
一、什么是SearXNG
SearXNG 是一个免费的互联网元搜索引擎,它来自各种搜索服务和数据库的结果。用户既不被跟踪,也不会被分析。
其中NG意味next generation,表示下一代,听说是项目组内部对SearX未来发展意见不合而产生的分支
简单来说,SearXNG是一个同时集成了Google、Yahoo、Bilibili甚至Pivix等各式各样的搜索引擎的搜索引擎(哈哈),并且不会被收集用户数据,以达到阻止个性化推荐这样的服务。如果你是一个注重隐私保护的用户,用用searxng也是不错的。

二、如何将SearXNG部署到自己的电脑上
作为一个不知道什么职位的什么都不会的小白,其实一开始拿到这个任务我是懵逼的。
什么是部署?怎么部署?给了我一个github链接我却连看都看不懂怎么办?
1.看懂SearXNG源
一般来说,看懂一个github项目,首先看Readme(读我)
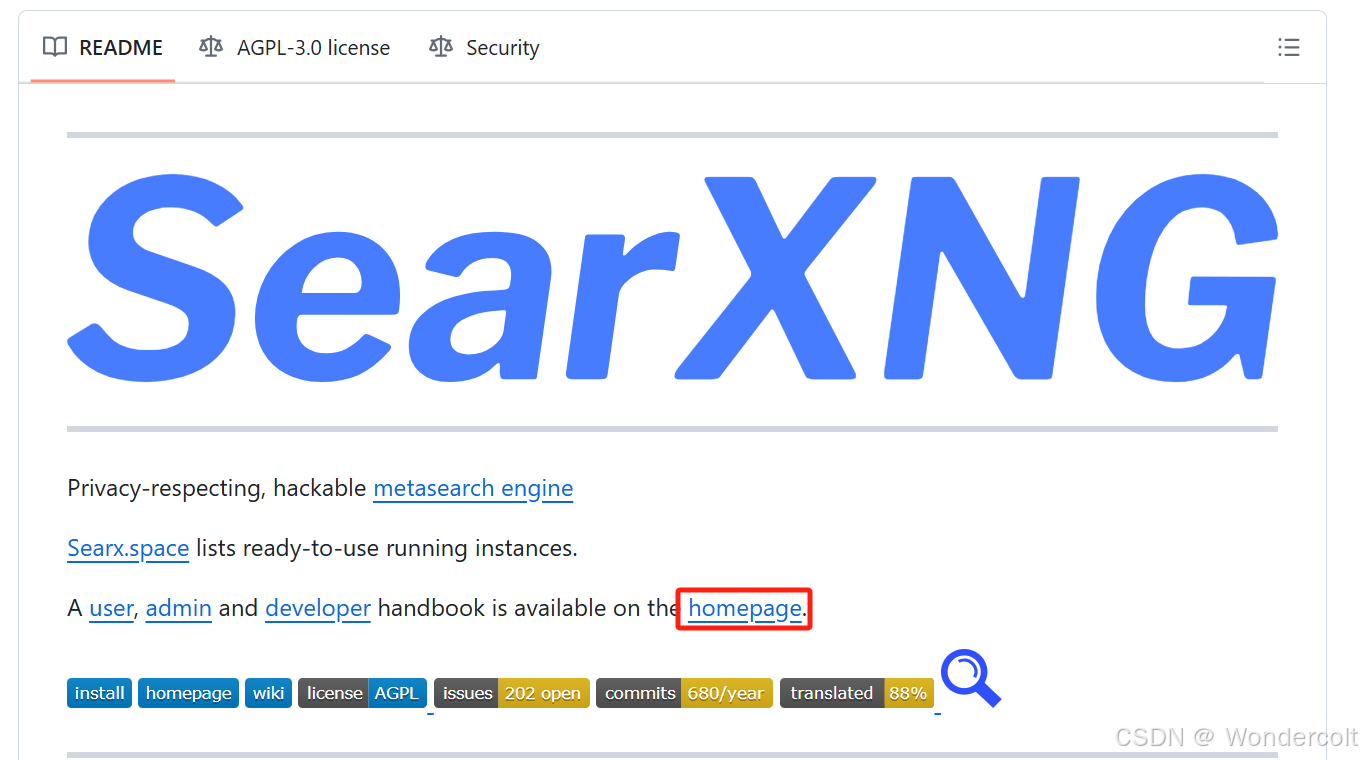
它的readme写的很简略,是因为它其实有一个专门的“说明书”,点击“homepage”就能跳转

我花了很长时间才搞清楚这份说明书的“架构”,最终锁定在“step by step installation”这一栏,里面详尽地说明了如何在本地部署自己的SearXNG,虽然是纯英文的
2.部署环境的准备
话又说回什么是部署了,到底什么是部署?我以为,部署就是把这个项目的源下载到你的电脑(或者说本地)上,以便于你自己开发调试,增加或减少自己想要的功能。例如我就需要在它集成了这么多搜索引擎的基础上,再集成一个搜狗微信的引擎。相当于,你在别人的源代码的基础上,开发出了一个个性化的属于你自己的SearXNG.可能这就是开源项目的魅力吧。
SearXNG是基于docker环境或者python环境开发的,但我不太懂什么是docker,而且貌似我的系统装不了docker?就选择基于python环境开发。(说实话我也不是很懂什么叫基于某某环境?)
