
大模型如何部署?
硬件选型
AI 领域常用 GPU
| 显卡 | 性能 | 应用场景 | 价格 |
|---|---|---|---|
| T4 | 适中 | AI 推理, 轻量级训练, 图形渲染 | 7999(14G) |
| 4090 | 非常高 | 通用计算, 图形渲染, 高端游戏, 4K/8K 视频编辑 | 14599(24G) |
| A10 | 适中 | 图形渲染, 轻量级计算 | 18999(24G) |
| A6000 | 适中 | 图形渲染, 轻量级计算 | 32999(48G) |
| V100 | 高 | 深度学习训练/推理, 高性能计算 | 42999(32G) |
| A100 | 高 | 深度学习训练/推理, 高性能计算 | 69999(40G) |
| A800 | 中等 | 深度学习推理, 高性能计算, 大数据分析 | 110000 |
| H100 | 高 | 深度学习训练/推理, 高性能计算, 大数据分析 | 242000 |
选型
参考:https://gpus.llm-utils.org/cloud-gpu-guide/
| 用例 | 显卡要求 | 推荐显卡 |
|---|---|---|
| Running Falcon-40B | 运行 Falcon-40B 所需的显卡应该有 85GB 到 100GB 或更多的显存 | See Falcon-40B table |
| Running MPT-30B | 当运行 MPT-30B 时,显卡应该具有 80GB 的显存 | See MPT-30B table |
| Training LLaMA (65B) | 对于训练 LLaMA (65B),使用 8000 台 Nvidia A100 显卡。 | Very large H100 cluster |
| Training Falcon (40B) | 训练 Falcon (40B) 需要 384 台具有 40GB 显存的 A100 显卡。 | Large H100 cluster |
| Fine tuning an LLM (large scale) | 大规模微调 LLM 需要 64 台 40GB 显存的 A100 显卡 | H100 cluster |
| Fine tuning an LLM (small scale) | 小规模微调 LLM 则需要 4 台 80GB 显存的 A100 显卡。 | Multi-H100 instance |
云服务厂商
提供推理服务,首选云服务。
国内主流
国外主流
Vultr:https://www.vultr.com
TPU 是 Google 专门用于加速机器学习的硬件。它特别适合大规模深度学习任务,通过高效的架构在性能和能源消耗上表现出色。
算力平台
主要用于学习和训练,不适合提供服务。
Colab:谷歌出品,升级服务仅需 9 美金。https://colab.google.com
Kaggle:免费,每周 30 小时 T4,P100 可用。https://www.kaggle.com
AutoDL:价格亲民,支持 Jupyter Notebook 及 ssh,国内首选。https://www.autodl.com
部署
vLLM
vLLM (https://github.com/vllm-project/vllm) 是一个快速且易于使用的库,用于进行大型语言模型(LLM)的推理和服务,适合独立部署。
无缝支持多个 Hugging Face 模型 (https://docs.vllm.ai/en/latest/models/supported_models.html)
兼容 OpenAI API
部署示例(通义千问-7B)
下载
git lfs install
git clone https://huggingface.co/Qwen/Qwen-7B-Chat设置 conda 环境
conda create -n myenv python=3.9 -y
conda activate myenv安装 vllm
pip install vllm运行
python -m vllm.entrypoints.openai.api_server --model /root/autodl-tmp/Qwen-7B-Chat --trust-remote-code --port 6006测试
curl https://u202774-a5d2-aaa1d45d.westb.seetacloud.com:8443/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/root/autodl-tmp/Qwen-7B-Chat",
"prompt": "讲个笑话",
"max_tokens": 100,
"temperature": 0.7
}'PAI
阿里云的 PAI (https://www.aliyun.com/product/bigdata/learn),提供了一键部署、自动扩缩容和基础的运维能力。
开源 Chat UI 框架
ChatGPTNextWeb/ChatGPT-Next-Web" class=" external" target="_blank" rel="nofollow noreferrer" data-za-detail-view-id="1043">https://github.com/ChatGPTNextWeb/ChatGPT-Next-Web
内容安全
敏感词过滤
定期更新敏感词汇和短语库,应对文化变迁和当前事件。
使用第三方服务或自建工具进行实时输入过滤和提示。推荐使用:
针对关键词的敏感词过滤效果并不好,因为敏感词的变种太多,无法完全覆盖。
使用 OpenAI 的 moderation
接口文档:https://platform.openai.com/docs/guides/moderation/overview
使用方式非常简单,把用户输入的文本赋值于 input 参数的值既可,但要注意对中文不是太友好。
备案
对于 B2B 业务,不需要备案。
但在 B2C 领域,一切要视具体情况而定。
如果我们自主训练大型模型,这是必要的。
但如果是基于第三方模型提供的服务,建议选择那些已获得备案并且具有较大影响力的模型。
如果你使用了文心一言的模型,可以向他们的客服要相关算法备案号。

2024年4月18日,meta开源了Llama 3大模型,虽然只有8B和70B两个版本,但Llama 3表现出来的强大能力还是让AI大模型界为之震撼了一番,本人亲测Llama3-70B版本的推理能力十分接近于OpenAI的GPT-4,何况还有一个400B的超大模型还在路上,据说再过几个月能发布。
Github上人气巨火的本地大模型部署和运行工具项目Ollama也在第一时间宣布了对Llama3的支持:

近期除了学习Rust,还有就在研究如何将LLM应用于产品中。以前走微调的路径行不通,最近的RAG(Retrieval-Augmented Generation)和Agent路径则让我看到一丝曙光。不过实施这两个路径的前提是一个强大的LLM,而开源的meta Llama系列LLM则是不二之选。
在这篇文章中,我就先来体验一下如何基于Ollama安装和运行Meta Llama3-8B大模型,并通过兼容Ollama API的OpenWebUI建立对大模型的Web图形化访问方式。
1. 安装Ollama
Ollama是一个由Go实现的、可以在本地丝滑地安装和运行各种开源大模型的工具,支持目前国内外很多主流的开源大模型,比如Llama、Mistral、Gemma、DBRX、Qwen、phi、vicuna、yi、falcon等。其支持的全量模型列表可以在Ollama library查看。
Ollama的安装采用了“curl | sh”,我们可以一键将其下载并安装到本地:
$curl -fsSL https://ollama.com/install.sh | sh
>>> Downloading ollama...
