
MySQL为什么 不用 Docker部署?
MySQL为什么不推荐使用Docker部署

本文目录
- 尼恩说在前面
- MySQL为什么不推荐使用Docker部署
- 第一大问题:DB有状态,不方便扩容
- 1.1 Docker容器的两大类型: 有状态 、无状态的区分
- 1.2 Mysql 是有状态的,不方便扩容
- 1.3 为什么 MySQL 是有状态的?
- 1.4 容器化部署mysql 带来的扩容困境
- 1.5 使用Docker在本地部署 两个MySQL实例
-1. 创建2套存储目录
-2. 配置2套MySQL
-3. 启动2套MySQL容器
- 1.6 如何实现文件1和文件2的数据共享呢?
- 1.7 MySQL 容器的状态问题 总结
- 第二大问题:Docker 的资源隔离,不彻底
- 第三大问题:Docker不适合于 磁盘IO密集型的中间件
- 4 Docker的优势
- 4.1. 自动伸缩
-水平伸缩
-垂直伸缩 - 4.2. 容灾
-自动重启
-高可用性
- 4.3. 其他优势
-开发与生产一致性
-快速部署
-隔离性 - 4.4. Docker的优势总结
- 5 总结:大型 Mysql 为何不用 docker部署?
- 5.1 性能方面
- 5.2 管理与维护方面
- 5.3 稳定性与可靠性方面
- 6 Share Nothing 架构
- 6.1 为什么需要 Share Nothing 架构
- 6.2 Share Nothing 架构的应用场景
- 6.3 Share Nothing 架构的实现
-1. 数据分布
-2. 数据一致性
-3. 故障恢复
- 6.4 现在互联网的数据库多是share nothing的架构
- 7 当然 小型的mysql ,还是可以用docker部署的
- 说在最后:有问题找老架构取经
第一大问题:DB有状态,不方便扩容
1.1 Docker容器的两大类型: 有状态 、无状态的区分
1.2 Mysql 是有状态的,不方便扩容
1.3 为什么 MySQL 是有状态的?
数据持久化:MySQL 需要将数据存储在磁盘上,以便在容器重启后数据仍然存在。 配置文件:MySQL 的配置文件(如 my.cnf)也需要持久化,以便在容器重启后仍然生效。日志文件:MySQL 的日志文件(如错误日志、二进制日志等)也需要持久化,以便在需要时进行故障排查和数据恢复。
