
Deepseek来了一波疯狂炸场,把全世界的目光都吸引了过来,这波泼天的流量也是没谁了。
年后没多久,因为一些特定的原因,官网的Deepseek基本都变成了这个状态
手上刚好有几张算力还算可以的显卡
经过一系列折腾终于完成了完整版Deepseek-r1 671B满血版生产级的部署,本来就来详细讲一下。
本人水平有限,部署过程中对各种设备、模型、网络等内容的理解有限,还望各位高手指正
一、准备工作
1.1 模型文件
生产级满血版的Deepseek-r1,我们应该直奔他的原版仓库
1. huggingface的Deepseek-r1仓库地址:https://huggingface.co/deepseek-ai/DeepSeek-R1
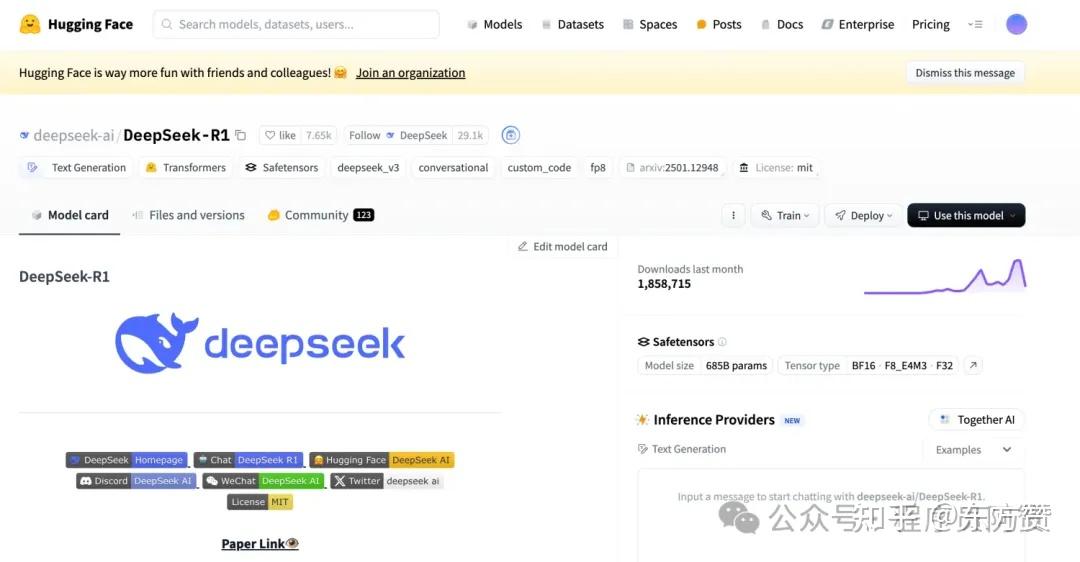
2. 魔塔社区(modelscope)的Deepseek-r1仓库地址:https://modelscope.cn/models/deepseek-ai/DeepSeek-R1

因为网络的问题,我们可以通过魔塔社区去下载可能会比较快,毕竟这个模型还是很大的。
这里可能需要澄清一下,网络上各种文章说Deepseek-r1的文件大小有600G、700G还有1T以上可能都不是非常准确。
实际在linux下载后的完整版是642G