(1)Anaconda
Anaconda介绍
以前不理解Anaconda的用处在哪里,想着写python用pycharm不就行了吗?
没错,在学校读书只会用pycharm写代码是这样的,我们做项目的考虑可就多了。
一个项目的部署或者叫运行,需要特定的环境,这个环境包括python的版本,以及这种包的版本。不同的项目需要的版本是不同,这Anaconda的作用就在于可以便捷的获取包,以及方便的管理不同的环境,而这些在pycharm实现起来则相对复杂。
Anaconda的下载相信大家都没问题,这里贴上我写的Anaconda的基本使用语句的blog
Anaconda虚拟环境配置
那么,我们究竟要配置什么样的环境呢?这时候我们就要深入项目文件中一探究竟。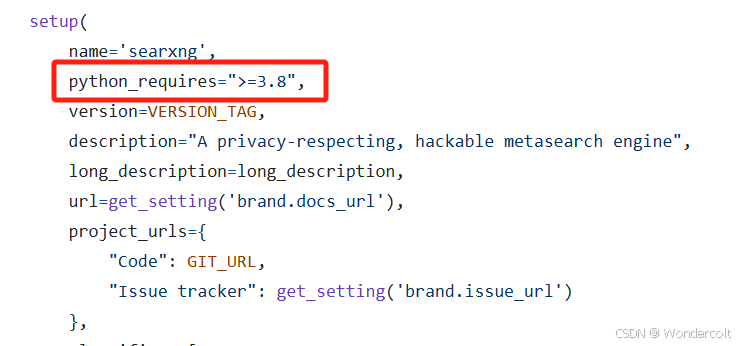
首先我们在"setup.py"文件中看到这么一句话“python_requires='>=3.8'”
也就是说我们需要3.8版本以上的python解释器
conda create --name searxng python=3.9
这里我们创建了一个叫“searxng”的版本为3.9的环境
接下来,我们观察它的项目文件中,有一个叫“requirements.txt”的文件,一般来说,一个项目的“依赖”,也就是它运行所需要的包的目录都在这个文件里写着。那么我们怎么一次性把该文件里的包一次性安装好呢?
pip install -r "requirements.txt"
这条语句将文件里的包一次性全部安装好。
注意!!!在此之前,需要用cd命令进去requirements所在的文件夹(在此之前你需要将github上的项目下载到本地),否则conda是不知道这个文件在什么地方的。
这时候我们发现,诶?怎么报错了?
原因在于,UVLoop底层使用了Unix/Linux系统的API,因此目前无法在Windows系统上安装和使用!看来我使了个坏,白忙活了一场。
(2)虚拟机与Linux
在windows系统上行不通,那我们就只能在linux系统上进行接下来的操作了,而linux系统(没有意外的话)则需要在虚拟机上构建。
教程我是看的阿b的视频-->VMware及ubuntu安装
全程无废话,这是真的。互联网真好,想学什么上网一搜就有。
ps:unbuntu(乌班图)可以理解成是linux的一个系统型号,就像win10、winX之于windows.
接下来,我们要
1.安装anaconda(尝试使用命令安装)
进入anaconda官网,找到这个界面
右键,选择复制链接。
这时候打开ubuntu,使用Ctrl+Alt+T打开终端
输入以下命令
wget https://repo.anaconda.com/archive/Anaconda3-2024.06-1-Linux-x86_64.sh
等待下载完成后,再输入
bash ~/Downloads/Anaconda3-2024.06-1-Linux-x86_64.sh
注:该语句指定了安装路径“~/Downloads/"已经安装包名称“Anaconda3-2024.06-1-Linux-x86_64.sh”,有需要可以更改路径,注意包名称与wget命令保持一致
接下来,依照上文方法配置完环境(searxng)后,我们用git clone命令将项目安装在Ubuntu本地
(searxng)$ git clone "https://github.com/searxng/searxng" \ "/home/usr/searxng"
接下来,我们需要安装指定包。与上文大同小异,此处不再赘述。
值得注意的是,环境配置环境有很关键一步如下,尽管我还不知道它的作用是什么
(searxng)$ cd /home/usr/searxng (searxng)$ pip install -e .
