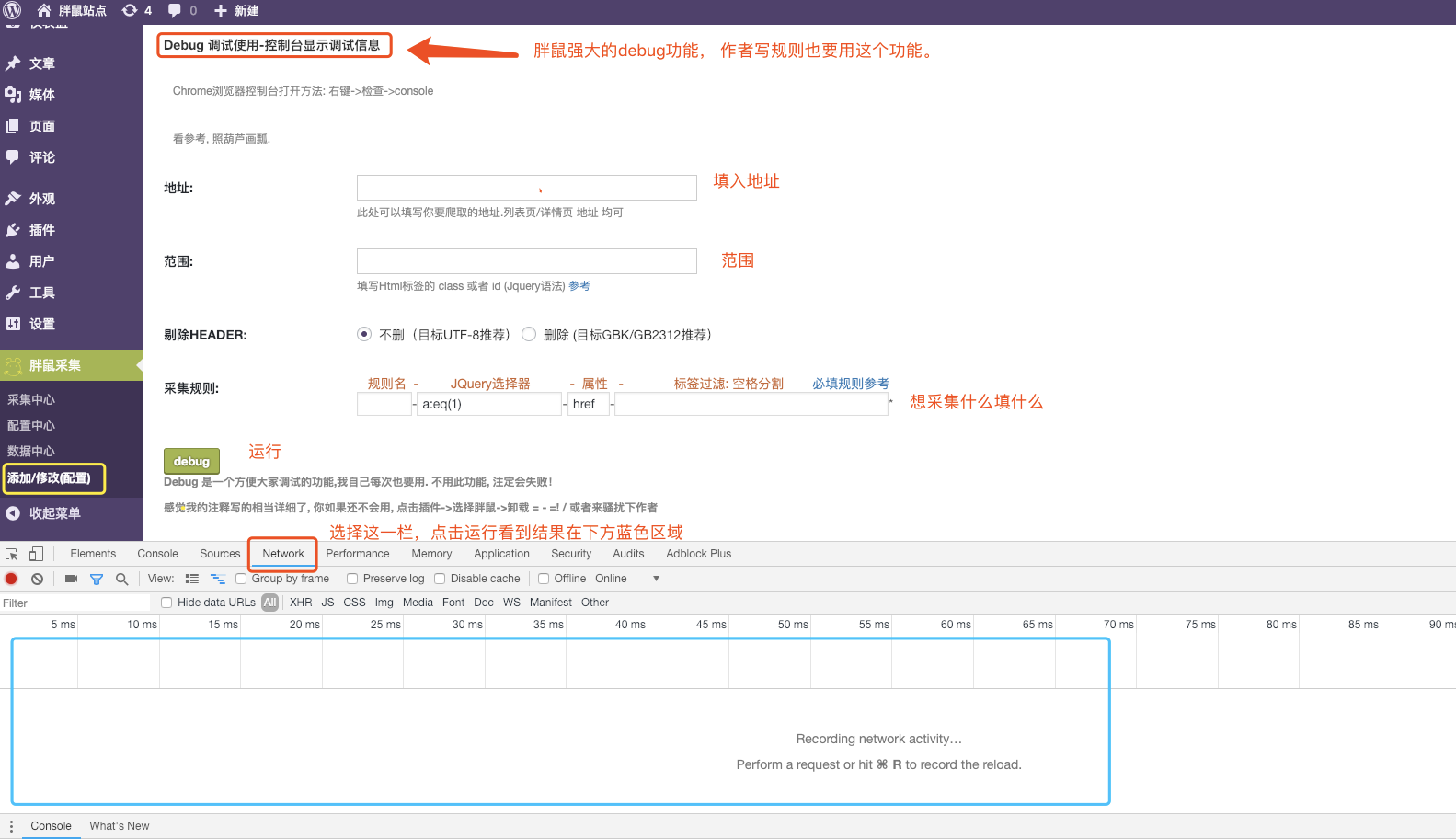
给大家实战一下
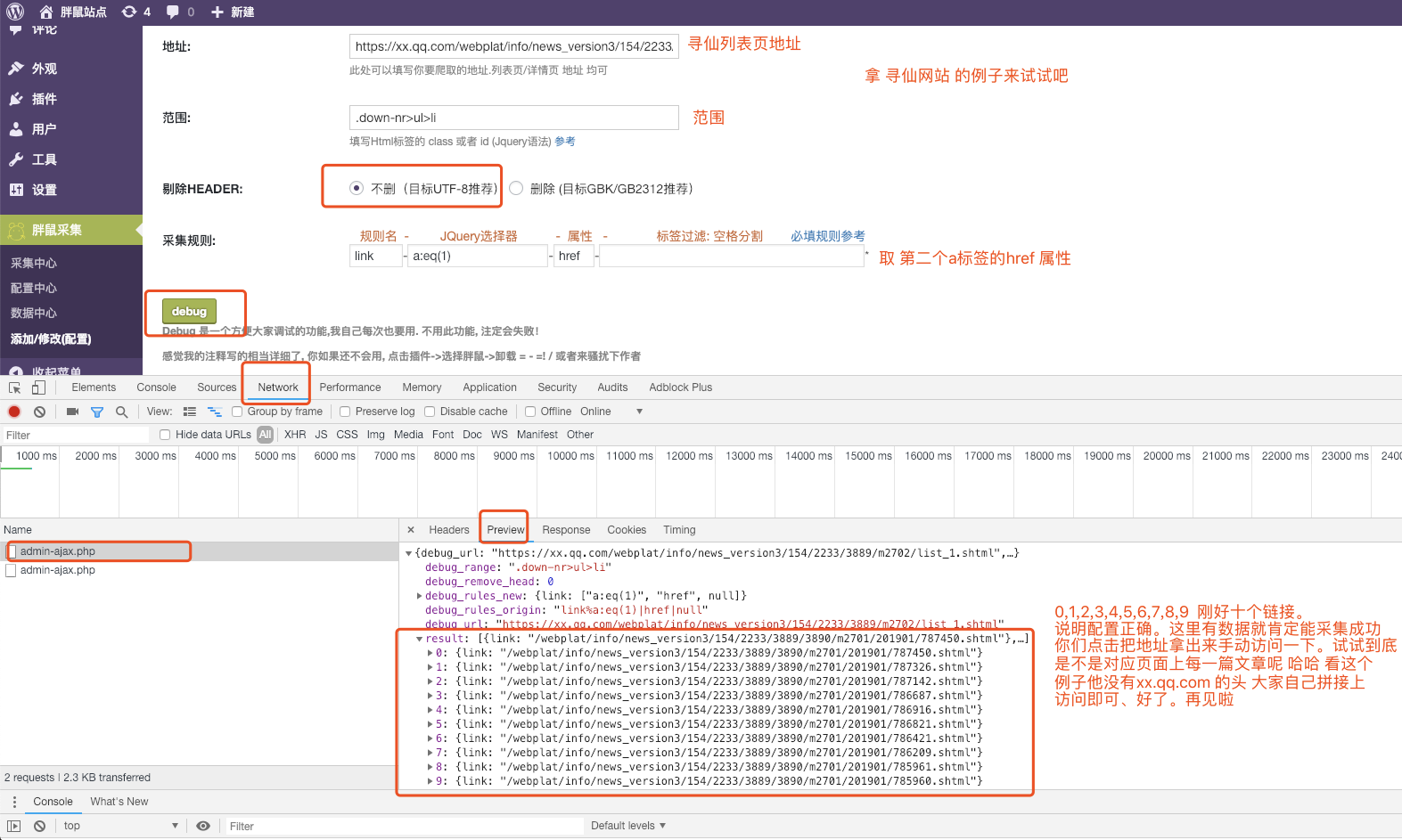
上面这个debug例子是 debug 列表页面的链接。大家要使用debug功能 测试详情页面的 标题 内容是否都获取正常了 才保存这个匹配
一次花10分钟 配一次 除了目标网站改版 就可以一直使用。希望大家花一点点时间学习一下。
推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://hqyman.cn/post/7707.html 非本站原创文章欢迎转载,原创文章需保留本站地址!

 微信支付宝扫一扫,打赏作者吧~
微信支付宝扫一扫,打赏作者吧~休息一下~~