######################################################################## 100.0%
>>> Installing ollama to /usr/local/bin...
>>> Creating ollama user...
>>> Adding ollama user to video group...
>>> Adding current user to ollama group...
>>> Creating ollama systemd service...
>>> Enabling and starting ollama service...
Created symlink from /etc/systemd/system/default.target.wants/ollama.service to /etc/systemd/system/ollama.service.
>>> The Ollama API is now available at 127.0.0.1:11434.
>>> Install complete. Run "ollama" from the command line.
WARNING: No NVIDIA/AMD GPU detected. Ollama will run in CPU-only mode.我们看到Ollama下载后启动了一个ollama systemd service,这个服务就是Ollama的核心API服务,它常驻内存。通过systemctl可以确认一下该服务的运行状态:
$systemctl status ollama
● ollama.service - Ollama Service
Loaded: loaded (/etc/systemd/system/ollama.service; enabled; vendor preset: disabled)
Active: active (running) since 一 2024-04-22 17:51:18 CST; 11h ago
Main PID: 9576 (ollama)
Tasks: 22
Memory: 463.5M
CGroup: /system.slice/ollama.service
└─9576 /usr/local/bin/ollama serve另外我对Ollama的systemd unit文件做了一些改动,我修改了一下Environment的值,增加了”OLLAMA_HOST=0.0.0.0″,这样便于后续在容器中运行的OpenWebUI可以访问到Ollama API服务:
# cat /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=/root/.cargo/bin:/usr/local/cmake/bin:/usr/local/bin:.:/root/.bin/go1.21.4/bin:/root/go/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin" "OLLAMA_HOST=0.0.0.0"
[Install]
WantedBy=default.target修改后执行下面命令使之生效:
$systemctl daemon-reload
$systemctl restart ollama2. 下载和运行大模型
Ollama支持一键下载和运行模型。我手里有一个16/32G的云虚机,但没有GPU,因此这里我使用的是Llama3-8B指令微调后的用于chat/diaglogue的模型,我们只需要通过下面命令便可以快速下载并运行该模型(4bit量化的):
$ollama run llama3
pulling manifest
pulling 00e1317cbf74... 0% ▕ ▏ 0 B/4.7 GB
pulling 00e1317cbf74... 7% ▕█ ▏ 331 MB/4.7 GB 34 MB/s 2m3s^C
pulling manifest
pulling manifest
pulling manifest
pulling manifest
pulling 00e1317cbf74... 61% ▕█████████ ▏ 2.8 GB/4.7 GB 21 MB/s 1m23s^C
... ...下载和执行成功后,该命令行便会等待你的问题输入,我们随便输入一个关于Go的问题,下面是输出结果:
$ollama run llama3
>>> could you tell me something about golang language?
Go!
Here are some interesting facts and features about the Go programming language:
**What is Go?**
Go, also known as Golang, is a statically typed, compiled, and designed to be concurrent and garbage-collected language. It
was developed by Google in 2009.
**Key Features:**
1. **Concurrency**: Go has built-in concurrency support through goroutines (lightweight threads) and channels (communication
mechanisms). This makes it easy to write concurrent programs.
2. **Garbage Collection**: Go has a automatic garbage collector, which frees developers from worrying about memory
management.
3. **Static Typing**: Go is statically typed, meaning that the type system checks the types of variables at compile time,
preventing type-related errors at runtime.
4. **Simple Syntax**: Go's syntax is designed to be simple and easy to read. It has a minimalistic approach to programming
language design.
... ...推理速度大约在5~6个token吧,尚可接受,但这个过程是相当耗CPU:
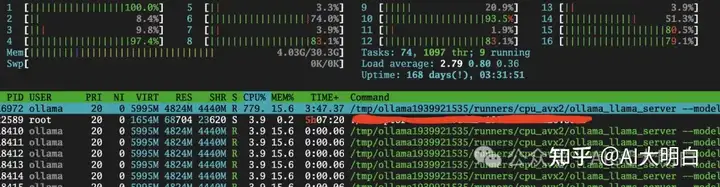
除了通过命令行方式与Ollama API服务交互之外,我们还可以用Ollama的restful API:
$curl http://localhost:11434/api/generate -d '{
> "model": "llama3",
> "prompt":"Why is the sky blue?"