mkdir -p /data/mysql/{data,logs,conf}
docker pull mysql:latest
/data/mysql/conf 目录下,创建一个名为 my.cnf 的配置文件,用于设置MySQL的字符集、排序规则等参数:
[mysqld]
character-set-server=utf8mb4
collation-server=utf8mb4_unicode_ci
datadir=/var/lib/mysql
log-error=/var/log/mysqld.log
docker run -d \
--name mysql-server \
-p 3306:3306 \
-e MYSQL_ROOT_PASSWORD=your_password \
-v /data/mysql/data:/var/lib/mysql \
-v /data/mysql/logs:/var/log/mysqld \
-v /data/mysql/conf/my.cnf:/etc/mysql/my.cnf \
mysql:latest
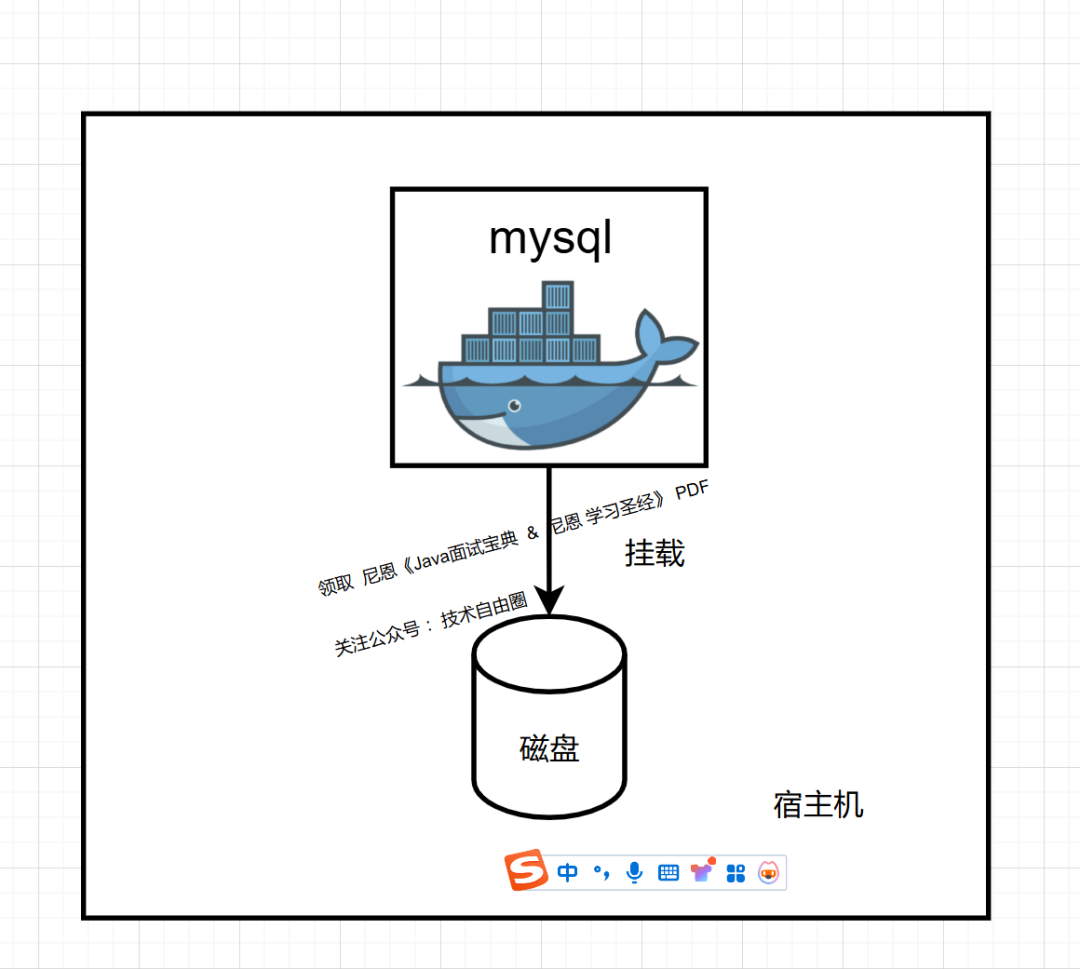
1.4 容器化部署mysql 带来的扩容困境
不要将数据储存在容器中,这也是 Docker 官方容器使用技巧中的一条。 容器随时可以停止、或者删除。 当容器被rm掉,容器里的数据将会丢失。为了避免数据丢失,用户可以使用数据卷挂载来存储数据。
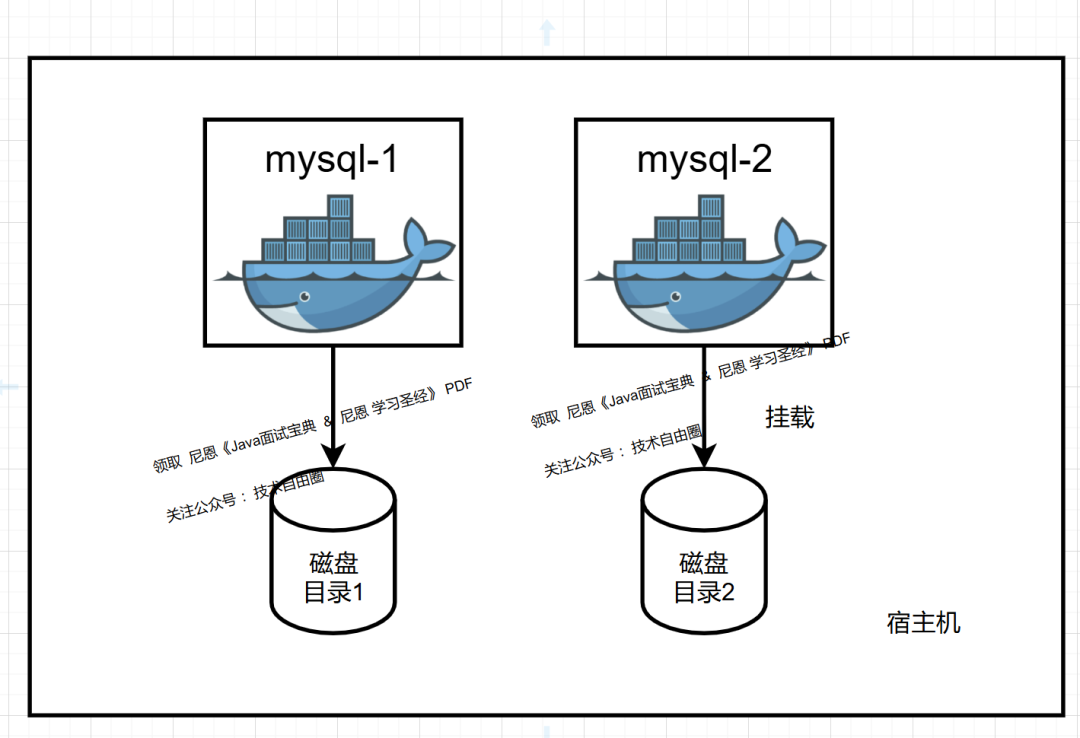
1.5 使用Docker在本地部署 两个MySQL实例
1. 创建2套存储目录
mkdir -p /data/mysql1/{data,logs,conf}
mkdir -p /data/mysql2/{data,logs,conf}
2. 配置2套MySQL
my.cnf 的配置文件,用于设置MySQL的字符集、排序规则等参数:/data/mysql1/conf/my.cnf):
[mysqld]
character-set-server=utf8mb4
collation-server=utf8mb4_unicode_ci
