
0x01 传统Pcie与NVLink
1. PCIe(Peripheral Component Interconnect Express):它是一种计算机总线标准,用于在计算机内部连接各种设备和组件(例如显卡、存储设备、扩展卡等)。PCIe接口以串行方式传输数据,具有较高的通信带宽,适用于连接各种设备。然而,由于其基于总线结构,同时连接多个设备时可能会受到带宽的限制。
2. NVLink(Nvidia Link):它是由NVIDIA开发的一种高速、低延迟的专有连接技术,主要用于连接NVIDIA图形处理器(GPU)。NVLink提供了具有很高带宽和低延迟的直接GPU间通信能力,多个GPU通过英伟达SXM封装技术封装在一起,使得多个GPU可以在更紧密和高效的方式下协同工作。相比于PCIe,NVLink在支持GPU之间的数据传输和协作方面提供了更好的性能和效率。
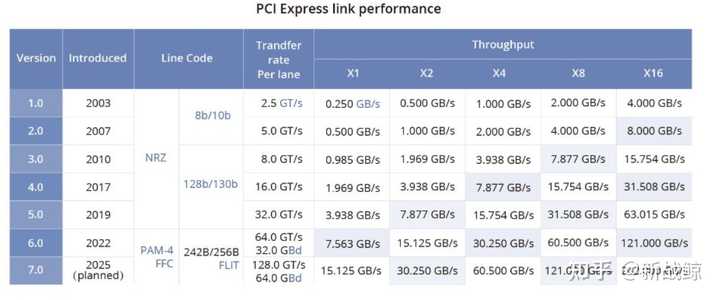
pcie带宽
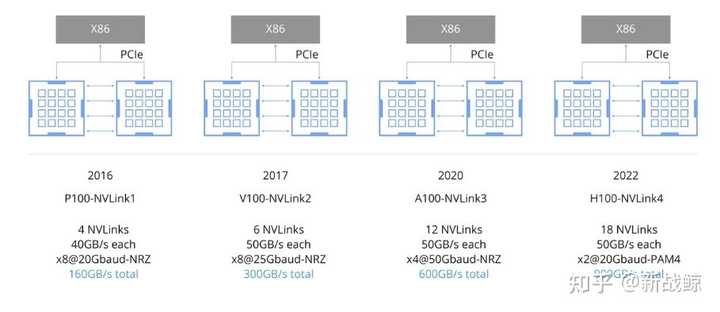
nvlink带宽
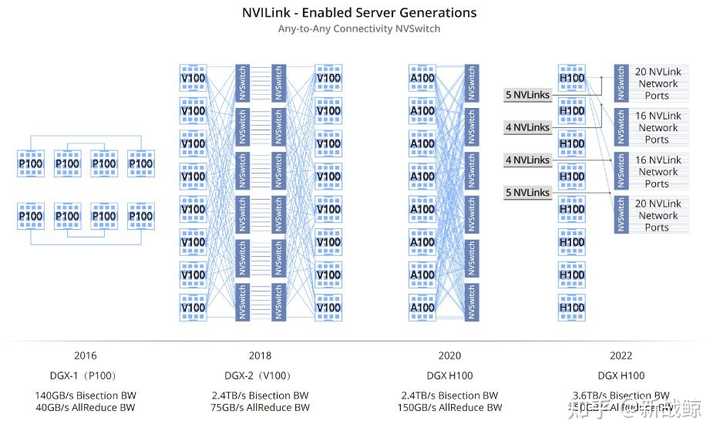
DGX服务器带宽
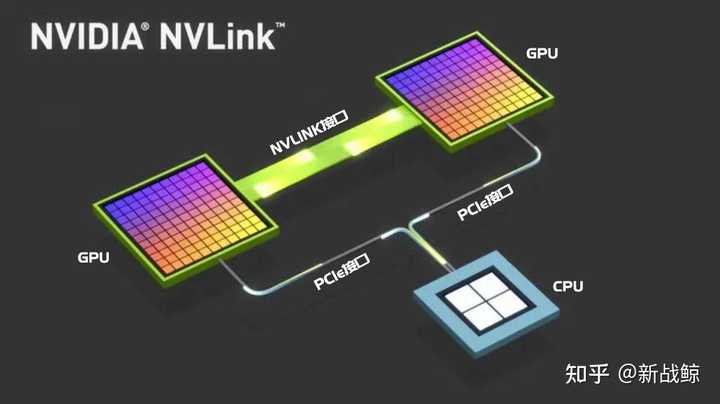
非凡带宽
0x02 历史
NVLink技术是在2014年3月的NVIDIA GTC 2014上发布的。对普通消费者来说,这一届的GTC似乎没有太多的亮点,也没有什么革命性的产品发布。这次GTC上,黄仁勋展示了新一代单卡双芯卡皇GeForce Titan Z,下一代GPU架构Pascal也只是初露峥嵘。在黄仁勋演讲中只用大约五六页PPT介绍的NVLink也很容易被普通消费者忽视,但是有心的专业人士确从此举看到了NVIDIA背后巨大的野心。