> }'
{"model":"llama3","created_at":"2024-04-22T07:02:36.394785618Z","response":"The","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:36.564938841Z","response":" color","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:36.745215652Z","response":" of","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:36.926111842Z","response":" the","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:37.107460031Z","response":" sky","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:37.287201658Z","response":" can","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:37.468517901Z","response":" vary","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:37.649011829Z","response":" depending","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:37.789353456Z","response":" on","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:37.969236546Z","response":" the","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:38.15172159Z","response":" time","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:38.333323271Z","response":" of","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:38.514564929Z","response":" day","done":false}
{"model":"llama3","created_at":"2024-04-22T07:02:38.693824676Z","response":",","done":false}
... ...不过我日常使用大模型最为广泛的方式还是通过Web UI进行交互。目前有很多支持Ollama API的Web & Desktop项目,这里我们选取Open WebUI,它的前身就是Ollama WebUI。
3. 安装和使用Open WebUI与大模型交互
最快体验Open WebUI的方式当然是使用容器安装,不过官方镜像站点http://ghcr.io/open-webui/open-webui:main下载太慢,我找了一个位于Docker Hub上的个人mirror镜像,下面是在本地安装Open WebUI的命令:
$docker run -d -p 13000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data -e OLLAMA_BASE_URL=http://host.docker.internal:11434 --name open-webui --restart always dyrnq/open-webui:main容器启动后,我们在host上访问13000端口即可打开Open WebUI页面:
首个注册的用户,将会被Open WebUI认为是admin用户!注册登录后,我们就可以进入首页:
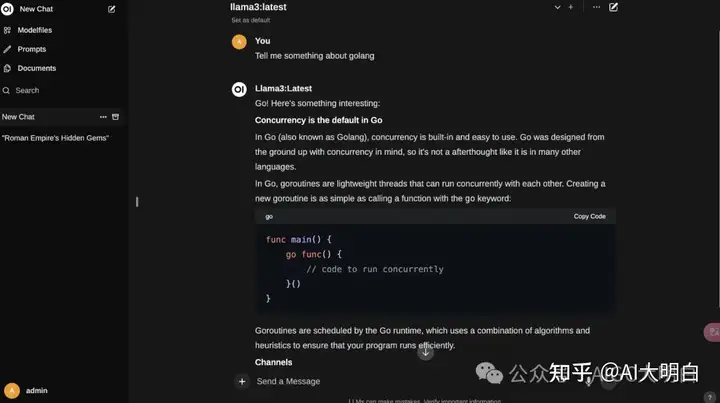
选择model后,我们便可以输入问题,并与Ollama部署的Llama3模型对话了:
注:如果Open WebUI运行不正常,可以通过查看openwebui的容器日志来辅助诊断问题。
Open WebUI的功能还有很多,大家可以自行慢慢挖掘:)。
4. 小结
在本文中,我介绍了Meta开源的Llama 3大模型以及Ollama和OpenWebUI的使用。Llama 3是一个强大的AI大模型,实测接近于OpenAI的GPT-4,并且还有一个更强大的400B模型即将发布。Ollama是一个用于本地部署和运行大模型的工具,支持多个国内外开源模型,包括Llama在内。我详细介绍了如何安装和运行Ollama,并使用Ollama下载和运行Llama3-8B模型。展示了通过命令行和REST API与Ollama进行交互,以及模型的推理速度和CPU消耗。此外,我还提到了OpenWebUI,一种兼容Ollama API的Web图形化访问方式。通过Ollama和OpenWebUI,大家可以方便地在CPU上使用Meta Llama3-8B大模型进行推理任务,并获得满意的结果。
作者:绝密伏击
链接:https://www.zhihu.com/question/583350294/answer/3333377160
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
随着大模型的快速发展,目前出现了各种各样的大模型,如OpenAI的GPT模型、Meta的Llama模型、百度的文心一言模型、科大讯飞的讯飞星火模型、百川的Baichuan-13B,阿里的Qwen-14B和Qwen-72B、清华的GLM。本文将介绍如何部署大模型,包括环境安装和模型加载,并分享一些低成本的部署技巧,让读者可以在个人电脑上运行大模型。本文的重点是如何通过有监督微调,构建自己的大模型,让大模型能够适应您的使用场景,发挥最大的价值。 一、选择基座模型在大模型应用中,选择一款合适的基座模型非常关键,它要求既能达到优秀的效果,又能降低部署的成本。这样就可以方便地在私有数据上进行微调,并且实现低成本的部署。根据开源评测平台OpenCompass的数据,目前综合能力最好的10个开源基座模型如表1-1所示。从表中可以看出,排名第一的是清华大学于2023年10月发布的60亿参数的大模型ChatGLM3-6B。它在前10名中参数量最少,但是效果最佳,是选择基座模型的最佳候选。表1-1 开源大模型(基座)评测排名(数据来源自OpenCompass)模型发布时间所属机构参数量综合得分ChatGLM3-6B2023/10/27清华大学6B65.3Qwen-14B2023/9/25阿里巴巴14B62.4XunYuan-70B2023/9/22度小满70B60.0InternLM-20B2023/9/20商汤科技20B59.3LLaMA-2-70B2023/7/19Meta70B57.4TigerBot-70B-Base-V12023/9/6虎博科技70B55.7Qwen-7B2023/9/25阿里巴巴7B55.2LLaMA-65B2023/2/24Meta65B51.9Mistral-7B-v0.12023/9/27Mistral AI7B51.2TigerBot-13B-Base-V12023/8/8虎博科技13B50.31.1 环境安装ChatGLM3是由智谱AI和清华大学KEG实验室联合发布的新一代对话预训练模型,其中ChatGLM3-6B是开源的对话模型,具有以下特性。更强大的基础模型:ChatGLM3-6B基于ChatGLM3-6B-Base进行微调,后者使用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在不同角度的数据集上测评显示,ChatGLM3-6B-Base在10B以下的基础模型中表现最优。更完整的功能支持:ChatGLM3-6B采用了全新设计的 提示(Prompt) 格式,除了支持多轮对话外,还支持工具调用、代码执行等复杂场景。更全面的开源序列:除了对话模型ChatGLM3-6B外,还开源了基础模型ChatGLM3-6B-Base、长文本对话模型ChatGLM3-6B-32K。为了使用ChatGLM3-6B作为基座模型,首先需要安装环境,可以从gitHub上克隆代码仓库,然后使用pip安装依赖。git clone https://github.com/THUDM/ChatGLM3
cd ChatGLM3
