
下载ollama
 https://ollama.com/
https://ollama.com/安装并验证
模型运行
启动ollama:
查看模型列表:
下载并运行本地大模型
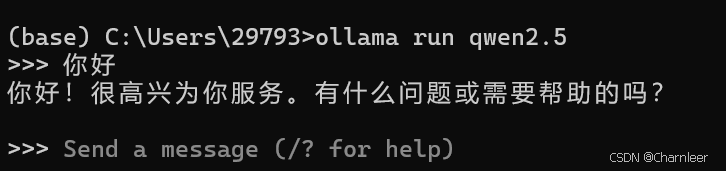
可视化界面与Ollama交互

更改模型下载位置
Set OLLAMA MODELS=E:\ollama
Set OLLAMA HOST=127.0.0.1:8000
Set OLLAMA ORIGINS=*

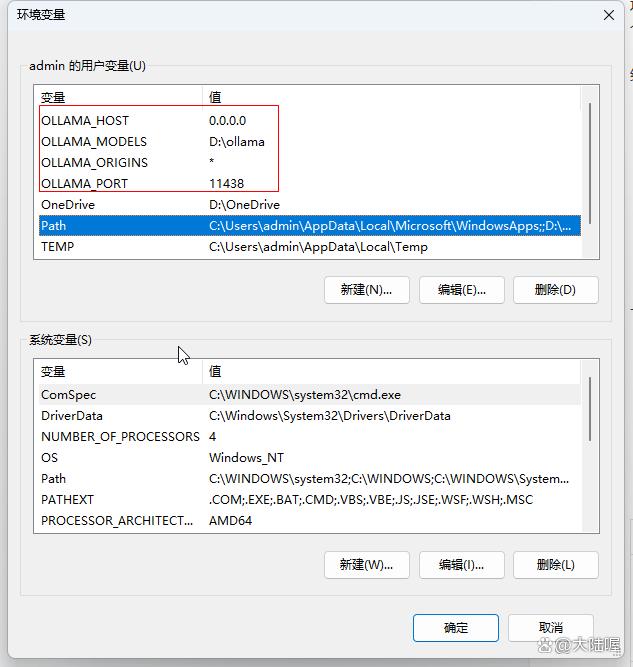
设置好之后点确定。然后电脑右下角在ollama图标上面点鼠标右键点“quit ollama”退出,再从开始菜单中重新打开ollama(也就是重启ollama),然后打开浏览器,在地址栏输入“localhost:11438”或者“127.0.0.1:11438”看是否可以正常访问,如下2张截图所示,我的终于可以成功访问了。
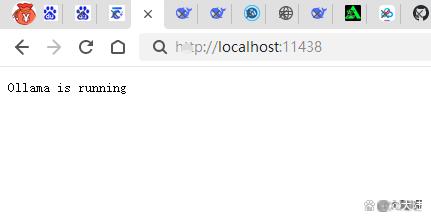 localhost访问
localhost访问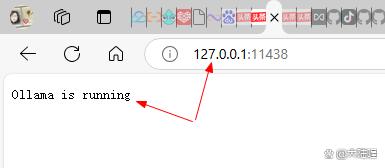
https://www.bilibili.com/video/BV1tVCMYEEhV
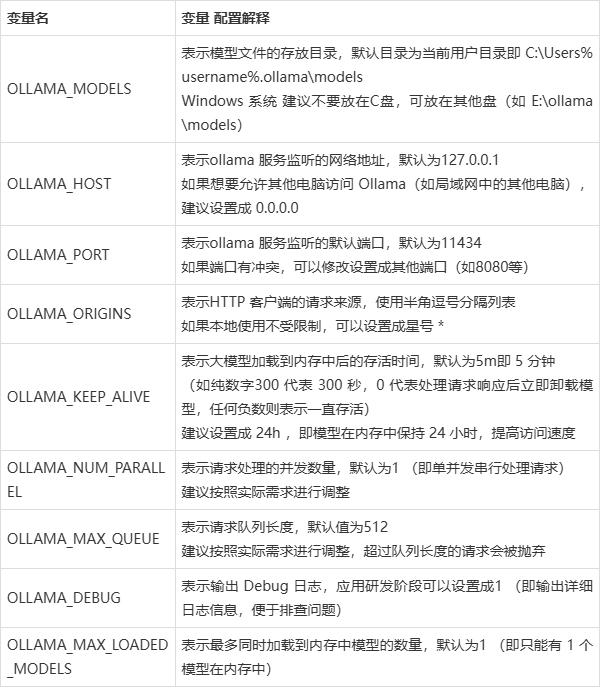
1. OLLAMA_HOST:这个变量定义了Ollama监听的网络接口。通过设置OLLAMA_HOST=0.0.0.0,我们可以让Ollama监听所有可用的网络接口,从而允许外部网络访问。
2. OLLAMA_MODELS:这个变量指定了模型镜像的存储路径。通过设置OLLAMA_MODELS=F:\OllamaCache,我们可以将模型镜像存储在E盘,避免C盘空间不足的问题。
3. OLLAMA_KEEP_ALIVE:这个变量控制模型在内存中的存活时间。设置OLLAMA_KEEP_ALIVE=24h可以让模型在内存中保持24小时,提高访问速度。
4. OLLAMA_PORT:这个变量允许我们更改Ollama的默认端口。例如,设置OLLAMA_PORT=8080可以将服务端口从默认的11434更改为8080。
5. OLLAMA_NUM_PARALLEL:这个变量决定了Ollama可以同时处理的用户请求数量。设置OLLAMA_NUM_PARALLEL=4可以让Ollama同时处理两个并发请求。
6. OLLAMA_MAX_LOADED_MODELS:这个变量限制了Ollama可以同时加载的模型数量。设置OLLAMA_MAX_LOADED_MODELS=4可以确保系统资源得到合理分配。
7.OLLAMA_ORIGINS,值填*
"允许的来源列表(以逗号分隔)"
推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://hqyman.cn/post/8986.html 非本站原创文章欢迎转载,原创文章需保留本站地址!

 微信支付宝扫一扫,打赏作者吧~
微信支付宝扫一扫,打赏作者吧~休息一下~~