简单看下NVIDIA对NVLink的介绍:NVLink能在多GPU之间和GPU与CPU之间实现非凡的连接带宽。带宽有多大?2016发布的P100是搭载NVLink的第一款产品,单个GPU具有160GB/s的带宽,相当于PCIe Gen3 * 16带宽的5倍。GTC 2017上发布的V100搭载的NVLink 2.0更是将GPU带宽提升到了300G/s,差不多是PCIe的10倍了。
0x03 结构和拓扑
3.1 NVLink信号与协议
NVLink控制器由3层组成,即物理层(PHY)、数据链路层(DL)以及交易层(TL)。下图展示了P100 NVLink 1.0的各层和链路:
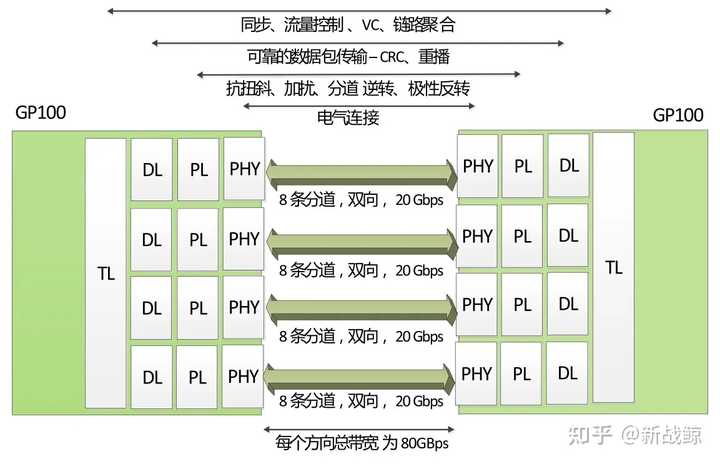
P100搭载的NVLink 1.0,每个P100有4个NVLink通道,每个拥有40GB/s的双向带宽,每个P100可以最大达到160GB/s带宽。
V100搭载的NVLink 2.0,每个V100增加了50%的NVLink通道达到6个,信号速度提升28%使得每个通道达到50G的双向带宽,因而每个V100可以最大达到300GB/s的带宽。
3.2 拓扑
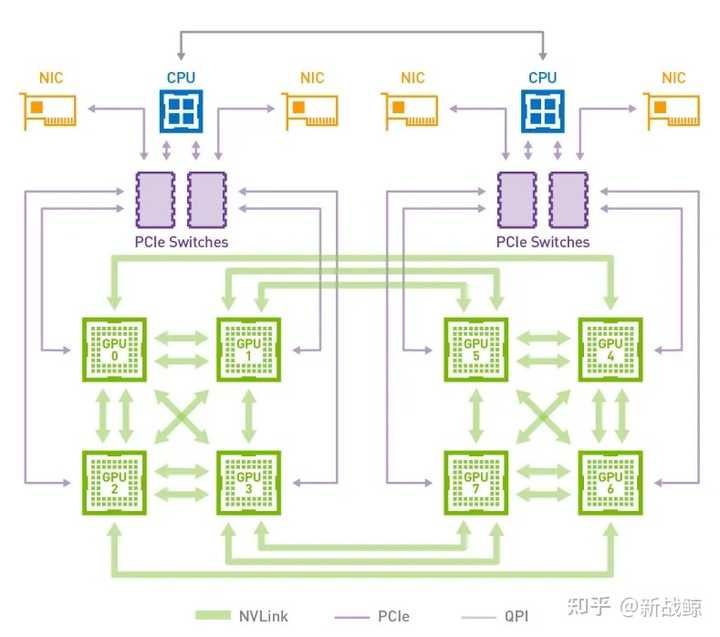
下图是HGX-1/DGX-1使用的8个V100的混合立方网格拓扑结构,我们看到虽然V100有6个NVlink通道,但是实际上因为无法做到全连接,2个GPU间最多只能有2个NVLink通道100G/s的双向带宽。而GPU与CPU间通信仍然使用PCIe总线。CPU间通信使用QPI总线。这个拓扑虽然有一定局限性,但依然大幅提升了同一CPU Node和跨CPU Node的GPU间通信带宽。
3.3 NVSwitch
为了解决混合立方网格拓扑结构的问题,NVIDIA在GTC 2018上发布了NVSwitch。
为了解决混合立方网格拓扑结构的问题,NVIDIA在今年GTC 2018上发布了NVSwitch。