pip install -r requirements.txt其中transformers库版本推荐为4.30.2,torch推荐使用2.0及以上的版本,以获得最佳的推理性能。1.2 模型加载要想加载 ChatGLM3-6B 模型,有多种方式可以选择,例如代码调用、网页版、命令行、工具调用等。下面先来看看如何通过代码调用的方式加载模型。代码调用可以使用下面的方式生成对话,只需调用ChatGLM3-6B模型即可,无须手动下载模型实现和参数,transformers会自动完成这些工作。from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True)
model = AutoModel.from_pretrained(
"THUDM/chatglm3-6b", trust_remote_code=True, device='cuda')
model = model.eval()
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
你好 !我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。
response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
print(response)
晚上睡不着可能会让你感到焦虑或不舒服,但以下是一些可以帮助你入睡的方法:
1. 制定规律的睡眠时间表:保持规律的睡眠时间表可以帮助你建立健康的睡眠习惯,使你更容易入睡。尽量在每天的相同时间上床,并在同一时间起床。
2. 创造一个舒适的睡眠环境:确保睡眠环境舒适,安静,黑暗且温度适宜。可以使用舒适的床上用品,并保持房间通风。
3. 放松身心:在睡前做些放松的活动,例如泡个热水澡,听些轻柔的音乐,阅读一些有趣的书籍等,有助于缓解紧张和焦虑,使你更容易入睡。
4. 避免饮用含有咖啡因的饮料:咖啡因是一种刺激性物质,会影响你的睡眠质量。尽量避免在睡前饮用含有咖啡因的饮料,例如咖啡,茶和可乐。
5. 避免在床上做与睡眠无关的事情:在床上做些与睡眠无关的事情,例如看电影,玩游戏或工作等,可能会干扰你的睡眠。
6. 尝试呼吸技巧:深呼吸是一种放松技巧,可以帮助你缓解紧张和焦虑,使你更容易入睡。试着慢慢吸气,保持几秒钟,然后缓慢呼气。
如果这些方法无法帮助你入睡,你可以考虑咨询医生或睡眠专家,寻求进一步的建议完整的模型实现在Hugging Face Hub。如果你的网络环境较差,下载模型参数可能会花费较长时间甚至失败。此时可以先将模型下载到本地,然后从本地加载。从 Hugging Face Hub下载模型需要先安装Git LFS。网页版示例您可以通过下面的命令,启动一个基于Gradio的网页版示例。python web_demo.py当ChatGLM3-6B模型成功启动,您就可以在网页上看到图1-1所示的界面,并开始与模型对话。<img src="https://picx.zhimg.com/50/v2-cc298c5b2b10abd6fb6a3dc0cb3f0a11_720w.jpg?source=1def8aca" data-size="normal" data-rawwidth="749" data-rawheight="648" data-original-token="v2-ae11b9334aac59b3a304a7705c941dac" class="origin_image zh-lightbox-thumb" width="749" data-original="https://picx.zhimg.com/v2-cc298c5b2b10abd6fb6a3dc0cb3f0a11_r.jpg?source=1def8aca"/>图1-1 基于Gradio启动ChatGLM3-6B除了上面的方式外,还可以通过下面的命令,启动一个基于Streamlit的网页版示例。streamlit run web_demo2.py模型启动成功后,您可以在网页上看到图1-2显示的界面。您可以在左边的区域调整模型的参数,也可以在中间的区域和ChatGLM3-6B进行自由对话。<img src="https://pic1.zhimg.com/50/v2-a4a8c0e7c08475b1ba8f271fb1acdac2_720w.jpg?source=1def8aca" data-size="normal" data-rawwidth="748" data-rawheight="325" data-original-token="v2-148d2074339358cc35c967d2f020dc58" class="origin_image zh-lightbox-thumb" width="748" data-original="https://picx.zhimg.com/v2-a4a8c0e7c08475b1ba8f271fb1acdac2_r.jpg?source=1def8aca"/>图1-2 基于Streamlit启动ChatGLM3-6B命令行示例运行下面代码,程序会在命令行中进行交互式的对话,在命令行中输入指示并回车即可生成回复,输入clear可以清空对话历史,输入stop终止程序。python cli_demo.py模型启动成功后,您可以在命令行看到如图1-3所示的界面。<img src="https://pic1.zhimg.com/50/v2-033fc31eae5788d0bc34f9fc5710e607_720w.jpg?source=1def8aca" data-size="normal" data-rawwidth="892" data-rawheight="487" data-original-token="v2-d80bef3abb433ad8627b909310aadb8d" class="origin_image zh-lightbox-thumb" width="892" data-original="https://pic1.zhimg.com/v2-033fc31eae5788d0bc34f9fc5710e607_r.jpg?source=1def8aca"/>图1-3 基于命令行启动ChatGLM3-6B二、低成本部署前面介绍了多种模型加载的方式,包括网页版和命令行版。但是这些方式都需要高性能的GPU,对于普通用户来说,不太方便。因此,下面介绍如何低成本地部署ChatGLM3-6B,让更多用户能够体验它。2.1 模型量化模型默认以FP16精度加载,需要约13GB的显存。如果您的GPU显存不足,您可以选择以量化方式加载模型,具体方法如下。model = AutoModel.from_pretrained("THUDM/chatglm3-6b",trust_remote_code=True).quantize(4)量化会降低一些模型的性能,但是测试结果表明,ChatGLM3-6B 在 4-比特量化下仍然能够生成自然流畅的对话。2.2 CPU部署您也可以在CPU上运行模型,但是推理速度会慢很多。具体方法如下(需要至少32GB 的内存)。model = AutoModel.from_pretrained("THUDM/chatglm3-6b", trust_remote_code=True).float()2.3 Mac部署如果您的Mac使用了Apple Silicon或AMD GPU,您可以使用MPS后端在GPU上运行 ChatGLM3-6B。您需要按照Apple的官方说明安装PyTorch-Nightly(请注意版本号应该是 2.x.x.dev2023xxxx,而不是 2.x.x)。目前MacOS上只支持从本地加载模型。model = AutoModel.from_pretrained("your local path", trust_remote_code=True).to('mps')加载半精度的 ChatGLM3-6B 模型需要约 13GB 的内存。如果您的机器内存较小(比如 16GB 的 MacBook Pro),在内存不足时会使用硬盘上的虚拟内存,这会导致推理速度大幅降低。2.4 多卡部署如果您有多张GPU,但是每张GPU的显存都不够加载完整的模型,您可以使用模型并行的方式,将模型分配到多张GPU上。您需要先安装accelerate: pip install accelerate。这样,您就可以在两张GPU上运行模型了。您可以根据您的需要,修改num_gpus参数来指定使用的GPU数量。默认情况下,模型会平均分配到各个GPU上,您也可以通过device_map参数来自定义分配方式。from utils import load_model_on_gpus