至此,环境配置相关基本完成。
3.虚拟机网络代理配置
首先,代理软件开启允许局域网连接

同时,记住我们的端口号7890
接下来,我们要找我们本地计算的ip
方法一
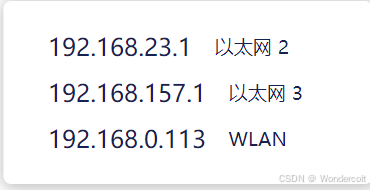
代理软件可能会自带有,这里的WLAN就是我们的ip地址
方法二
win+R,输入cmd,打开命令行窗口
C:\Users\Lenovo>ipconfig
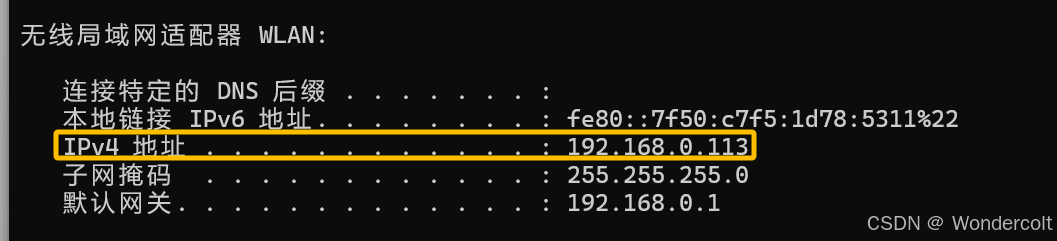
可以看到我们的IPv4地址,与刚才是一致的
紧接着,我们配置虚拟机

这一步表示虚拟机的所有网络服务操作交给主机去执行
打开虚拟机,找到网络设置
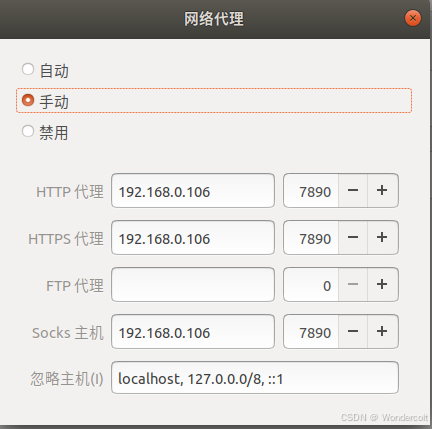
将网络代理改为手动,将这三行ip改为刚才我们查询到的ip,端口号也记得更改
此时我们已经能使用google等网站了
最后,找到searxng-->searx-->settings.yml文件
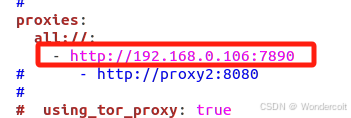
找到proxies,默认是被注释掉的,我们取消注释,并添加我们刚才查询到的ip地址
yml文件对缩进很敏感,请一定注意
4.SearXNG?启动!
$ sudo -H mkdir -p "/etc/searxng" $ sudo -H cp "/usr/local/searxng/settings.yml" \ "/etc/searxng/settings.yml"
首先在虚拟机终端执行这两条语句,命令1在指定路径创建文件夹,命令2将配置文件复制到刚才创建的文件夹
$ sudo -H sed -i -e "s/debug : False/debug : True/g" "/etc/searxng/settings.yml" (searxng)$ cd /usr/local/searxng/searx (searxng)$ export SEARXNG_SETTINGS_PATH="/etc/searxng/settings.yml" (searxng)$ python webapp.py
接着执行这四条语句,语句1打开调试模式,语句2进去指定路径,语句3引用环境变量,语句4运行app
这时候,如果没有报错,我们在虚拟机的浏览器上进入
http://127.0.0.1:8888
便成功启动SearXng了
三、如何集成微信搜索引擎到SearXNG
不出意外的话,终于要开始coding了
1.准备工作:使用VSCode远程调试虚拟机文件
详情见-->详细教学
//2024.11.02更新..鸽了这么久终于回坑了。。有很多细节的东西可能都忘了..只能大概的填坑了
糟糕,ssh: connect to host XXXX port 22: Connection refused
如果你像我一样遇见了这个报错,那么可以看看下面的视频
详情点击下方链接
如果你可以使用VScode远程调试,那么你会看到如下的界面:
当然,这个wechat.py就是我们将要编写的文件了
2.开始coding!