还需要注意的是,可能大家看到的更多的是ollama官网的671b写的是404G,如下图
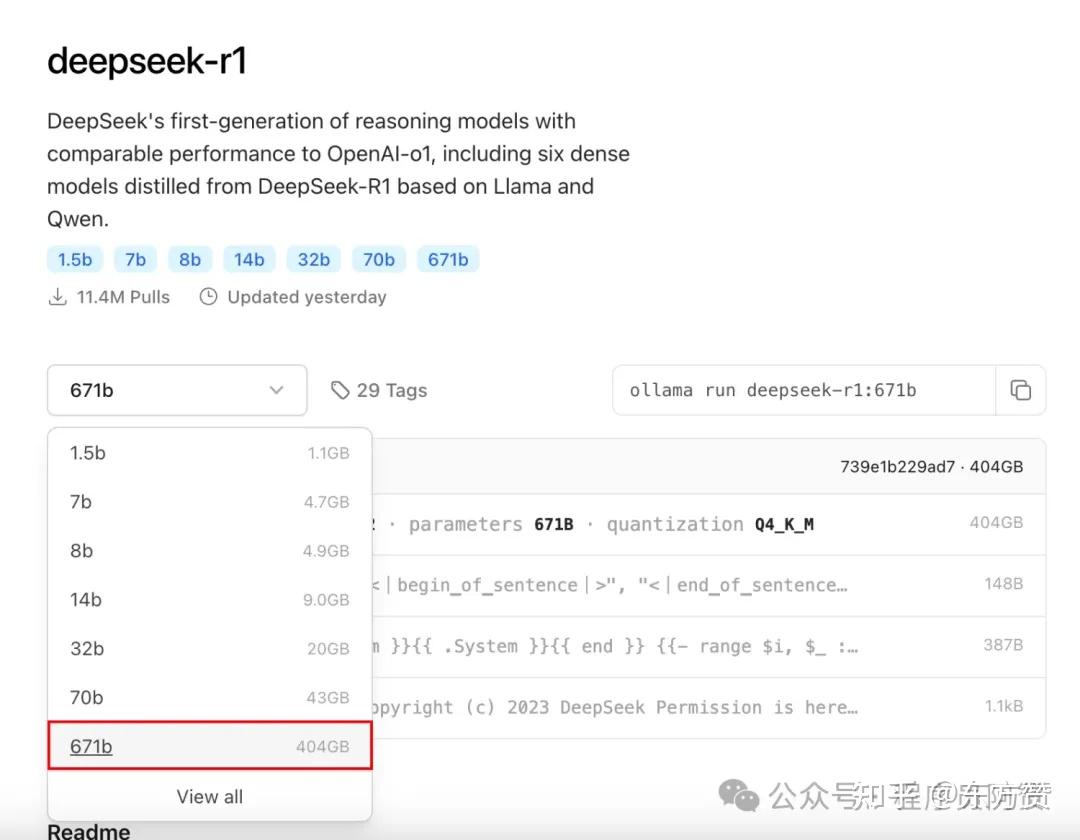
这个并非不准确,而是ollama提供的是一个4bit的量化版本,并非真正的满血非量化版本。
1.2 服务器/显卡
在这里我们准备2台8 * NVIDIA H100 80GB HBM3的服务器,并且显卡之间用Nvlink进行连接。
当然如果有H200可能效果会更好,但是毕竟那玩意还是太稀有了。
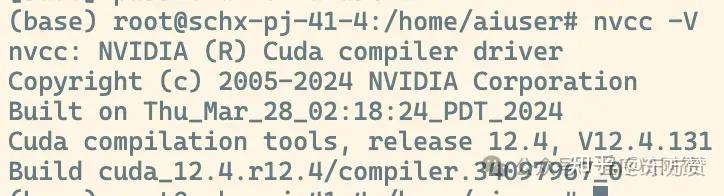
按照英伟达官网安装好显卡驱动、cuda、以及nvidia-fabricmanager,这里列出我使用的版本。
显卡驱动版本:550.54.15

cuda版本:release 12.4, V12.4.131
nvidia-fabricmanager:550_550.54.15

这里值得注意的是,上述三个软件版本一定要相互匹配,不然是运行不起来的。
1.3 推理引擎
模型、硬件都准备好了,接下来就是软件了。
在这里我选择了vllm作为推理引擎,地址:https://github.com/vllm-project/vllm

它与ollama类似,但是具有更高性能的特点,社区也比较活跃,有关他的详细介绍也可以看看其他的文章。
为了简化部署和统一环境,我们只需要下载vLLM的docker镜像即可。
在两台服务器上分别执行命令docker pull vllm/vllm-openai:v0.7.3
如果网络不太好,在阿里云上也有相应的镜像docker pull registry.cn-hangzhou.aliyuncs.com/dongfangzan/vllm-openai:v0.7.3
到此我们所有的准备工作就都做完了,接下来就可以进入部署阶段了。
请忽略图中的v0.7.1,我后来重新推了个新的,用上面的0.7.3可以的