model = load_model_on_gpus("THUDM/chatglm3-6b", num_gpus=2)三、构建自己的大模型在了解了如何部署模型的方法后,接下来使用自己的数据,对大模型进行微调,赋予它新的能力。以广告词生成为例,下面介绍如何对大模型进行微调,让它生成更符合要求的广告词。由于ChatGLM3-6B的微调代码尚未开源,因此无法直接使用它,但是可以参考ChatGLM2-6B和ChatGLM-6B的微调代码,只需修改相应的模型路径和参数即可。 在微调之前,先来看看ChatGLM3-6B在没有微调的情况下,生成广告词的效果,如图3-1所示。从图中可以看出,生成的广告词过长,不够简洁,而且结尾都是“快来抢购这款…,让您的时尚之路更加精彩!”,格式单一,缺乏创意。为了改善这一问题,接下来选择ADGEN数据集,对模型进行微调。<img src="https://pic1.zhimg.com/50/v2-60d3c51b3dd0a03c50cf66c410d5304c_720w.jpg?source=1def8aca" data-size="normal" data-rawwidth="931" data-rawheight="644" data-original-token="v2-5bf6f447998124655df10cb09a57b7b7" class="origin_image zh-lightbox-thumb" width="931" data-original="https://pic1.zhimg.com/v2-60d3c51b3dd0a03c50cf66c410d5304c_r.jpg?source=1def8aca"/>图3-1 ChatGLM3-6B根据输入生成广告词3.1 数据准备首先下载ADGEN数据集,这是一个用于生成广告文案的数据集。它的任务是根据输入的商品信息(content)生成一段吸引人的广告词(summary)。您可以从Google Drive或者Tsinghua Cloud下载预处理好的ADGEN数据集,并将解压后的AdvertiseGen文件夹放到当前目录下。把AdvertiseGen文件夹里的数据分成训练集和验证集,分别保存为train.json和dev.json文件,数据的格式如图3-2所示。<img src="https://picx.zhimg.com/50/v2-e3603dc0dcea62d8480e94d8af8ac1cd_720w.jpg?source=1def8aca" data-size="normal" data-rawwidth="893" data-rawheight="185" data-original-token="v2-1d1c516c0e3e25ee23f61b4ad68ffe91" class="origin_image zh-lightbox-thumb" width="893" data-original="https://pica.zhimg.com/v2-e3603dc0dcea62d8480e94d8af8ac1cd_r.jpg?source=1def8aca"/>图3-2 广告词数据集数据格式例如,输入“类型#上衣版型#宽松版型#显瘦图案#线条衣样式#衬衫衣袖型#泡泡袖衣款式#抽绳”,输出为“这件衬衫的款式非常的宽松,利落的线条可以很好的隐藏身材上的小缺点,穿在身上有着很好的显瘦效果。领口装饰了一个可爱的抽绳,漂亮的绳结展现出了十足的个性,配合时尚的泡泡袖型,尽显女性甜美可爱的气息。”3.2 有监督微调如果想有监督微调ChatGLM3-6B,您需要自己写一套代码,因为它的微调代码还没有公开。不过,我们也可以借鉴ChatGLM2-6B的微调代码,它已经开源了,只需要调整一些细节就行。您可以先从网上下载ChatGLM2-6B的代码。 下载好ChatGLM2-6B的代码后,需要把有监督微调的代码文件复制到ChatGLM3-6B的文件夹里。然后,把前面准备好的数据集也复制到ChatGLM3-6B的有监督微调文件夹里。cp -r ChatGLM2-6B/ptuning ChatGLM3-6B/
cp –r AdvertiseGen ChatGLM3-6B/ptuning/要进行全参数微调,您需要先安装deepspeed,还需要安装一些有监督微调需要的包。pip install deepspeed
cd ptuning
pip install rouge_chinese nltk jieba datasets准备好微调代码的环境后,还要修改一些微调代码的参数。vim ds_train_finetune.sh
LR=1e-5
MASTER_PORT=$(shuf -n 1 -i 10000-65535)
deepspeed --num_gpus=8 --master_port $MASTER_PORT main.py \
--deepspeed deepspeed.json \
--do_train \
--preprocessing_num_workers 32 \
--train_file AdvertiseGen/train.json \
--test_file AdvertiseGen/dev.json \
--prompt_column content \
--response_column summary \
--model_name_or_path ../models/chatglm3-6b \
--output_dir output/adgen-chatglm3-6b-ft \
--overwrite_output_dir \
--max_source_length 512 \
--max_target_length 512 \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 1 \
--predict_with_generate \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate $LR \
--fp16上面代码中的参数含义在表3-1中给出,您可以根据具体的任务和硬件环境进行调整。参数参数含义num_gpus使用的GPU数量deepspeeddeepspeed的配置文件preprocessing_num_workers数据预处理的线程数量train_file训练数据文件的路径test_file测试数据文件的路径prompt_column输入列的名称response_column输出列的名称model_name_or_path模型名称或路径output_dir输出模型参数的文件路径max_source_length最大输入长度max_target_length最大输出长度per_device_train_batch_size每个设备的训练批次大小per_device_eval_batch_size每个设备的评估批次大小gradient_accumulation_steps梯度累计 步数predict_with_generate是否使用生成模式进行预测logging_steps记录日志的步数save_steps保存模型的步数learning_rate学习率fp16是否使用半精度浮点数进行训练接下来需要调整main.py文件中的num_train_epoch参数(默认为3),该参数表示训练的轮数。vim main.py
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
# datasets.utils.logging.set_verbosity(log_level)
transformers.utils.logging.set_verbosity(log_level)
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
# Log on each process the small summary:
training_args.num_train_epochs = 1
logger.info(f"Training/evaluation parameters {training_args}")目前已经完成了训练数据的准备和代码的修改,接下来运行代码来开始微调模型。bash ds_train_finetune.sh当运行代码时,会遇到一个错误,提示:ChatGLMTokenizer类没有build_prompt方法。这是因为ChatGLM3-6B的ChatGLMTokenizer类没有实现这个方法。要解决这个问题,您可以参考ChatGLM2-6B中ChatGLMTokenizer类的build_prompt方法,按照相同的逻辑编写代码。vim ../models/chatglm3-6b/tokenization_chatglm.py
# 在ChatGLMTokenizer类中实现build_prompt方法
def build_prompt(self, query, history=None):
if history is None:
history = []
prompt = ""
for i, (old_query, response) in enumerate(history):