datadir=/var/lib/mysql
log-error=/var/log/mysqld.log
/data/mysql2/conf/my.cnf):
[mysqld]
character-set-server=utf8mb4
collation-server=utf8mb4_unicode_ci
datadir=/var/lib/mysql
log-error=/var/log/mysqld.log
3. 启动2套MySQL容器
docker run -d \
--name mysql1 \
-p 3306:3306 \
-e MYSQL_ROOT_PASSWORD=your_password1 \
-v /data/mysql1/data:/var/lib/mysql \
-v /data/mysql1/logs:/var/log/mysqld \
-v /data/mysql1/conf/my.cnf:/etc/mysql/my.cnf \
mysql:latest
docker run -d \
--name mysql2 \
-p 3307:3306 \
-e MYSQL_ROOT_PASSWORD=your_password2 \
-v /data/mysql2/data:/var/lib/mysql \
-v /data/mysql2/logs:/var/log/mysqld \
-v /data/mysql2/conf/my.cnf:/etc/mysql/my.cnf \
mysql:latest
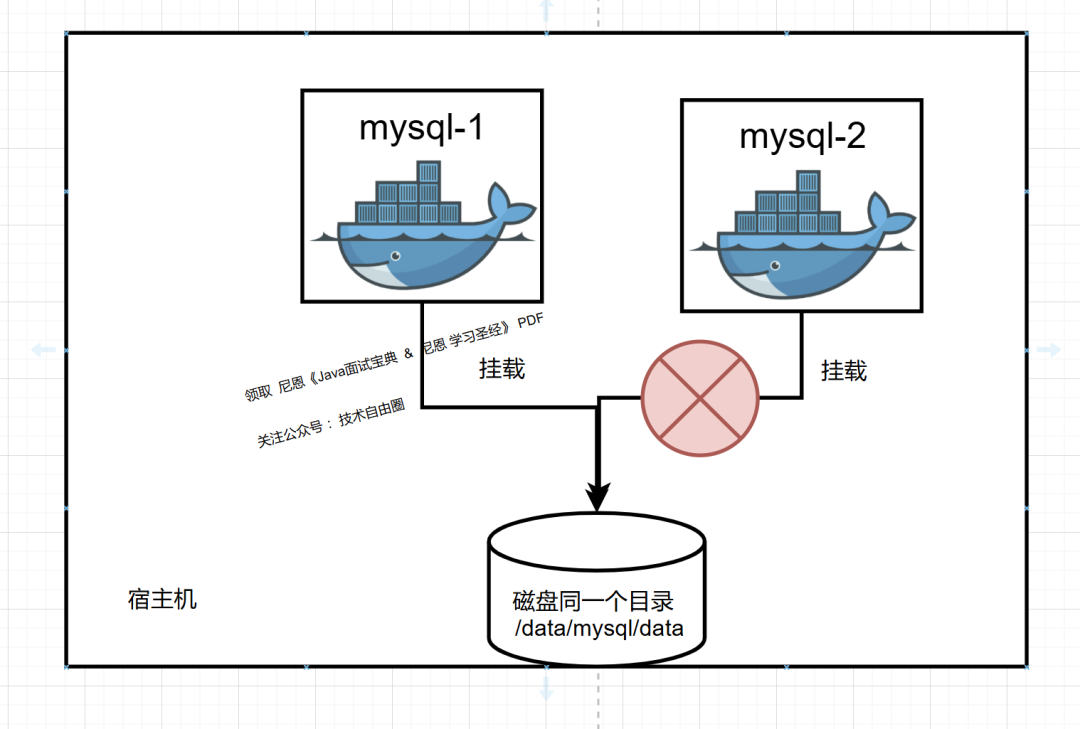
1.6 如何实现文件1和文件2的数据共享呢?
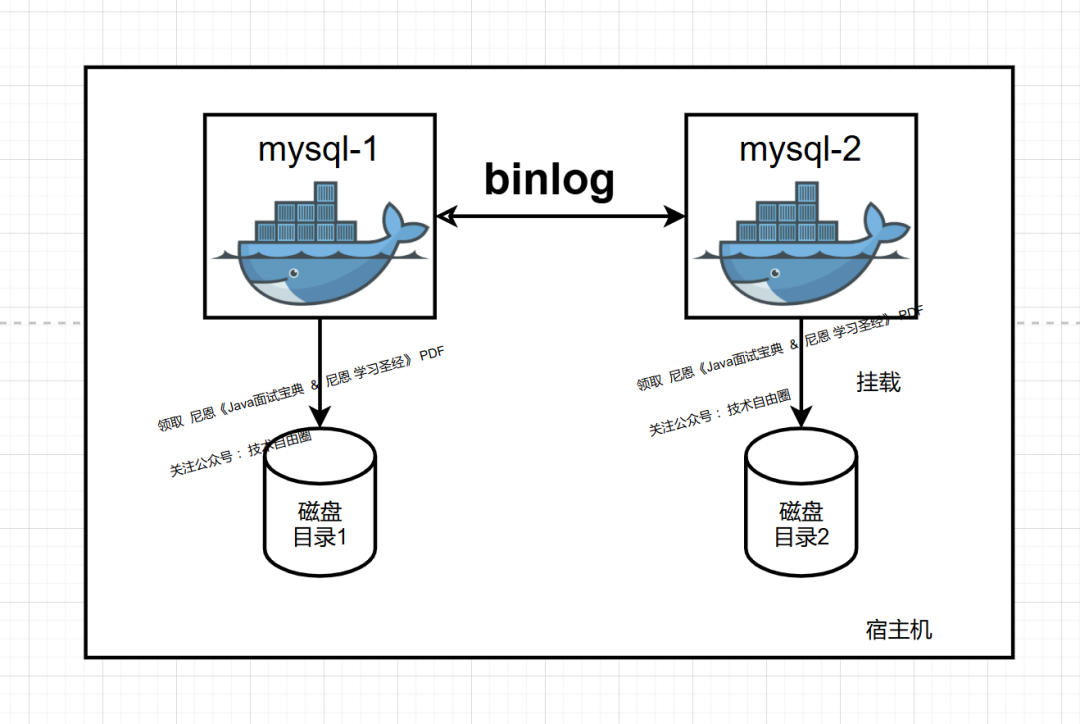
1.7 MySQL 容器的状态问题 总结
第二大问题:Docker 的资源隔离,不彻底
Docker只是限制资源消耗的最大值,而不能隔绝其他程序占用自己的资源。 Docker 并没有真正、彻底的隔离CPU、内存。
第三大问题:Docker不适合于 磁盘IO密集型的中间件
4 Docker的优势
4.1. 自动伸缩
水平伸缩
