
项目背景
因为国内无法访问内置的一些免费搜索插件,安装完searXNG本地服务端后根据教程中连接始终无法连接,docker方案国内也无法使用的情况下,本地使用python写一个Flask服务程序使用爬虫技术提供联网搜索数据。
下面是实现代码 V1
#!/usr/bin/python3
# _*_ coding: utf-8 _*_
#
# Copyright (C) 2025 - 2025
# @Title : 这是一个模拟searXNG服务器的程序实现本地搜索
# @Time : 2025/2/18 下午3:50
# @Author : Chinayeren
# @File : search-api.py
# @IDE : PyCharm
import requests
import random
import json
from bs4 import BeautifulSoup
from baidusearch.baidusearch import search as b_search
from urllib.parse import urlparse
from flask import Flask, request, jsonify
def is_valid_url(url):
"""检查URL是否是符合标准的完整URL"""
parsed_url = urlparse(url)
return parsed_url.scheme in ['http', 'https'] and parsed_url.netloc
def search_api(keyword, num_results):
"""上网搜索"""
search_results = b_search(keyword, num_results)
results = []
res_id = 0
# 生成一个0到999的随机数
sj_num = random.randint(0, 999)
for extracted_result in search_results:
res_title = extracted_result['title'].replace('\n', '')
res_abstract = extracted_result['abstract'].replace('\n', '')
res_url = extracted_result['url']
use_text = False
if is_valid_url(res_url):
# 自增长id
res_id = res_id + 1
# use_text是一个是否搜索url内部数据并替换给res_abstract提供更多简介参考数据(不太准确)
if use_text:
try:
# 请求头 使用一个随机数和一个自增长数,欺骗搜索引擎防止被屏蔽并发搜索,但是任然只允许8个并发。未修改时只允许6个可用并发。
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.%d.%d Safari/537.36'
% (sj_num, res_id)
}
# 发送HTTP GET请求到URL
response = requests.get(res_url, headers=headers)
# 检查请求是否成功
if response.status_code == 200:
# 打印页面内容的前几百个字符(避免打印过长内容)
# 使用BeautifulSoup解析HTML内容
soup = BeautifulSoup(response.content, 'html.parser')
# 提取网页中的纯文本内容并删除掉多余回车和制表符
text = soup.get_text().replace('\n', '')
text = text.replace('\r', '')
text = text.replace('\t', '')
res_abstract = text[:600]
else:
# print(f"无法访问URL,状态码: {response.status_code}")
pass
except requests.RequestException as e:
# 处理请求异常,如网络问题、超时等
# print(f"请求URL时发生错误: {e}")
pass
# 处理百度连接重定向真实连接
try:
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.%d.%d Safari/537.36'
% (sj_num, res_id)
}
res = requests.head(res_url, allow_redirects=True, headers=headers)
res_url = res.url
except requests.RequestException as e:
print(f"Error fetching URL {res_url}: {e}")
tmp_json = {
"title": res_title,
"search_id": res_id,
"content": res_abstract,
"url": res_url,
"engine": "baidu",
"category": "general",
}
results.append(tmp_json)
return results
app = Flask(__name__)
@app.route('/search', methods=['GET'])
def search():
query = request.args.get('q', '')
nums = request.args.get('num_results', 10)
if not query:
return jsonify({"error": "No query provided"}), 400
try:
nums = int(nums)
except ValueError:
return jsonify({"error": "Invalid number of results"}), 400
results = search_api(query, nums)
return jsonify({
"query": query,
"results": results
})
if __name__ == "__main__":
app.run(host='0.0.0.0', port=5000)大家如果还有更好的办法请告诉我。
百度搜索广告多且有并发屏蔽。后面我有改了一个搜索csdn的,这个数据比较纯粹。质量高于百度搜索。
代码V2
#!/usr/bin/python3
# _*_ coding: utf-8 _*_
#
# Copyright (C) 2025 - 2025
#
# @Time : 2025/2/19 下午4:13
# @Author : Chinayeren
# @File : csdn_search.py
# @IDE : PyCharm
import requests
import random
import json
from bs4 import BeautifulSoup
from urllib.parse import urlparse
from flask import Flask, request, jsonify
def csdn_search(keyword):
url = f'https://so.csdn.net/api/v3/search?q={keyword}'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Referer': 'https://so.csdn.net/so/search',
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive'
}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
# 假设 response.text 是你的 JSON 数据
json_data = response.text
# 解析 JSON 数据
data = json.loads(json_data) # 假设 response.text 是你的 JSON 数据
json_data = response.text
# 解析 JSON 数据
data = json.loads(json_data)
# 提取 result_vos 列表
result_vos = data.get('result_vos', [])
results = []
search_id = 0
# 遍历 result_vos 列表并提取需要的字段
for result in result_vos:
title = result.get('title')
content = result.get('body')
url = result.get('url')
results.append({
'title': title,
'content': content,
'url': url,
'search_id': search_id,
"engine": "csdn",
"category": "general",
})
search_id += 1
except requests.RequestException as e:
return json.dumps({'error': str(e)}, ensure_ascii=False)
return results
app = Flask(__name__)
@app.route('/search', methods=['GET'])
def search():
query = request.args.get('q', '')
if not query:
return jsonify({"error": "No query provided"}), 400
results = csdn_search(query)
return jsonify({
"query": query,
"results": results
})
if __name__ == "__main__":
app.run(host='0.0.0.0', port=5000)open-webui 联网设置 引擎选择searXNG 查询url设置成http://127.0.0.1:5000/search?q=<query>
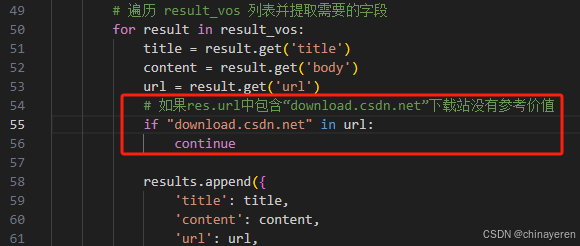
过滤掉download.csdn.net下载站没有参考价值
推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://hqyman.cn/post/9567.html 非本站原创文章欢迎转载,原创文章需保留本站地址!
打赏
 微信支付宝扫一扫,打赏作者吧~
微信支付宝扫一扫,打赏作者吧~
微信支付宝扫一扫,打赏作者吧~休息一下~~