开始之前...
开始之前,我们需要仔细看看这个项目的架构。当然,这不是一件容易的事。对于接触项目不多的初学者来说,这简直是灾难...去网上搜资料也很少,又不好意思太去频繁地问负责人,最后之后把文件名字一个一个丢给gpt问..“这个文件是干什么的?”“那个文件是干什么的?”好在gpt也足够耐心,虽然他回答的细节可能有问题,但是整体架构还是没问题的。

在茫茫的文件夹和文件中,我们着重需要注意的是这两个。其中,requirements文件前面也说了,是需要的环境。那么这个searx,可以理解成我们这个搜索引擎的本体了
我们进去这个文件夹看看

同样的,需要我们着重注意的,一个是engines,里面存放了我们集成的搜索引擎,比如google;一个是settings,是配置文件;最后一个是webapp,是我们实现网页的方式。
简而言之,这三者的逻辑大概是,我们在engines里编写某个特定的engine,通过settings集成在一起,最后通过webapp展示。
编辑settings.yml
我们按照yml文件的格式,仿照其他引擎,编写我们wechat的配置

其中shortcut表示缩写,在我们搜索时会有用。
wechat.py的编写
我们观察到(我观察了google,yahoo和pivix..)一个引擎的py文件结构大概是
import//调包,主要是内部自己编写的包
about = {
}//配置,与setting对应
def request(query, params)://请求头
//query表示待搜索的关键字,params表示参数,如url,headers,cookies等
return params//返回参数
def response(resp)://响应
//内部用类似xpath的方法解析寻找resp.text的内容
return results//rusults中记录了搜索到的标题,内容等难点解析
(1)about的编写
about是最好写的,因为只要仿照别的配置文件就没问题
我的about是这样写的,大家的差不多就行
about={
"website": 'https://weixin.sogou.com/weixin',
"wikidata_id": None,
"official_api_documentation": None,
"use_official_api": False,
"require_api_key": False,
"results": 'HTML',
}
categories = ['general', 'web']
paging = True
time_range_support = False只要注意categories中'general'表示 常用,'web'表示引擎返回结果是网页,这些参照google的编写就没问题
(2)requests中params究竟有哪些参数?
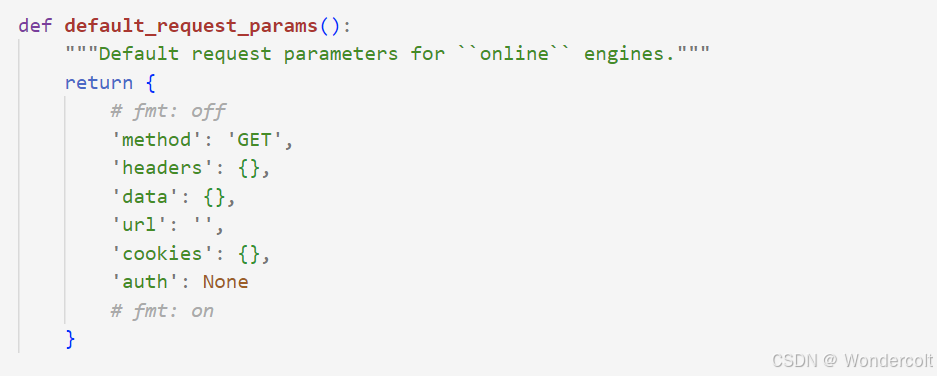
关于这个问题,我们似乎能从一个叫online.py的文件的params的初始化中寻到答案
(至于我是怎么找到的,我只能说这是一个艰苦卓绝的过程..)