当业务流量高峰时,自动增加容器数量来处理更多请求,避免因资源不足导致服务卡顿或崩溃; 流量低谷时,自动减少容器数量,释放多余资源,避免资源浪费,从而实现资源的高效利用,降低成本。
version: '3'
services:
web:
image: my-web-app
deploy:
replicas: 3
update_config:
parallelism: 2
delay: 10s
restart_policy:
condition: on-failure
垂直伸缩
version: '3'
services:
web:
image: my-web-app
deploy:
resources:
limits:
cpus: '0.50'
memory: 50M
reservations:
cpus: '0.25'
memory: 20M
4.2. 容灾
docker run -d \
--name mysql-server \
-p 3306:3306 \
-e MYSQL_ROOT_PASSWORD=your_password \
-v /data/mysql/data:/var/lib/mysql \
mysql:latest
自动重启
定义:在容器故障时自动重启容器。 实现:Docker 提供了 --restart选项,可以设置容器在失败时自动重启。示例: bash复制 docker run -d \
--name my-app \
--restart=always \
my-app-image
高可用性
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 3
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-app
image: my-app-image
4.3. 其他优势
开发与生产一致性
FROM node:14
WORKDIR /app
COPY package*.json ./
RUN npm install
COPY . .
CMD ["npm", "start"]
快速部署
docker run -d --name my-app my-app-image
隔离性
docker run -d --name my-app1 my-app-image
