
【AI大模型】本地部署Ollama+翻译服务
还在因为Google翻译经常死机而感到烦恼吗,还在因为一些软件大段文字翻译拉垮而感到烦躁吗,还在因为一些ai翻译服务付费而感到无力吗!
非常浮夸的开头hhh
这些天的deepseek杀疯了,到处都是关于deepseek的新闻。deepseek全网参与度如此之高,有一个很大的原因就是他开源了从1.5B-671B的各种大小的量化蒸馏模型,掀起了一阵本地部署大模型的浪潮。(谁不想要一个自己的贾维斯呢~)(虽然现在本地模型离贾维斯还挺远的)
这篇文章就是记录一下我的本地大模型部署过程,并且用它来做翻译的全教程。
部署结果展示
pyside6编写的本地翻译软件界面程序
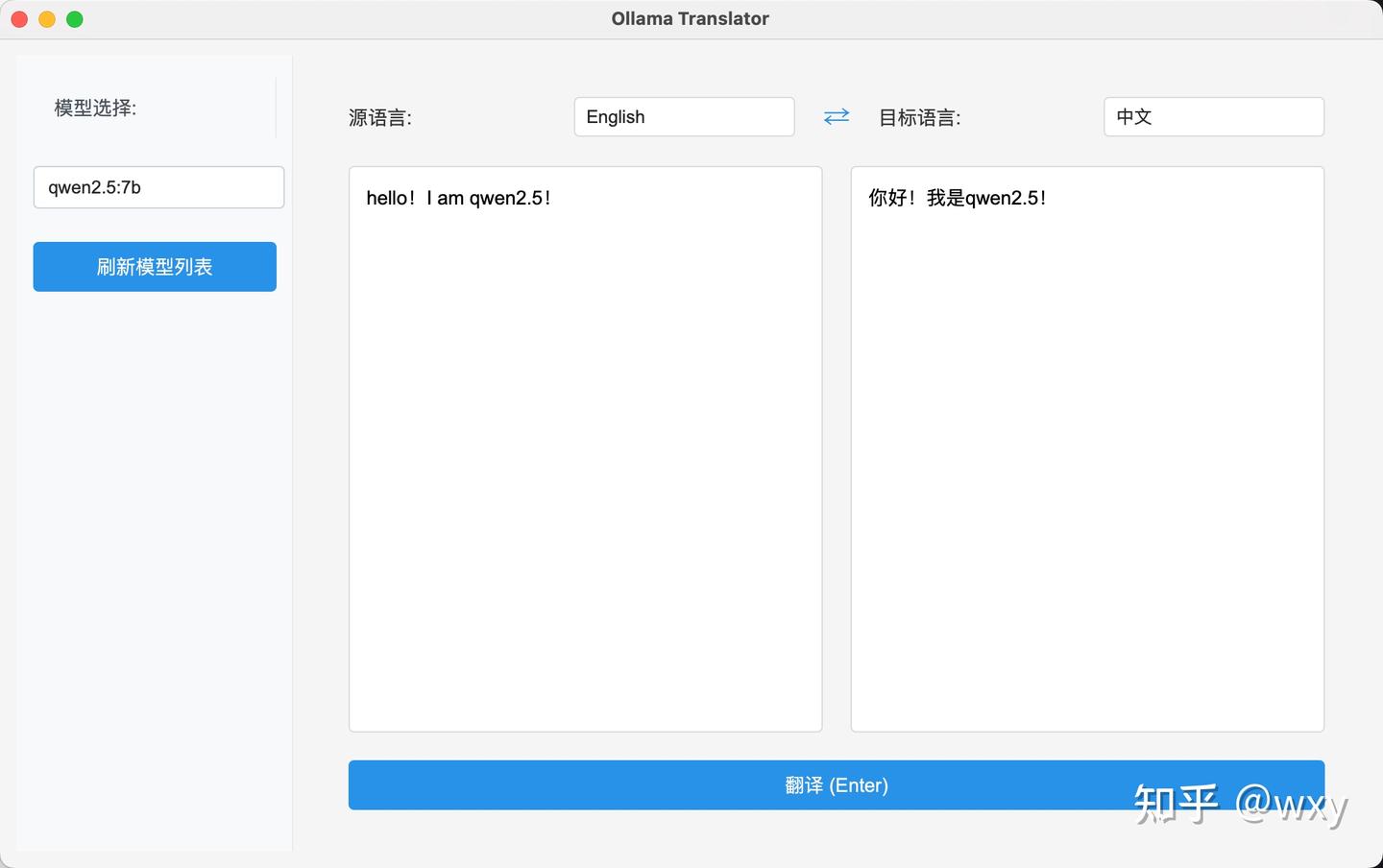
核心内容
核心的思想其实就是两个部分(第三个部分是附加题,这篇不讲 ):
一个可以运行大模型的容器(Ollama)
一个可以实现和大模型交互的界面
附加:给大模型上工具,联网搜索、本地知识库等(Open-WebUI)
现在可以实现这三个功能的开源软件太多了(感谢各位大佬们的贡献!)