但最重要的是第116行的代码,超级无敌重要,因为有很多报错会错在这里。。
也就是说,params里最重要的还是url的构建
(3)XPath
在response方法中,我们需要用类似xpath的方式在爬取公众号的标题,内容等等,也就是说我们得先学xpath->xpath学习
如果学习好xpath,我们再对照着其他搜索引擎看看项目本身编写的类xpath方法是怎么用的,很相似就是了。
(4)搜狗微信的爬取
由于搜狗微信存在很强的反爬机制,我们在爬虫这块得多下点功夫了。
import re
import requests
# from bs4 import BeautifulSoup
from lxml import etree
from urllib.parse import quote
import random
# import time
# from lxml import etree
def url_decode(r):
url = 'https://weixin.sogou.com' + r
b = random.randint(0, 99)
a = url.index('url=')
a = url[a + 30 + b:a + 31 + b:]
url += '&k=' + str(b) + '&h=' + a
return url
usr_agents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) \
Chrome/127.0.0.0 Safari/537.36 Edg/127.0.0.0',
'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:109.0) Gecko/20100101 Firefox/113.0',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)\
Chrome/83.0.4103.116 Safari/537.36'
]
cks = [
'ABTEST=0|1722388018|v1; SUID=A2FECF7C1252A20B0000000066A98E32; \
IPLOC=CN1100; SUID=A2FECF7C1AA7A20B0000000066A98E34; SUV=005224EA7CCFFEA266A99380942FF064; \
ssuid=6905076304; PHPSESSID=laqcp42b40k82bcnplh7e47to1; SNUID=194273C0BCBDA49EE380D5D1BC347914; \
ariaDefaultTheme=undefined',
'ABTEST=7|1722413935|v1; SUID=A2FECF7C8E52A20B0000000066A9F36F; IPLOC=CN1100; \
SUV=00364C407CCFFEA266A9F3708B596656; SUID=A2FECF7CC254A20B0000000066A9F31D; \
SNUID=CD8EBF1370767184577E281070766C3A; ariaDefaultTheme=undefined'
]
def create_hdr():
hdr = {
'User-Agent': usr_agents[1],
'Cookie': cks[0],
'Referer': 'https://weixin.sogou.com/weixin?query=12306&type=2&page=1&ie=utf8'
}
return hdr
def crowler(keyword: str):
kw_encoded = quote(keyword)
proxy = {'http': '127.0.0.1:7890', 'https': '127.0.0.1:7890'}
for page in range(1, 2):
url = 'https://weixin.sogou.com/weixin?query={}&type=2&page={}'.format(kw_encoded, page)
response = requests.get(url, headers=create_hdr(), proxies=proxy)
urls = []
if response.status_code >= 300:
print(response.status_code)
else:
print(response.text)
tree = etree.HTML(response.text)
for ele in tree.xpath('//div[@class="txt-box"]/h3/a/@href'):
href = url_decode(ele)
urls.append(href)
# print(ele)
# 读取新得到的url
# print(urls[0])
if len(urls) == 0:
print(response.url)
# strr = tree.xpath('//div[@class="content-box"]/p[@class="p2"]/text()')
# print(strr)
for j in urls:
resp = requests.get(j, headers=create_hdr(), proxies=proxy)
# sss = resp.content.decode('utf8')
parsed_url_list = re.findall(r"url \+= '(.+)'", resp.text)
parsed_url = ''.join(parsed_url_list)
parsed_url = re.sub(r'@', r'', parsed_url)
print(parsed_url)
if __name__ == '__main__':
crowler('12306')这里我贴上用pycharm编写的爬虫程序,原理不在这里过多讲述。
但是,尽管能搜狗微信在短时间内爬取数量过多时,会触发验证机制。这就是这个项目没有很好解决的需要改进的地方。目前的方法是等一段时间再爬取,或者直接提示触发反爬。
综上
from urllib.parse import (
quote,
urlencode,
)
from lxml import html
import random
import requests
import re
from searx.utils import (
eval_xpath_getindex,
eval_xpath_list,
extract_text,
)
from time import sleep
URL = ''
hder = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) \
Chrome/127.0.0.0 Safari/537.36 Edg/127.0.0.0',
'Cookie': 'ABTEST=0|1722388018|v1; SUID=A2FECF7C1252A20B0000000066A98E32; \
IPLOC=CN1100; SUID=A2FECF7C1AA7A20B0000000066A98E34; SUV=005224EA7CCFFEA266A99380942FF064; \
ssuid=6905076304; PHPSESSID=laqcp42b40k82bcnplh7e47to1; SNUID=194273C0BCBDA49EE380D5D1BC347914; \
ariaDefaultTheme=undefined',
}
# proxy = {'http': '192.168.0.123', 'https': '192.168.0.123'}
about={
"website": 'https://weixin.sogou.com/weixin',