prompt += "[Round {}]\n\n问:{}\n\n答:{}\n\n".format(
i + 1, old_query, response)
prompt += "[Round {}]\n\n问:{}\n\n答:".format(len(history) + 1, query)
return prompt在Tokenizer类中添加了build_prompt方法的代码后,程序就可以正常运行了。我们可以使用命令watch -n 1 nvidia-smi来监控GPU的使用情况。这个命令会每分钟刷新一次程序界面,显示GPU的使用率、显存的占用率和功耗等信息。图3-3展示了一个程序界面的截图。从图中可以看出,GPU使用率已经接近100%,显存占用约为57409MiB。这说明还有一些空间可以增加训练的批量大小或者输入输出的长度,以提高训练效率。<img src="https://pica.zhimg.com/50/v2-d97f2bf0b991aae8a547a7d58768dab2_720w.jpg?source=1def8aca" data-size="normal" data-rawwidth="897" data-rawheight="963" data-original-token="v2-ed12deaac3891ffddb454c85c43f826f" class="origin_image zh-lightbox-thumb" width="897" data-original="https://picx.zhimg.com/v2-d97f2bf0b991aae8a547a7d58768dab2_r.jpg?source=1def8aca"/>图3-3 微调过程中GPU使用情况模型微调完成后,./output/adgen-chatglm3-6b-ft目录下会生成相应的文件,包含了模型的参数文件和各种配置文件,具体内容如下所示。以pytorch_model开头的文件是模型的参数文件。tree ./output/adgen-chatglm3-6b-ft
├── all_results.json
├── checkpoint-1000
│ ├── config.json
│ ├── configuration_chatglm.py
│ ├── generation_config.json
│ ├── global_step1000
│ │ ├── mp_rank_00_model_states.pt
│ │ ├── zero_pp_rank_0_mp_rank_00_optim_states.pt
│ │ ├── zero_pp_rank_1_mp_rank_00_optim_states.pt
│ │ ├── zero_pp_rank_2_mp_rank_00_optim_states.pt
│ │ ├── zero_pp_rank_3_mp_rank_00_optim_states.pt
│ │ ├── zero_pp_rank_4_mp_rank_00_optim_states.pt
│ │ ├── zero_pp_rank_5_mp_rank_00_optim_states.pt
│ │ ├── zero_pp_rank_6_mp_rank_00_optim_states.pt
│ │ └── zero_pp_rank_7_mp_rank_00_optim_states.pt
│ ├── ice_text.model
│ ├── latest
│ ├── modeling_chatglm.py
│ ├── pytorch_model-00001-of-00002.bin
│ ├── pytorch_model-00002-of-00002.bin
│ ├── pytorch_model.bin.index.json
│ ├── quantization.py
│ ├── rng_state_0.pth
│ ├── rng_state_1.pth
│ ├── rng_state_2.pth
│ ├── rng_state_3.pth
│ ├── rng_state_4.pth
│ ├── rng_state_5.pth
│ ├── rng_state_6.pth
│ ├── rng_state_7.pth
│ ├── special_tokens_map.json
│ ├── tokenization_chatglm.py
│ ├── tokenizer_config.json
│ ├── trainer_state.json
│ ├── training_args.bin
│ └── zero_to_fp32.py
├── trainer_state.json
└── train_results.json训练过程中,可以观察到每次迭代的时间,例如:[4:28:37<4:40:51, 6.39s/it],表示每次迭代需要6.39秒。因此,对于12万的数据,我们可以估算出微调所需的总时间为120000/16/8*6.39/3600 ≈ 1.66小时,其中16是批量大小,8是GPU的数量。大约1.66小时后,12万的数据就可以微调完成。3.3 部署自己的大模型新模型微调好后,就可以部署起来了。使用Streamlit启动微调后的模型。启动后,您可以看看模型生成的广告词效果,如图3-4所示。可以看出,模型的回答风格比微调前更加丰富多样。<img src="https://pica.zhimg.com/50/v2-b9dcfbf98eec4da49689ddc3f91cb159_720w.jpg?source=1def8aca" data-size="normal" data-rawwidth="940" data-rawheight="555" data-original-token="v2-7fd7272d09a99e75bf1200e441aea64e" class="origin_image zh-lightbox-thumb" width="940" data-original="https://picx.zhimg.com/v2-b9dcfbf98eec4da49689ddc3f91cb159_r.jpg?source=1def8aca"/>图3-4 微调之后的模型3.4 灾难遗忘问题大模型的灾难遗忘是指在连续学习多个任务的过程中,学习新知识会导致模型忘记或破坏之前学习到的旧知识,从而使模型在旧任务上的性能急剧下降。这是一个机器学习领域的重要挑战,尤其是对于大规模语言模型和多模态大语言模型,它们需要在不同的数据集和领域上进行微调或适应。使用广告数据集ADGEN对模型进行了微调,结果发现模型不仅忘记了之前学会的正常回答,甚至还出现了输出错误的情况。这是因为广告数据集和模型原来的训练数据分布相差太大,引起了模型的“灾难遗忘”现象。图3-5展示了微调后的模型,连简单的问答都无法回答了。<img src="https://picx.zhimg.com/50/v2-27a7fe47f750e0a5b1ab90a8c8f6eef2_720w.jpg?source=1def8aca" data-size="normal" data-rawwidth="731" data-rawheight="325" data-original-token="v2-9b2b0871db60a881c1e08a0ae0779a5b" class="origin_image zh-lightbox-thumb" width="731" data-original="https://picx.zhimg.com/v2-27a7fe47f750e0a5b1ab90a8c8f6eef2_r.jpg?source=1def8aca"/>图3-5 微调之后出现了灾难遗忘现象为了缓解灾难遗忘问题,我们可以使用其他数据来增强模型的泛化能力。例如,可以使用一个包含逻辑推理和问答类的数据集,用于和广告数据集一起进行微调。比如我们构建的新数据集,它包含了一些逻辑推理和问答类的数据。您需要将这个文件转换成模型可以接受的输入格式。 新的数据集涵盖了数学应用题、选择题、填空题等多种不同类型的数据,比之前的广告数据集ADGEN更加丰富和多样。我们可以将这两个数据集合并在一起,对模型进行重新微调,以提高模型的泛化能力和稳定性。将新的数据集和广告数据集ADGEN合并后,对模型进行重新训练。训练过程中,程序会定期输出验证集的损失值,反映模型的学习效果。将这些损失值绘制成曲线图,如图3-6所示。从图中可以看出,模型的验证集损失值呈现下降的趋势。在训练了一个完整的轮次后,停止训练,保存模型。