硬件基础
列一下我使用的硬件:macbook pro m1pro 8core,16GB内存
感觉容量比较重要,先整个放下,然后速度才主要受限于运算速度,不然就会反复io,速度巨慢
1 Ollama安装+大模型部署
说是部署其实还挺羞耻的,没几步,大佬们都帮忙搞得很好了,几乎开箱就用。先去官网:

下载对应系统的软件,然后按照指示安装就可以了
全部安装完成就可以在自己的命令行使用ollama命令,然后就可以挑语言模型进行下载了
在这个网址Ollama里面就可以挑到大量开源模型,如果还想要更多,还可以去hugging face上找,挑到自己喜欢的。
注意有一类是embedding,这类模型不是我们常见的那种对话的语言模型,而是用来把文件编码成大模型能看懂的模型,之后关于部署本地知识库+大模型的文章里可以再说。
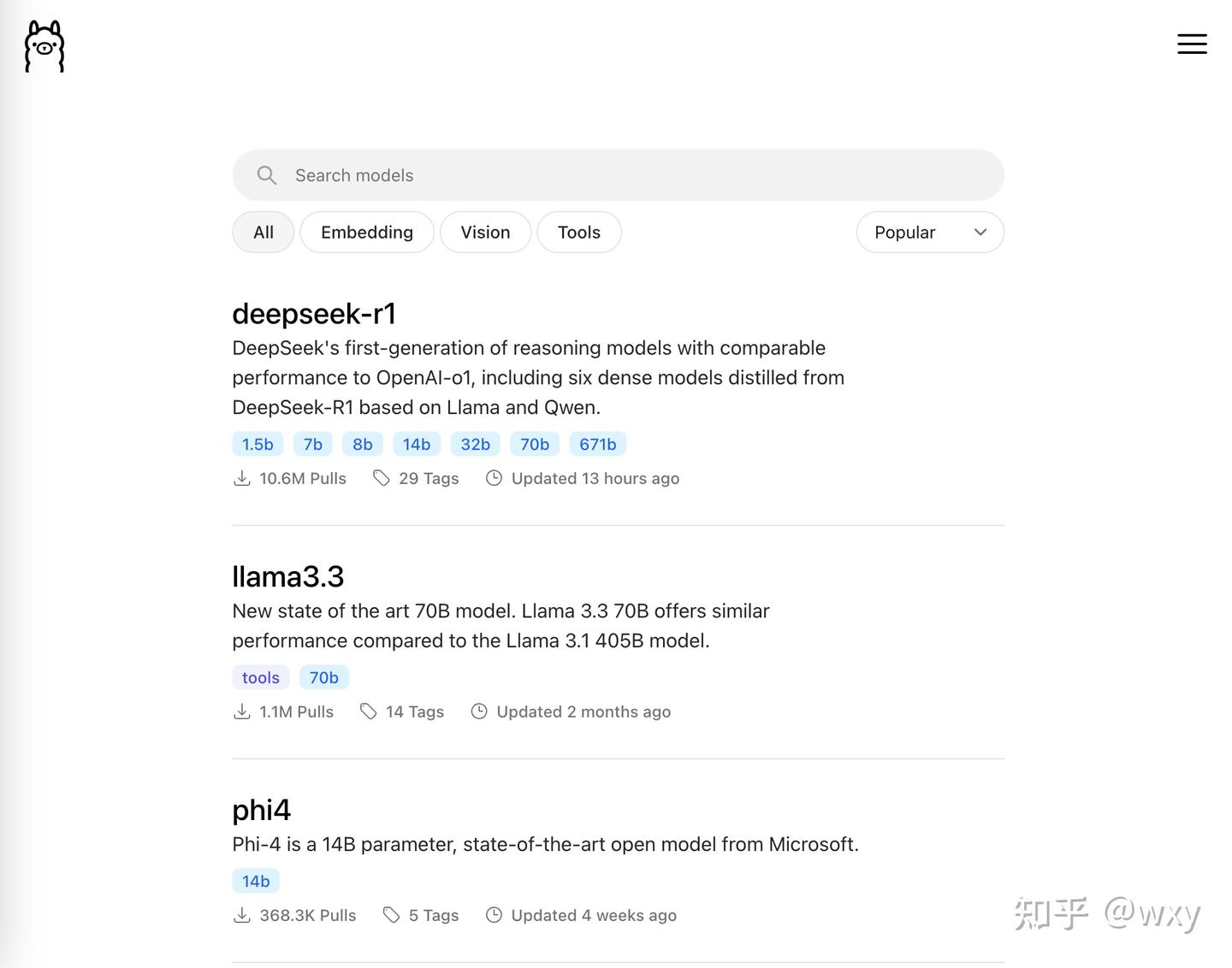
我的macbook是16GB内存,基本上14B的模型是个极限,响应比较慢(在量化Q4基础上)。感兴趣都可以下下来玩,我选择的是qwen2.5:7B,用来做翻译足够足够的了。
点开模型卡,就可以找到下载的命令行代码
ollama run qwen2.5:7b
# 或者下面这个也可以,目的是把参数下载下来
ollama pull qwen2.5:7b经过一段时间的下载(这个看网速了)ollama就会告诉你,模型准备好了
这个时候其实本地的模型已经可以使用了,可以通过终端调用它。

这样其实就算搞定了。
deepseek也是一样的,我这边下的也是7b量化模型

deepseek不一样的地方就是会有两个think的标签,这个部分的内容就是表示它自己在思考,外面的信息才是它的正式回复。
2 翻译软件
很多软件其实都支持部署本地大模型接入的,比如zotero,pot,bob这些软件都可以。ollama本地部署的逻辑和openai的api部署逻辑是类似的。
界面我摸鱼整了一个,界面用pyside6开发,代码几乎都是ai写的,效果还不错,核心的和大模型沟通部分的代码如下
import jsonimport requestsfrom typing import Optional, Dict, Anyclass TranslatorService:
def __init__(self):
self.base_url = "http://localhost:11434/api"
def get_available_models(self) -> list:
"""获取可用的模型列表"""
try:
response = requests.get(f"{self.base_url}/tags")
if response.status_code == 200:
return response.json().get('models', [])
return []
except Exception:
return []
def translate(self,
text: str,
source_lang: str,