二、开始部署
根据vllm的部署文档https://docs.vllm.ai/en/latest/serving/distributed_serving.html,我们首先要找到一个脚本用来做分布式推理。
脚本地址:
https://github.com/vllm-project/vllm/blob/main/examples/online_serving/run_cluster.sh
然后在两个不同的节点上分别执行命令
# 节点1
bash run_cluster.sh \
vllm/vllm-openai \
ip_of_head_node \
--head \
/path/to/the/huggingface/home/in/this/node \
-e VLLM_HOST_IP=ip_of_this_node
# 节点2
bash run_cluster.sh \
vllm/vllm-openai \
ip_of_head_node \
--worker \
/path/to/the/huggingface/home/in/this/node \
-e VLLM_HOST_IP=ip_of_this_node
两个节点均完成启动之后,找到其中一个节点,使用docker exec -it node bash进入容器,这时候就可以执行vllm的启动命令了。
vllm serve /root/.cache/huggingface/hub/deepseek-ai/DeepSeek-R1 \
--served-model-name deepseek-r1 \
--enable-prefix-caching \
--max-model-len 32768 \
--gpu-memory-utilization 0.95 \
--tensor-parallel-size 8 \
--pipeline-parallel-size 2 \
--enable-chunked-prefill \
--max-num-batched-tokens 32768 \
--trust-remote-code \
--port 8000
如果顺利的话,在漫长的等待之后,就可以看到模型所有的safetensors被一个一个的加载起来。
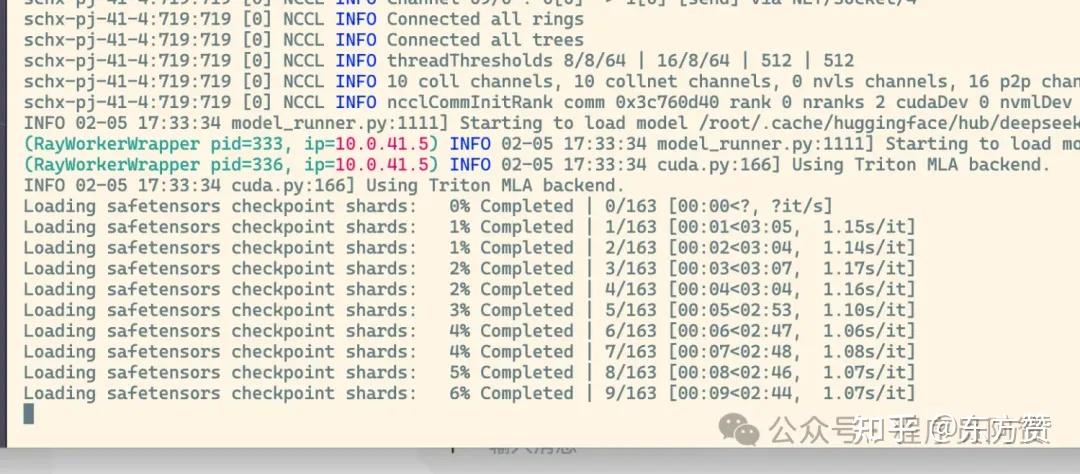
这时我们再去找一个Chatbox、Open WebUI等图形化工具进行一些简单的配置,就可以对话了。
2.1 但是
但是总会有但是,部署的过程肯定不会那么顺利,尤其是在多机多卡的推理场景上。
用上述脚本只能勉强把模型跑起来,跑起来之后,跟官网上那种流畅的速度比起来简直是千差万别,基本上就是一个字一个字在蹦非常的慢。
我们在后台看到token的生成速度,好一点的时候可能有20+tokens/s,稍微问多一点的时候可能会掉到只有不到1tokens/s,非常的惨。

