

一、vLLM框架深度解析
1. 框架定位与核心目标
2. 核心技术:PagedAttention
3. 关键性能优势
4. 性能对比数据
| 框架 | 吞吐量 (tokens/s) | 显存利用率 |
|---|---|---|
| HuggingFace | 45 | 38% |
| Text Generation Inference | 112 | 65% |
| vLLM | 1075 | 99% |
二、 PagedAttention核心技术
1. 设计动机:KVCache 的显存管理困境
1.1 KVCache 的作用
1.2 传统方法的瓶颈
2. 核心原理:分块管理与页表机制
2.1 分块设计
2.2 页表(Block Table)
2.3 注意力计算优化
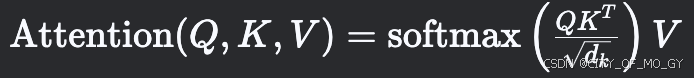
3. 实现细节与性能优化
3.1 块大小选择
3.2 物理块池管理
3.3 并行与锁机制
4. 性能对比与实测数据
4.1 显存利用率提升
| 场景 | 传统方法显存占用 | PagedAttention显存占用 |
|---|---|---|
| 单序列(长度 512) | 2.1 GB | 2.1 GB(无优势) |
| 100并发序列(平均长度 300) | 210 GB(预分配) | 63 GB(动态分配) |
4.2 吞吐量对比
5. 传统方法导致过度预分配的原因解析
1. KVCache 的存储特性
1.1 KVCache 的显存占用公式
2×1×512×32×128=4,194,304 元素≈16.78 MB(float16)
2. 传统方法的显存分配逻辑
2.1 连续显存分配要求
2×1×2048×32×128≈67.11 MB
3002048≈14.6%
2.2 显存碎片化的数学解释
3. 过度预分配的根源
3.1 长尾效应与安全冗余
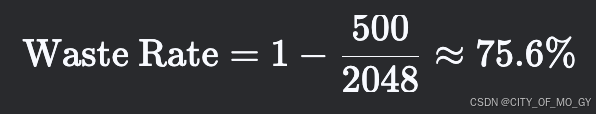

3.2 显存预留的“停车场悖论”
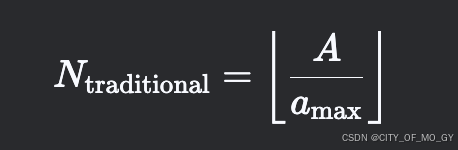
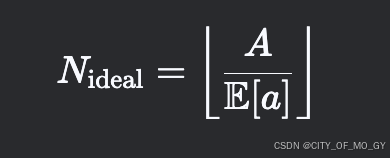
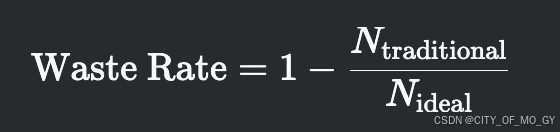
4. 传统方法 vs. PagedAttention 的显存利用率对比
4.1 传统方法显存分配
Mtraditional=b×smax×c
Mtraditional=100×2048×0.033≈6,758 MB≈6.6 GB
4.2 PagedAttention 显存分配
Mpaged=⌈b×E[s]\block_size⌉×block_size×c
总块数=⌈100×300\16⌉=1,875 块
Mpaged=1,875×16×0.033≈990 MB≈0.97 GB
4.3 对比结果
| 方法 | 显存占用 | 利用率提升倍数 |
|---|---|---|
| 传统方法 | 6.6 GB | 1x(基线) |
| PagedAttention | 0.97 GB | 6.8x |
三、总结
推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://hqyman.cn/post/9149.html 非本站原创文章欢迎转载,原创文章需保留本站地址!

 微信支付宝扫一扫,打赏作者吧~
微信支付宝扫一扫,打赏作者吧~休息一下~~