target_lang: str,
model: str,
temperature: float = 0.7,
top_p: float = 0.9) -> str:
"""执行翻译请求"""
if not text or not model:
return ""
prompt = f"Translate the following {source_lang} text to {target_lang}. Output the translation only without any explanations or additional context:\n{text}"
try:
response = requests.post(
f"{self.base_url}/generate",
json={
"model": model,
"prompt": prompt,
"stream": False,
"options": {
"temperature": temperature,
"top_p": top_p
}
}
)
if response.status_code == 200:
return response.json().get('response', '')
return f"翻译失败: HTTP {response.status_code}"
except Exception as e:
return f"翻译失败: {str(e)}"这个部分就是和本地的11434端口部署的ollama服务去做交互,如何给他提示词prompt就可以。7b的模型执行的很不错,翻译上没什么问题。如果使用deepseek模型做翻译,就需要写一段代码去让输出的部分忽略掉think标签里面的东西。
代码和macos上打包好的(m系列芯片)通过网盘分享的文件:源码+macos平台.zip
链接: https://pan.baidu.com/s/1U5BYgM0FL_yNIWcCyT4N0g?pwd=cu9b 提取码: cu9b
源码需要运行的话需要下载一下pyside6和request,可以用conda+pip install
运行流程上就是先安装anaconda
然后创建环境
conda create -n ts python==3.11.0
# 安装依赖
pip install pyside6
pip install request
# 进入目录运行main文件
python main.py很简单的界面就搞定了,用这个就可以相对优雅的和大模型进行交互了。当然有更优雅的方法,比如open-webui等这些开发的非常好的界面,这个也可以后面讲。
本期封面来自openai DALL.E
推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://hqyman.cn/post/9066.html 非本站原创文章欢迎转载,原创文章需保留本站地址!

 微信支付宝扫一扫,打赏作者吧~
微信支付宝扫一扫,打赏作者吧~休息一下~~