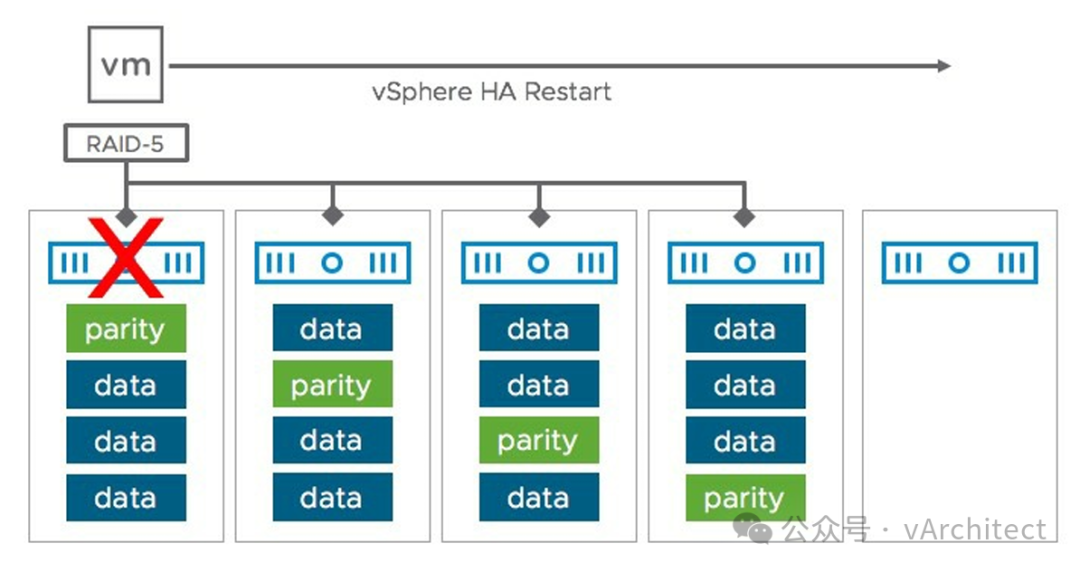
由于vSAN的高性价比,采用的用户越来越多,我接触的客户,感觉是超过了一半都使用了vSAN,但是很多客户对一些基本的概念没有理解清楚,特别在发生故障的时候,可能会导致错误的操作,造成不可挽回的结果;希望通过本文帮助大家理解vSAN如何应对故障; 每个版本的vSAN故障场景应对都稍微不同,我这里主要针对目前主流的6.7,7.0,8.0三个版本,做个比较笼统的解释。 vSAN是个目标存储,从其视角看,虚拟机磁盘就是一个目标(object),而构成目标的是多个组件(component),所谓故障对vSAN而言,就是组件出了问题,有两种不同的状态:丢失(Absent):vSAN不知道什么原因组件丢失了,最典型的情形,就是主机故障,vSAN不知道组件是真的丢失或者只是人为操作重启,当这种情形发生的时候,vSAN并不会马上进行修复,为什么这样设计,最典型的场景就是我们在给主机打补丁,为了让补丁生效,重启了服务器,服务器可能在10分钟内就恢复了,而如果vSAN马上进行修复,重建丢失的组件,将消耗大量的资源,而10分钟后这些组件又重新出现,是不是很尴尬,所以vSAN设计成,会默认等待60分钟,如果60分钟到期后,组件没有恢复,才会进行组件的修复,这个时间也叫"CLOM delay”。降级(Degraded):vSAN明确地知道组件是如何丢失的,比如磁盘永久故障(PDL),vSAN可以通过sense code明确地知道设备已经故障,这种情形下,修复不会延迟,会马上开始修复。 还有个概念需要说是“durability components”,因为没有看到过正式的翻译,我暂时将其翻译成“耐久组件”,VMware是在7.0U2后引入的这个功能,就是当发生组件丢失时,vSAN会按照虚拟机的可用性(Fault Tolerance)要求,创建耐久组件,比如虚拟机的FT=1, 那么vSAN会创建2个镜像,将虚拟最新的写入,暂时保存到这些组件中,这样的好处是确保新写入的数据也是有两个副本,可以应对其中一个副本的丢失,另外一个好处是当需要重建丢失组件时,可以直接用这个耐久组件,这样大大减少了重建组件时的消耗,所以使用6.7版本的朋友,如果没有硬件的兼容性问题,我强烈建议将平台升级到7.0U3。 假设有下图这样一个环境,中规中矩地进行了部署,某天夜里1 点有台服务器发生电源故障,如果配置得当,会发生些什么。1点:服务器电源故障,服务器立即关机,vSAN马上将故障服务器上组件标记为丢失,并开始计时,并创建持久组件,受影响的虚拟机新的写入,都存放到持久组件1点过大约1分钟:HA确认了故障,开始重启原来运行在故障虚拟机上业务,DRS根据存活的服务器资源分配了这些虚拟机的负载2点:组件丢失计时超过60分钟,vSAN开始在存活的服务器上重建丢失的组件 当晚你没有任何操作,当你第二天一早上班的时候,由于你预留的空间足够,发现组件修复已经完成,所有虚拟机的存储策略都是合规状态,你发现有一台主机和vCenter失去了连接,业务方面说昨晚1点中断了几分钟。 通过上面这个案例,还可以解释为什么我们在设计vSAN集群的时候,往往需要在所用存储策略的最小数量上,还要多加一台,比如RAID1策略,需要3台才能达成,但升级集群时,为了满足N+1的要求,确保任意一台主机故障的时候,集群还确保虚拟机使用RAID1存储策略还可以合规,如果是3台服务器,当一台故障,虽然虚拟机仍然可以访问,但其已经失去双副本保护,数据暴露在风险中。
推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://hqyman.cn/post/8935.html 非本站原创文章欢迎转载,原创文章需保留本站地址!
打赏

微信支付宝扫一扫,打赏作者吧~
休息一下~~
 HQY 一个和谐有爱的空间
HQY 一个和谐有爱的空间