
引言
随着数据科学和机器学习的迅速发展,如何将复杂的数据处理逻辑转化为易于使用的可视化界面,已成为许多开发者面临的挑战。本文将深入探讨如何使用Python创建可视化界面,并以一个实际项目为例,展示该界面的功能和实现过程。
1. Python可视化界面基础
在Python中,有多种库可用于创建图形用户界面(GUI),如Tkinter、PyQt和Kivy。其中,Tkinter是Python内置的库,适合于快速开发简单的桌面应用程序。它具有轻量级和易于上手的特点,非常适合初学者。
2. 项目概述
我们将以一个数据处理工具为例,该工具的主要功能包括:
• 从用户选择的CSV或Excel文件中读取数据。
• 将数据上传到ODPS(开放数据处理服务)。
• 从ODPS中提取处理后的数据并导出为Excel文件。
• 在界面中显示处理日志和进度条,提供用户友好的操作体验。
3. 环境配置
首先,确保安装了所需的Python库:
pip install pandas pymysql odps4. 代码详解
以下是项目的核心代码:
import tkinter as tk
from tkinter import filedialog, messagebox
from tkinter import ttk
import threading
import time
import pymysql
import os
from datetime import datetime
from odps import ODPS
import pandas as pd
from odps.tunnel import TableTunnel
# ODPS配置
def init_odps():
odps_access_id = 'xxx'
odps_access_key = 'xxxx'
odps_project = 'xx'
odps_endpoint = 'http://service.cn-hangzhou.maxcompute.aliyun.com/api'
odps = ODPS(odps_access_id, odps_access_key, odps_project, odps_endpoint)
return odps5. 创建主界面
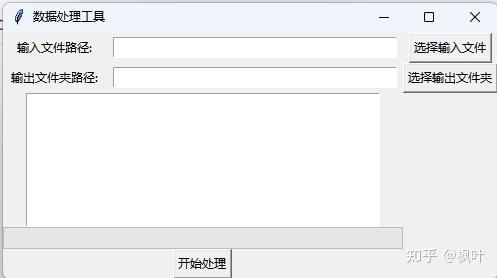
使用Tkinter构建主界面,包含输入文件路径、输出文件路径、日志显示区和进度条:
def main():
root = tk.Tk()
root.title("数据处理工具")
tk.Label(root, text="输入文件路径:").grid(row=0, column=0)
input_file_entry = tk.Entry(root, width=40)
input_file_entry.grid(row=0, column=1)
tk.Label(root, text="输出文件夹路径:").grid(row=1, column=0)
output_folder_entry = tk.Entry(root, width=40)
output_folder_entry.grid(row=1, column=1)
text_area = tk.Text(root, height=10, width=50)
text_area.grid(row=2, column=0, columnspan=2)
progress_bar = ttk.Progressbar(root, orient="horizontal", length=400, mode="determinate")
progress_bar.grid(row=3, column=0, columnspan=2)6. 处理数据逻辑
读取文件内容并将数据上传到ODPS的具体逻辑如下:
def read_file_to_df(input_file, text_area):
try:
update_log(text_area, f"正在读取文件{input_file}")
_, file_extension = os.path.splitext(input_file)
if file_extension.lower() == '.csv':
return pd.read_csv(input_file, dtype=str, thousands=',')
elif file_extension.lower() in ['.xls', '.xlsx']:
return pd.read_excel(input_file, dtype=str, thousands=',')
else:
messagebox.showerror("Unsupported file type. Please provide a CSV or Excel file.")
raise ValueError("Unsupported file type. Please provide a CSV or Excel file.")
except Exception as e:
messagebox.showerror(f"Error reading file: {e}")
raise7. 异步处理
为了避免界面在数据处理时卡顿,我们使用线程来处理数据:
def start_process(input_file, output_folder, text_area, progress_bar):
threading.Thread(target=process_data, args=(input_file, output_folder, text_area, progress_bar)).start()8. 进度条与日志更新
在用户进行数据处理时,界面会更新进度条和日志,提升用户体验:
def update_log(text_area, message):
text_area.insert(tk.END, message + '\n')
text_area.see(tk.END)9. exe 打包
pip install pyinstallerpyinstaller --onefile your_script.py# 打包时间预计2-3h ,根据实际依赖包的多少来判断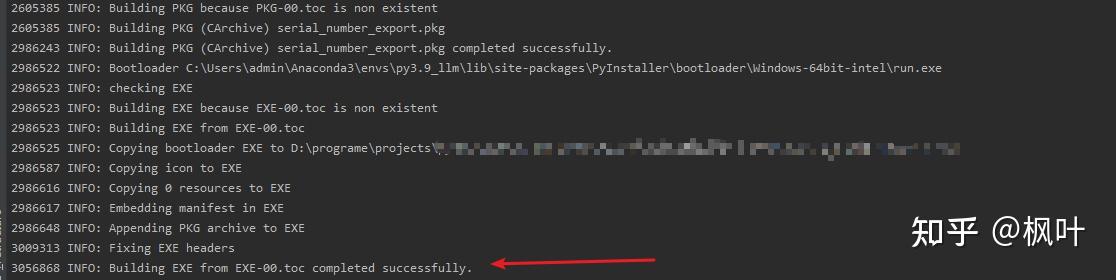
10. 附录(完整代码)
import tkinter as tk
from tkinter import filedialog, messagebox
from tkinter import ttk
import threading
import time
import pymysql
import os
from datetime import datetime
from odps import ODPS
import pandas as pd
from odps.tunnel import TableTunnel
access_key_id = 'xxx'
access_key_secret = 'xxxx'
bucket_name = 'xxxx'
endpoint = 'oss-cn-hangzhou.aliyuncs.com'
#odps
# ODPS配置
def init_odps():
odps_access_id = access_key_id
odps_access_key = access_key_secret
odps_project = 'xx'
odps_endpoint = 'http://service.cn-hangzhou.maxcompute.aliyun.com/api'
odps = ODPS(odps_access_id, odps_access_key, odps_project, odps_endpoint)
return odps
def upload_df_to_odps(odps, df):
tunnel = TableTunnel(odps)
upload_session = tunnel.create_upload_session("serial_number_input")
# 获取上传会话的写入器
writer = upload_session.open_record_writer(0)
# 将数据写入ODPS表
for index, row in df.iterrows():
record = upload_session.new_record()
for col_name in df.columns:
if col_name != 'partition_value' : # 排除 partition_value 列
record[col_name] = row[col_name].strip()
writer.write(record)
# 关闭写入器
writer.close()
# 提交上传会话
upload_session.commit([0])
def get_odps_data(odps, sql):
query_job = odps.execute_sql(sql)
result = query_job.open_reader(tunnel=True)
df = result.to_pandas(n_process=1)
return df
def read_file_to_df(input_file, text_area):
try:
update_log(text_area, f"正在读取文件{input_file}")
# 获取文件扩展名
_, file_extension = os.path.splitext(input_file)
if file_extension.lower() == '.csv':
return pd.read_csv(input_file, dtype=str, thousands=',')
elif file_extension.lower() in ['.xls', '.xlsx']:
return pd.read_excel(input_file, dtype=str, thousands=',')
else:
messagebox.showerror("Unsupported file type. Please provide a CSV or Excel file.")