到了这里可能会怀疑为什么这么多H100还是会这么慢?
因为实际上这里的瓶颈已经不在于显卡的算力,即使不是16张H100而是16张4090的话,算力也不是阻碍。
搞过多机多卡训练的大佬可能就会知道,在这种场景下**网络带宽**才是真正限制推理速度的最大阻碍。
2.2 超高性能网络-Infiniband
InfiniBand (以下简称IB网络)是一种专为高性能计算(HPC)和超大规模数据中心设计的网络技术,以亚微秒级超低延迟和超高带宽为核心优势。
这里的带宽,不是指家里的千兆网或者机房中的万兆网(10G/s)就那么简单,而是有接近400G/s的超高速显卡互联网络。

在保证系统上安装且启用了IB网卡的情况下,我们用命令ibdev2netdev -v可以看到IB网口的状态。
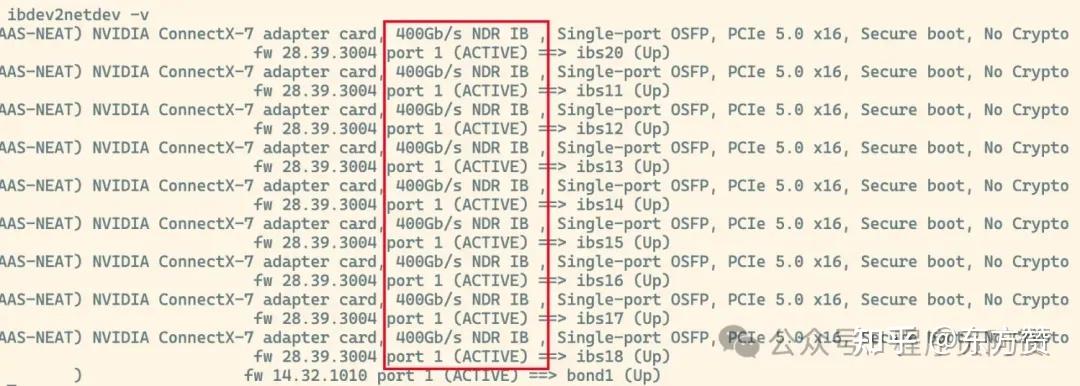
当确认了IB网络是通畅的时候,我们需要对上述的启动脚本进行修改,在两个节点上分别执行以下命令
# 节点1
bash run_cluster.sh \
vllm/vllm-openai \
ip_of_head_node \
--head \
/path/to/the/huggingface/home/in/this/node \
-e VLLM_HOST_IP=ip_of_this_node
--privileged -e NCCL_IB_HCA=mlx5 \
-e NCCL_P2P_LEVEL=NVL \
-e NCCL_IB_GID_INDEX=3 \
-e NCCL_IB_DISABLE=0 \
-e NCCL_DEBUG=INFO \
-e NCCL_SOCKET_IFNAME=ibs1 \
-e NCCL_NET_GDR_LEVEL=2
# 节点2
bash run_cluster.sh \
vllm/vllm-openai \
ip_of_head_node \
--worker \
/path/to/the/huggingface/home/in/this/node \
-e VLLM_HOST_IP=ip_of_this_node \
--privileged -e NCCL_IB_HCA=mlx5 \
-e NCCL_P2P_LEVEL=NVL \
-e NCCL_IB_GID_INDEX=3 \
-e NCCL_IB_DISABLE=0 \
-e NCCL_DEBUG=INFO \
-e NCCL_SOCKET_IFNAME=ibs1 \
-e NCCL_NET_GDR_LEVEL=2
新增的环境变量配置,主要用于启用IB网络通信,而非使用以太网进行通信,详细的每一个参数的具体含义,可以在英伟达NCCL的官方网站上找到说明。
在完成配置之后,重新启动vllm,就可以看到效果了。
三、下一步
部署到这里,我们就得到了一个跟官网不卡的时候速度类似的满血版Deepseek-r1,希望这个文档对你有所帮助。
下一步,我会对已经完成部署的模型进行压测,来探索系统的性能极限在哪里,以及如何在生产环境中何如进行进一步的性能优化,期待你的关注。
附录
一些折腾过程中遇到的问题
