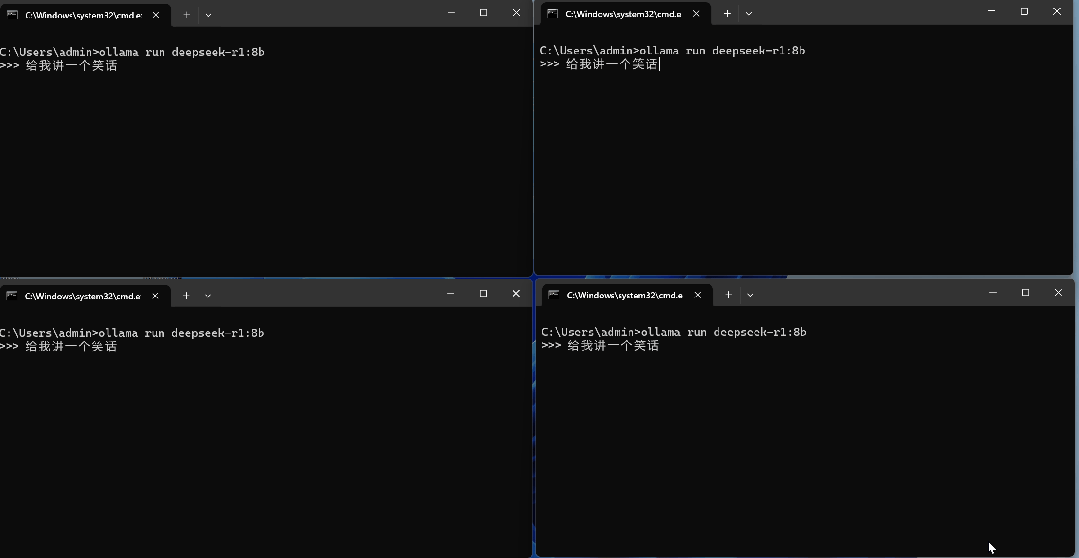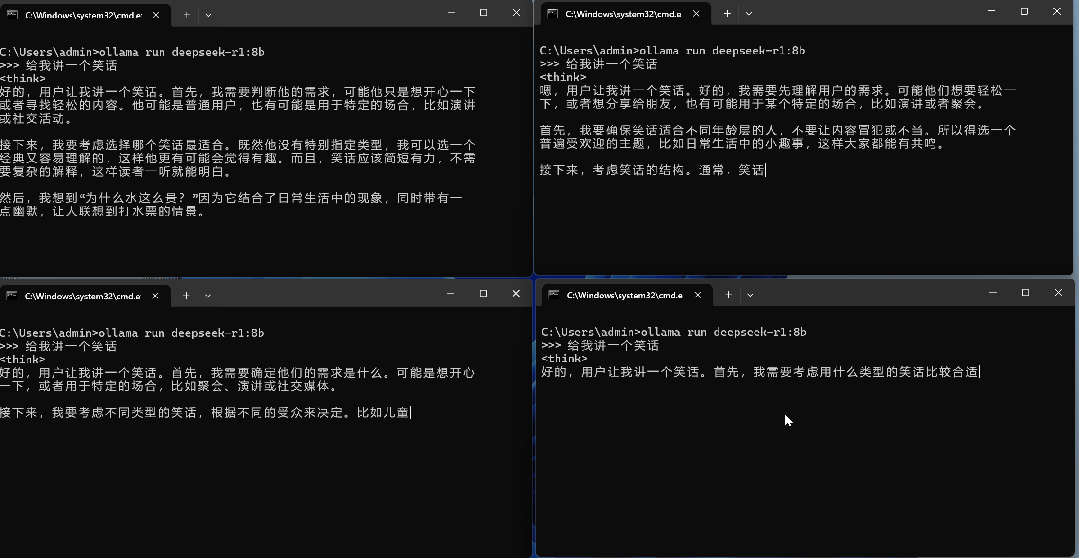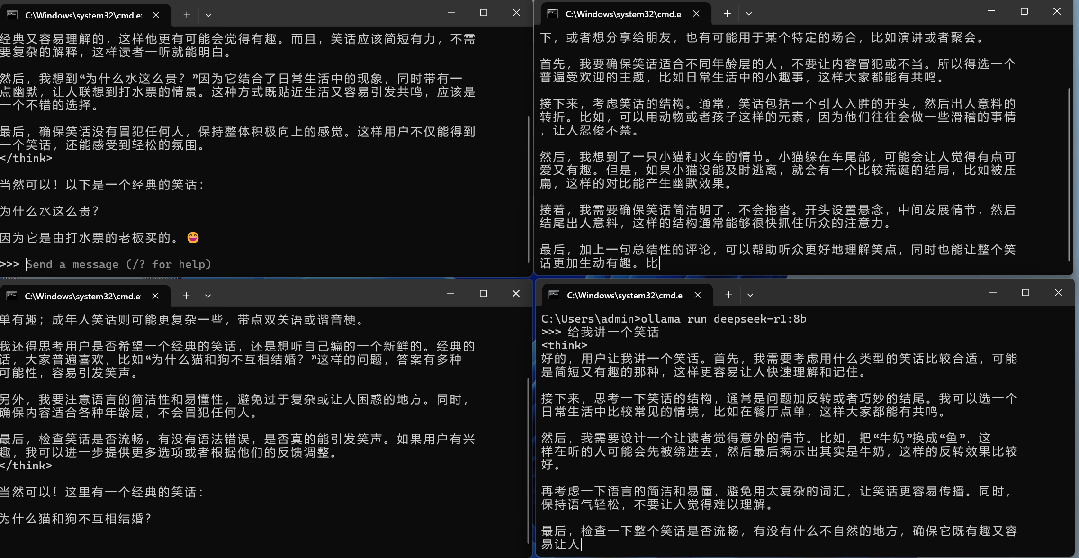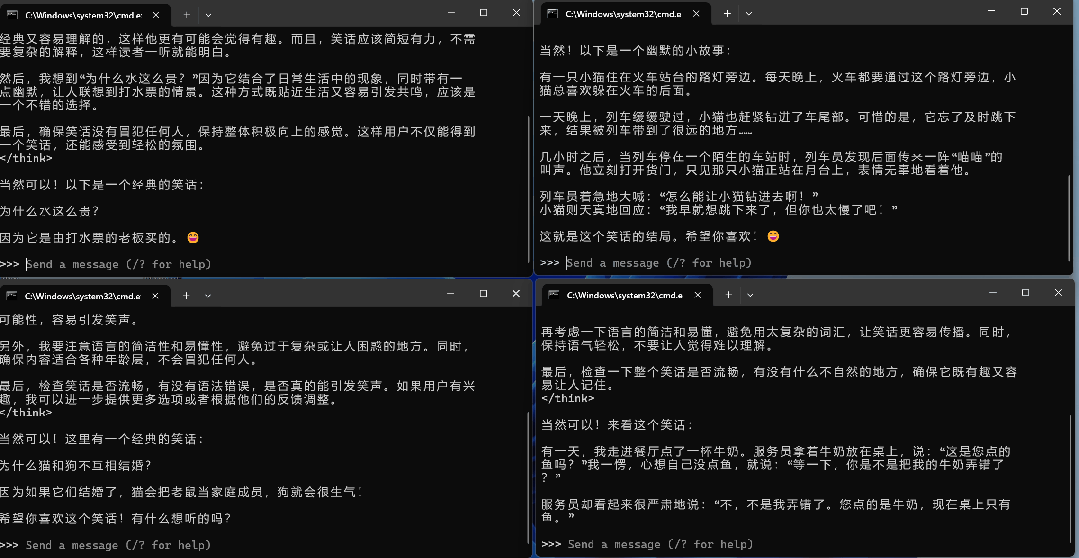
我们打开4个窗口,然后分别让DeepSeek “给我讲一个笑话” ,看下不同窗口的答题顺序。通过答题顺序可以看到,在不进行参数设置时,模型是一个一个执行。这样就说明,默认参数下,Ollama并不支持高并发,它会逐个回复我们的请求。OLLAMA_MAX_LOADED_MODELS:每个模型将同时处理的最大并行请求数,也就是能同时响应几个LLM。至于应用场景的话,就是我们可以同时在聊天页面调用两个LLM同时聊天,看看不同的LLM会有怎样不同的响应。当然,这样设置后,不同的用户也可以在同一时间请求不同的模型。OLLAMA_NUM_PARALLEL:每个模型将同时处理的最大并行请求数,也就是能同时回复多少个LLM。这个参数对于高并发非常重要,如果你部署好了Ollama,假如有10个人同时请求了你的LLM,如果一个一个回答,每个模型回复10秒钟,那轮到第10个人将会在1分多种后,对于第10个人来说是不可接受的。我们将以上两个参数添加到电脑的环境变量内,均设置为4。OLLAMA_MAX_LOADED_MODELS 4OLLAMA_NUM_PARALLEL 4
设置好后,确认环境变量并重启Ollama,我们来看一下效果。可以看到,在设置并发数为4之后,模型就能同时响应4个用户的请求。一般来说,对于中小型的部署,可以采用Ollam当作底座,只需要部署多个服务器,通过反向代理与负载均衡即可实现。如果要面对更多的并发请求,不建议使用Ollama当作底座,应采用VLLM进行部署。
推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://hqyman.cn/post/9328.html 非本站原创文章欢迎转载,原创文章需保留本站地址!
打赏

微信支付宝扫一扫,打赏作者吧~
休息一下~~


 HQY 一个和谐有爱的空间
HQY 一个和谐有爱的空间