类似于PCIe使用PCIe Switch用于拓扑的扩展,NVIDIA使用NVSwitch实现了NVLink的全连接。NVSwitch作为首款节点交换架构,可支持单个服务器节点中 16 个全互联的 GPU,并可使全部 8 个 GPU 对分别以 300 GB/s 的惊人速度进行同时通信。这 16 个全互联的 GPU (32G显存V100)还可作为单个大型加速器,拥有 0.5 TB 统一显存空间和 2 PetaFLOPS 计算性能。
关于NVSwitch的相关技术细节可以参考NVIDIA官方技术文档。应该说这一技术的引入,使得GPU间通信的带宽又大大上了一个台阶。
性能
NVIDIA NVLink 将采用相同配置的服务器性能提高 31%。
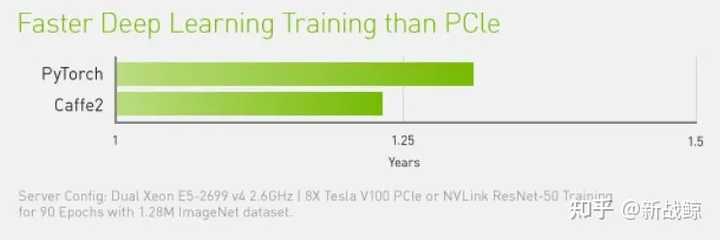
使用NVSwitch的DGX-2则能够达到2倍以上的深度学习和高性能计算的加速。
0xff 参考链接
浅析GPU通信技术(中)-NVLink-阿里云开发者社区 (aliyun.com)
nvidia nvlink互联与nvswitch介绍_nvidia nvlink互联与nv switch介绍-CSDN博客
NVLink & NVSwitch: Fastest HPC Data Center Platform |NVLink & NVSwitch: Fastest HPC Data Center Platform |NVLink & NVSwitch: Fastest HPC Data Center Platform | NVIDIA
NVLink 和 NVSwitch:卓越的 HPC 数据中心平台 |NVLink 和 NVSwitch:卓越的 HPC 数据中心平台 |NVLink 和 NVSwitch:卓越的 HPC 数据中心平台 | NVIDIA
推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://hqyman.cn/post/9152.html 非本站原创文章欢迎转载,原创文章需保留本站地址!

 微信支付宝扫一扫,打赏作者吧~
微信支付宝扫一扫,打赏作者吧~休息一下~~