RuntimeError; Nccl error; unhandled svstem error (run with NCCL DEBUG INE for deta
这个报错大概率是nccl配置有问题,单机多卡场景下,请按照如下思路排查
1. 请检查pytorch版本与nccl版本是否匹配?
2. nvidia-fabricmanager是否开启?
systemctl status nvidia-fabricmanager3. fabricmanager的版本与显卡驱动版本是否匹配?
4. 执行vllm的测试脚本,https://docs.vllm.ai/en/latest/getting_started/troubleshooting.html#incorrect-hardware-driver,以确定问题出现在哪里
设置了IB网络,输出还是很慢
在启动脚本前加入NCCL_DEBUG=INFO,并检查是否有如下日志,最关键的就是[send] via NET/IB/0/GDRDMA,这段日志表示网络通信是通过BI网络且开启了RDMA
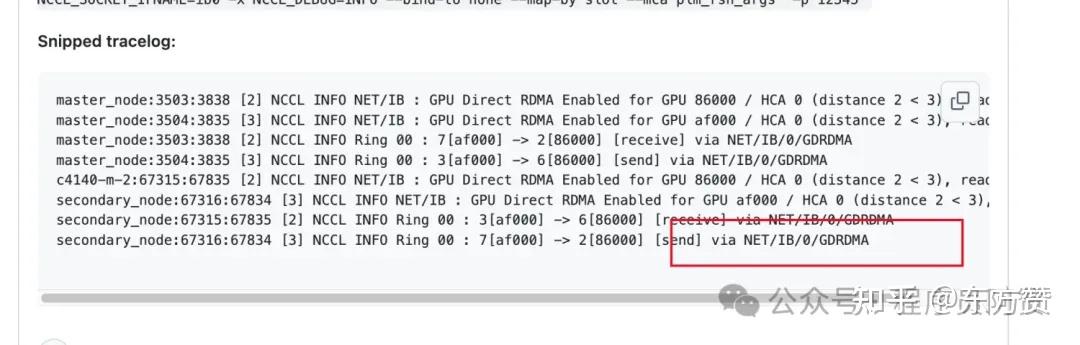
NCCL中的RDMA(远程直接内存访问)通过绕过操作系统内核实现GPU内存直接跨节点通信,减少数据传输延迟和CPU开销;
该技术利用网卡的零拷贝能力加速多机多卡间的集体操作(如AllReduce),显著提升分布式训练的通信效率。
如果你找到的日志是[send] via NET/SOCKET,则表示网络通信是通过以太网传输的,那么这时字符输出很慢是正常的。
如果你找到的日志是[send] via NET/IB/0,则表示网络通信是通过IB网络的,但是没有开启GDRDMA技术,则会有大致5%的性能损耗(网传,未实测)。
排查思路如下:
检查IB网络是否开启,并正确配置。
在github上找一个代码仓库https://github.com/NVIDIA/nccl-tests,根据文档进行nccl的测试,逐一排查问题。
对
NCCL_IB_DISABLE、NCCL_IB_HCA等环境变量的配置进行修改并调试,NCCL的官方网站https://docs.nvidia.com/deeplearning/nccl/archives/nccl_2215/user-guide/docs/env.html,会有给你很大的帮助。对于你找到的日志是[send] via NET/IB/0,无法正确开启RDMA的场景,请关注https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/troubleshooting.html#gpu-to-gpu-communication,并确认自己的系统中是否正确开启了nvidia-peermem,因为默认它是不开启的,会导致RDMA无法使用。

推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://hqyman.cn/post/9415.html 非本站原创文章欢迎转载,原创文章需保留本站地址!

 微信支付宝扫一扫,打赏作者吧~
微信支付宝扫一扫,打赏作者吧~休息一下~~