docker run -d --name my-app2 my-app-image
4.4. Docker的优势总结
5 总结:大型 Mysql 为何不用 docker部署?
5.1 性能方面
5.2 管理与维护方面
5.3 稳定性与可靠性方面
6 Share Nothing 架构
6.1 为什么需要 Share Nothing 架构
高可扩展性:由于每个节点都是独立的,可以通过增加更多的节点来水平扩展系统,而不需要担心资源竞争。 高可用性:单个节点的故障不会影响其他节点的运行,从而提高了系统的整体可用性。 低延迟:每个节点都可以独立处理请求,减少了数据传输的延迟,提高了系统的响应速度。
6.2 Share Nothing 架构的应用场景
分布式数据库:如 MySQL Cluster、Cassandra、CockroachDB 等,这些数据库通过将数据分布在多个节点上,实现了高可用性和高扩展性。 分布式计算框架:如 Hadoop、Spark 等,这些框架通过将计算任务分布在多个节点上,实现了高效的分布式计算。 微服务架构:每个微服务可以独立部署和扩展,互不干扰,从而提高了系统的灵活性和可维护性。
6.3 Share Nothing 架构的实现
1. 数据分布
2. 数据一致性
3. 故障恢复
6.4 现在互联网的数据库多是share nothing的架构
Cassandra:是一款分布式 NoSQL 数据库,具有高度可扩展性和容错性,广泛应用于大规模分布式数据存储和处理场景。 MongoDB:文档型数据库,支持水平扩展,通过数据分片技术实现 Share Nothing 架构,适用于存储和处理非结构化和半结构化数据。 Hadoop HDFS:Hadoop 分布式文件系统,是 Hadoop 生态系统的核心组件之一,采用 Share Nothing 架构实现大规模数据的分布式存储和管理。
7 当然 小型的mysql ,还是可以用docker部署的
推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://hqyman.cn/post/9132.html 非本站原创文章欢迎转载,原创文章需保留本站地址!

 微信支付宝扫一扫,打赏作者吧~
微信支付宝扫一扫,打赏作者吧~休息一下~~