<img src="https://pica.zhimg.com/50/v2-4f19f2cd421e7964f8bd01a7dddb3ac9_720w.jpg?source=1def8aca" data-size="normal" data-rawwidth="496" data-rawheight="241" data-original-token="v2-e362fdc765e85837aefb6d13a254b5fd" class="origin_image zh-lightbox-thumb" width="496" data-original="https://pica.zhimg.com/v2-4f19f2cd421e7964f8bd01a7dddb3ac9_r.jpg?source=1def8aca"/>图3-6 训练过程中的验证集损失值使用Streamlit来启动新训练的模型。模型启动后,下面检验一下新模型是否存在灾难遗忘的问题。如图3-7所示,新模型不仅能够回答正常的问题,还能够生成新的广告词,有效地缓解了灾难遗忘的现象。<img src="https://picx.zhimg.com/50/v2-aef42117652a1f1970f238b594c732ce_720w.jpg?source=1def8aca" data-size="normal" data-rawwidth="775" data-rawheight="484" data-original-token="v2-9bb550003d8047dc42641428e545a984" class="origin_image zh-lightbox-thumb" width="775" data-original="https://picx.zhimg.com/v2-aef42117652a1f1970f238b594c732ce_r.jpg?source=1def8aca"/>图3-7 新训练的模型新模型不仅能缓解灾难遗忘问题,还能回答更多的问题。例如,对于“亚历克鲍德温的孩子比克林特伊斯特伍德多吗?”这样的问题,旧模型无法给出答案,而新模型则能轻松回答。另外,新模型在其他问题上也有更好的表现,如图3-8所示。<img src="https://picx.zhimg.com/50/v2-7245728c20313a4dc34fa087d9712b8f_720w.jpg?source=1def8aca" data-size="normal" data-rawwidth="2414" data-rawheight="2434" data-original-token="v2-016d4e15d202982a084afa8aec3ee9e3" class="origin_image zh-lightbox-thumb" width="2414" data-original="https://pic1.zhimg.com/v2-7245728c20313a4dc34fa087d9712b8f_r.jpg?source=1def8aca"/>图3-8 新旧模型对比新模型在数学推理上有显著的优势,它能够正确地列出并解决一些经典的数学问题。例如,鸡兔同笼这个问题,如图3-9所示,旧模型只能得到一个方程,而忽略了另一个方程,导致计算结果出现错误。而新模型则能够得到两个方程,并用消元法求出正确的答案。旧模型不仅在列方程时遗漏了一个条件,而且在推理过程中还存在数值计算的失误,例如,当x = 1, y = 7时,它给出的结果是x + 2y = 14,这显然是不正确的。<img src="https://pic1.zhimg.com/50/v2-dbd019a603ecb836c2693f0d49850bdf_720w.jpg?source=1def8aca" data-size="normal" data-rawwidth="955" data-rawheight="579" data-original-token="v2-53958ec9047566294f82eefbd38c4c25" class="origin_image zh-lightbox-thumb" width="955" data-original="https://picx.zhimg.com/v2-dbd019a603ecb836c2693f0d49850bdf_r.jpg?source=1def8aca"/>图3-9 旧模型回答鸡兔同笼问题如图3-10所示,新模型的回答非常准确和完整。它不但能够根据题目条件列出两个方程,还能够正确地运用消元法求解方程,并得出正确的答案。新模型在数学应用题上的优异表现,主要得益于我们使用了一个包含大量数学推理题的新数据集进行有监督的微调,这使得模型在这类任务上具有更强的泛化能力。<img src="https://pica.zhimg.com/50/v2-33cd8228ee76501dd2585b76c1335d60_720w.jpg?source=1def8aca" data-size="normal" data-rawwidth="873" data-rawheight="514" data-original-token="v2-7d8e013d1152fd98e30900b11cd2e7d7" class="origin_image zh-lightbox-thumb" width="873" data-original="https://pic1.zhimg.com/v2-33cd8228ee76501dd2585b76c1335d60_r.jpg?source=1def8aca"/>图3-10 新模型回答鸡兔同笼问题3.5 程序思维提示——解决复杂数值推理大模型虽然在语言理解和数学推理等方面有着优异的性能,但是在数值计算方面却显得力不从心。例如,当要计算123*145时,模型往往无法给出正确答案,这是因为四则运算的可能性太多,模型不可能覆盖所有的情况。同样,对于复杂方程的求解,大模型也束手无策,比如四元方程。图3-11展示了大模型在这两个问题上的错误答案。<img src="https://picx.zhimg.com/50/v2-c6a90833aaf3382a62027e7085883ee7_720w.jpg?source=1def8aca" data-size="normal" data-rawwidth="915" data-rawheight="602" data-original-token="v2-8d8ccb9aedcb9b68a5e49ade1e967565" class="origin_image zh-lightbox-thumb" width="915" data-original="https://pic1.zhimg.com/v2-c6a90833aaf3382a62027e7085883ee7_r.jpg?source=1def8aca"/>图3-11 模型无法正确处理数值计算论文Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks针对数值计算的难题,提出了一种创新的方法,即思维程序提示(Program of Thoughts Prompting, PoT)。思维程序提示的核心思想是,通过语言模型生成一个能够反映推理逻辑的程序,然后将程序中的计算部分交由外部的计算机执行,实现计算和推理的分离。思维程序提示的优势在于,它既能利用语言模型的强大能力,生成正确和完备的程序来描述复杂的推理,又能将计算交给专业的程序解释器来完成,避免了语言模型在计算上的误差。接下来参考思维程序提示的方法,来解决四则运算和解方程的问题。使用程序代码来代替数据中的四则运算部分,用python的sympy库来处理解方程的部分。我们制定了一些指令的格式,然后用GPT-4来生成符合这些格式的回答。图3-12展示了设计的几种思维程序提示指令,涵盖了纯四则运算、数学应用题中的四则运算和解方程。<img src="https://picx.zhimg.com/50/v2-f06bf7c7810bd3bd5a38cd47138bcc25_720w.jpg?source=1def8aca" data-size="normal" data-rawwidth="2841" data-rawheight="2024" data-original-token="v2-16f61a3f353de5fd62c300d676c52ca3" class="origin_image zh-lightbox-thumb" width="2841" data-original="https://pic1.zhimg.com/v2-f06bf7c7810bd3bd5a38cd47138bcc25_r.jpg?source=1def8aca"/>图3-12 构建思维程序提示根据图3-12的思维程序提示,用GPT-4(确保答案的正确性)来生成相应格式的答案。图3-13展示了新构建的语料格式,可以看出,四则运算部分的结果用中间变量代替,解方程部分用python的sympy函数直接求解。对于没有四则运算和解方程的样本,保持原来的格式不变。