raise ValueError("Unsupported file type. Please provide a CSV or Excel file.")
except Exception as e:
messagebox.showerror(f"Error reading file: {e}")
raise ValueError("Unsupported file type. Please provide a CSV or Excel file.")
def export_data_from_odps(df, output_file, text_area, progress_bar):
current_timestamp = str(int(datetime.now().timestamp()))
df['current_timestamp'] = current_timestamp
odps = init_odps()
update_log(text_area, f"正在上传文件到ODPS==>moody_bd.serial_number_input")
upload_df_to_odps(odps, df)
cnts = df.shape[0]
update_log(text_area, f"上传完后总条数为:{cnts} 上传时间戳为:{current_timestamp}")
sql = f"""
xxxxx
"""
update_log(text_area, "正在处理数据...")
progress_bar['value'] = 80
odps_df = get_odps_data(odps, sql)
odps_df = odps_df.astype(str)
odps_df.to_excel(output_file, index=False)
# 模拟数据库处理函数,假设你已经实现了数据库连接和数据处理
def process_data(input_file, output_folder, text_area, progress_bar):
try:
# 显示日志信息
df = read_file_to_df(input_file, text_area)
# 生成输出文件名
base_filename = os.path.basename(input_file)
filename_without_ext = os.path.splitext(base_filename)[0]
timestamp = datetime.now().strftime("%Y%m%d%H")
output_filename = f"{filename_without_ext}_{timestamp}.xlsx"
output_file = os.path.join(output_folder, output_filename)
export_data_from_odps(df, output_file, text_area, progress_bar)
progress_bar['value'] = 100
# 显示完成信息
update_log(text_area, "任务完成!")
# 显示日志信息
time.sleep(1) # 模拟数据处理
messagebox.showinfo("完成", "数据处理完成!")
except Exception as e:
messagebox.showerror("错误", f"发生错误: {e}")
# 更新日志函数
def update_log(text_area, message):
text_area.insert(tk.END, message + '\n')
text_area.see(tk.END)
# 开始数据库处理函数
def start_process(input_file, output_folder, text_area, progress_bar):
threading.Thread(target=process_data, args=(input_file, output_folder, text_area, progress_bar)).start()
def main():
root = tk.Tk()
root.title("数据处理工具")
# 输入文件路径
tk.Label(root, text="输入文件路径:").grid(row=0, column=0)
input_file_entry = tk.Entry(root, width=40)
input_file_entry.grid(row=0, column=1)
# 输出文件路径
tk.Label(root, text="输出文件夹路径:").grid(row=1, column=0)
output_folder_entry = tk.Entry(root, width=40)
output_folder_entry.grid(row=1, column=1)
# 日志显示区
text_area = tk.Text(root, height=10, width=50)
text_area.grid(row=2, column=0, columnspan=2)
# 进度条
progress_bar = ttk.Progressbar(root, orient="horizontal", length=400, mode="determinate")
progress_bar.grid(row=3, column=0, columnspan=2)
# 选择输入文件按钮
def select_input_file():
input_file = filedialog.askopenfilename()
input_file_entry.delete(0, tk.END)
input_file_entry.insert(0, input_file)
# 选择输出文件夹按钮
def select_output_folder():
output_folder = filedialog.askdirectory()
output_folder_entry.delete(0, tk.END)
output_folder_entry.insert(0, output_folder)
tk.Button(root, text="选择输入文件", command=select_input_file).grid(row=0, column=2)
tk.Button(root, text="选择输出文件夹", command=select_output_folder).grid(row=1, column=2)
# 开始处理按钮
tk.Button(root, text="开始处理",
command=lambda: start_process(input_file_entry.get(), output_folder_entry.get(), text_area, progress_bar)).grid(row=4, column=0, columnspan=2)
root.mainloop()
if __name__ == "__main__":
main()
推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://hqyman.cn/post/9557.html 非本站原创文章欢迎转载,原创文章需保留本站地址!

 微信支付宝扫一扫,打赏作者吧~
微信支付宝扫一扫,打赏作者吧~休息一下~~