"wikidata_id": None,
"official_api_documentation": None,
"use_official_api": False,
"require_api_key": False,
"results": 'HTML',
}
categories = ['general', 'web']
paging = True
time_range_support = False
def request(query, params):
global URL
base_url = 'http://weixin.sogou.com/weixin'
args = urlencode(
{
'query':quote(query),
'page':1,
'type':2,
}
)
global URL
URL = base_url + '?' + args
# params['url'] = base_url + '?' + args
word_pools = ['nihao', 'hello', 'nihaoma', 'how are you']
params['url'] = f'https://www.google.com.hk/search?q={random.choice(word_pools)}'
params['headers']['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)\
Chrome/127.0.0.0 Safari/537.36 Edg/127.0.0.0'
params['cookies'] = {'ABTEST': '0|1722388018|v1',
'SUID': 'A2FECF7C1252A20B0000000066A98E34',
'IPLOC': 'CN1100',
'SUV': '005224EA7CCFFEA266A99380942FF064',
'ssuid': '6905076304',
'PHPSESSID': 'laqcp42b40k82bcnplh7e47to1',
'SNUID': '194273C0BCBDA49EE380D5D1BC347914',
'ariaDefaultTheme': 'undefined'
}
return params
def parse_url(url_string):
url = 'https://weixin.sogou.com' + url_string
b = random.randint(0, 99)
a = url.index('url=')
a = url[a + 30 + b:a + 31 + b:]
url += '&k=' + str(b) + '&h=' + a
return url
def parse_url2(url_string):
resp = requests.get(url_string, headers=hder)#, proxies=proxy)
if resp.status_code >= 300:
print(resp.status_code)
parsed_url_list = re.findall(r"url \+= '(.+)'", resp.text)
parsed_url = ''.join(parsed_url_list)
parsed_url = re.sub(r'@', r'', parsed_url)
return parsed_url
def response(resp):
results = []
for page in range(1,6):
global URL
URL += f'&page={page}'
respp = requests.get(URL,headers=hder)#,proxies=proxy)
vrfy_str = '此验证码用于确认这些请求是您的正常行为而不是自动程序发出的,需要您协助验证'
if vrfy_str in respp.text:
text = f'搜狗微信触发反爬程序,请过段时间使用该引擎,或点击验证(跳转到搜狗界面),第{page}页'
results.append({'url': respp.url, 'title': 'weixin_verify', 'content': text})
else:
dom = html.fromstring(respp.text)
print(respp.text)
for result in eval_xpath_list(dom, '//div[contains(@class,"txt-box")]'):
url = eval_xpath_getindex(result, './/h3/a/@href', 0, default=None)
if url is None:
print("???")
continue
url = parse_url(url)
print(url)
urll = parse_url2(url)
print(urll)
if urll != '':
url = urll
title1 = eval_xpath_getindex(result, './/h3//a/text()', 0, default='')
title2 = eval_xpath_getindex(result, './/h3//a/text()', 1, default='')
title3 = eval_xpath_getindex(result, './/h3//a/text()', 2, default='')
title_em1 = eval_xpath_getindex(result, './/h3//a/em/text()', 0, default='')
title_em2 = eval_xpath_getindex(result, './/h3//a/em/text()', 1, default='')
if title2 == '':
title = extract_text(title_em1 + title1)
else:
title = extract_text(title1+title_em1+title2+title_em2+title3)
content = eval_xpath_getindex(result, './/p[contains(@class, "txt-info")]', 0, default='')
content = extract_text(content, allow_none=True)
# append result
results.append({'url': url, 'title': title, 'content': content})
return results我在这里贴上了完整的wechat.py的文件。注:这里使用的方法是绕开searxng自己编写的request函数,而是采取了调用第三方requests库的方式(频繁触发反爬真的很头疼,所以采用这种方法增加页面的可塑性)。当然,使用自带函数也可以,但是没那么自由就是了。如果有机会我会再贴上这种方法的完整代码的。
四、结语
这个项目作为我的实习内容来说确实是有一定挑战的,很多时候就是看着电脑发懵,完全不知所措,不知道问题出在哪里,不会很多方法和技术。但是这一个月时间也是慢慢磨练自己吧,从不会到自学到会的过程真的很爽。虽然自己深知自己做出来的东西其实还是个不完美的残次品,但它的存在也能极大程度的激励我,每每遇到困难时便能回想起来当时的经历,相信自己,没什么问题是没办法解决的。
推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://hqyman.cn/post/9573.html 非本站原创文章欢迎转载,原创文章需保留本站地址!

 微信支付宝扫一扫,打赏作者吧~
微信支付宝扫一扫,打赏作者吧~休息一下~~