为了明确哪些部分需要用程序解释器执行,哪些部分不需要,用"<<“和”>>“来标记,”<<“表示程序的起始,”>>"表示程序的结束。<img src="https://pic1.zhimg.com/50/v2-e486af7500a211210918b7358a6cee5b_720w.jpg?source=1def8aca" data-size="normal" data-rawwidth="998" data-rawheight="690" data-original-token="v2-21a403b8f3c1c1297e61c54d8a406997" class="origin_image zh-lightbox-thumb" width="998" data-original="https://pic1.zhimg.com/v2-e486af7500a211210918b7358a6cee5b_r.jpg?source=1def8aca"/>图3-13 基于思维程序提示构建的新数据用准备好的新数据对模型进行有监督微调。图3-14展示了训练过程中验证集的损失值变化,验证集损失值呈现下降趋势,最终保存了迭代1000次的模型。 <img src="https://picx.zhimg.com/50/v2-fb911dc1b04d55b98d81132303bf1fe2_720w.jpg?source=1def8aca" data-size="normal" data-rawwidth="497" data-rawheight="236" data-original-token="v2-a9a35a576782d4aaa2292eb9973687ff" class="origin_image zh-lightbox-thumb" width="497" data-original="https://pic1.zhimg.com/v2-fb911dc1b04d55b98d81132303bf1fe2_r.jpg?source=1def8aca"/>图3-14 模型训练过程验证集的损失值用Streamlit启动微调后的模型,测试其效果,选取之前的两道数学题作为输入,一道是123*145的计算,一道是四元方程的求解。图3-15显示了模型的输出结果,可以看出,模型的输出格式符合思维程序提示的要求,四则运算部分用中间变量表示,解方程部分用python的sympy函数直接求解。<img src="https://pic1.zhimg.com/50/v2-85adbf31f772a75130557013277a19bf_720w.jpg?source=1def8aca" data-size="normal" data-rawwidth="1564" data-rawheight="601" data-original-token="v2-d3ccba8a8defeda63ca7413bdf441b3a" class="origin_image zh-lightbox-thumb" width="1564" data-original="https://pica.zhimg.com/v2-85adbf31f772a75130557013277a19bf_r.jpg?source=1def8aca"/>图3-15 新模型的输出格式为思维程序为了得到图3-15中的程序代码的输出结果,需要用python解释器来运行它们,解析代码的方法如下所示。import json
import numpy as np
import pandas as pd
from scipy.optimize import minimize
import sympy
import re
from tqdm import tqdm
import math
import inspect
import inspect
# 解析函数
def parse_pot(inputs):
s = re.findall(r'<<(.*?)>>', inputs, re.DOTALL)
index = 0
for k in s:
if "func" in k:
var = k.split("=", 1)
try:
var[1] = var[1].strip(" ")
exec(var[1], globals())
ans = func()
except:
if 'sympy' in var[1]:
var[1] = var[1].replace('res[x]', 'res[0][0]')
var[1] = var[1].replace('res[y]', 'res[0][1]')
exec(var[1], globals())
ans = func()
var_list = [c.strip(" ") for c in var[0].split(",")]
if len(var_list) == 1:
ans = [ans]
for i in range(len(ans)):
try:
ans[i] = float(ans[i])
if abs(ans[i] - int(ans[i])) < 1e-10:
ans[i] = str(int(ans[i]))
except:
pass
inputs = inputs.replace("<<"+k+">>", "")
for i in range(len(var_list)):
inputs = inputs.replace(var_list[i], str(ans[i]))
index += 1
for c in range(index, len(s)):
for i in range(len(var_list)):
s[c] = s[c].replace(var_list[i], str(ans[i]))
else:
var = k.replace(" ", "").split("=")
var[1] = var[1].replace("eval", "")
ans = eval(var[1])
ans = float(ans)
if abs(ans - int(ans)) < 1e-10:
ans = str(int(ans))
inputs = inputs.replace("<<"+k+">>", "").replace(var[0], str(ans))
index += 1
for c in range(index, len(s)):
s[c] = s[c].replace(var[0], str(ans))
return inputs把上面的代码写入web_demo2.py文件,运行streamlit run web_demo2.py,就可以启动新模型,它会在输出结果之前用解析代码运行程序代码。图3-16展示了解析后的效果,可以看出,无论是简单的数值计算,还是复杂的解方程,模型都能给出正确的答案。而且,即使是涉及复杂运算的数学应用题,模型也能通过解析程序得到正确的答案。<img src="https://picx.zhimg.com/50/v2-311a051ef7090c8ca6bae5c85959d20b_720w.jpg?source=1def8aca" data-size="normal" data-rawwidth="1010" data-rawheight="733" data-original-token="v2-a82360f108b5a091b365dd3f3f85cc0d" class="origin_image zh-lightbox-thumb" width="1010" data-original="https://picx.zhimg.com/v2-311a051ef7090c8ca6bae5c85959d20b_r.jpg?source=1def8aca"/>图3-16 新模型答案解析后的输出除了四则运算和解方程,还可以增加其它程序功能,如计算时间日期、求函数极值等。此外,除了程序代码,还可以使用第三方插件,如发送邮件、绘制图表等功能。大模型作为一个智能体,能够理解人类的意图,选择最有效的解决方案,而我们只需根据需求,对大模型进行有监督微调,就能开发出更符合预期的私有大模型。 总结如今大模型百花齐放,关于大模型的文章也非常多,但是介绍如何从0开始构建自己的大模型的介绍比较少,本文系统性地介绍了如何选择合适的基座模型,以及如何使用自己的数据微调大模型。参考Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks绝密伏击:大模型思维链(Chain-of-Thought)技术原理
推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://hqyman.cn/post/9446.html 非本站原创文章欢迎转载,原创文章需保留本站地址!

 微信支付宝扫一扫,打赏作者吧~
微信支付宝扫一扫,打赏作者吧~休息一下~~