
环境准备
1.anaconda
2.python 环境
3.vllm
4.Linux 系统(以下操作以 WSL 为例)
配置步骤
一、 启用 WSL
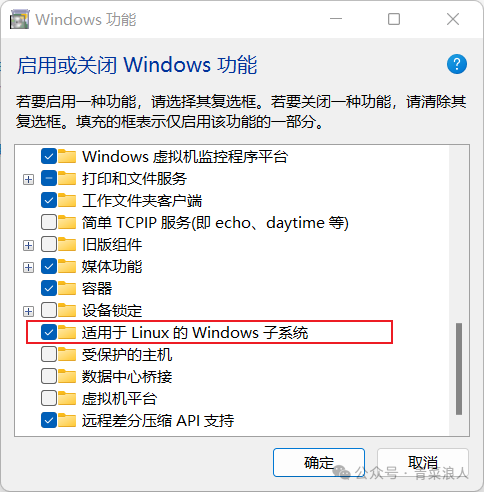
1.在控制面板=>windows 功能=>启用 WSL
2.下载 Ubuntu 最新版
由于应用商店内下载速度较慢,这里直接去官网下载 wsl 安装包
https://releases.ubuntu.com/noble/ubuntu-24.04.2-wsl-amd64.wsl
3.安装 Ubuntu
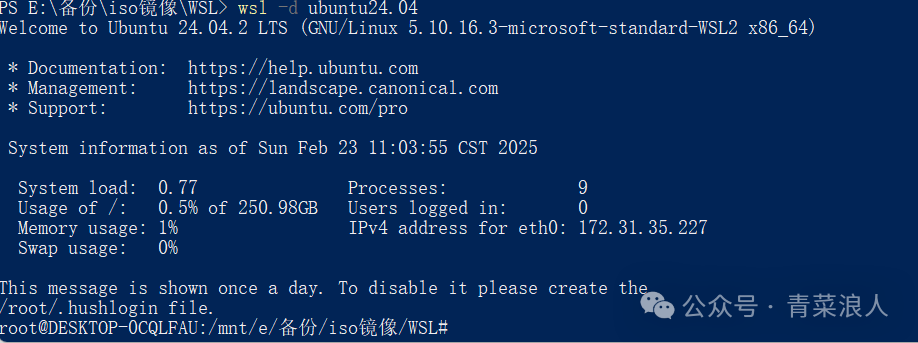
wsl --import ubuntu24.04 . ubuntu-24.04.2-wsl-amd64.gz //导入镜像 wsl -d ubuntu24.04 //进入系统内部
4.修改源为阿里云源
vi /etc/apt/sources.list.d/ubuntu.sourcesTypes: deb deb-srcURIs: https://mirrors.aliyun.com/ubuntu/Suites: noble noble-security noble-updates noble-proposed noble-backportsComponents: main restricted universe multiverseSigned-By: /usr/share/keyrings/ubuntu-archive-keyring.gpg
5.安装完成后 Ubuntu 无法访问互联网

解决方法:
(1)访问https://github.com/sakai135/wsl-vpnkit/releases下载二进制文件。
wsl --import wsl-vpnkit $env:USERPROFILE\wsl-vpnkit wsl-vpnkit.tar.gz --version 2 wsl -d wsl-vpnkit
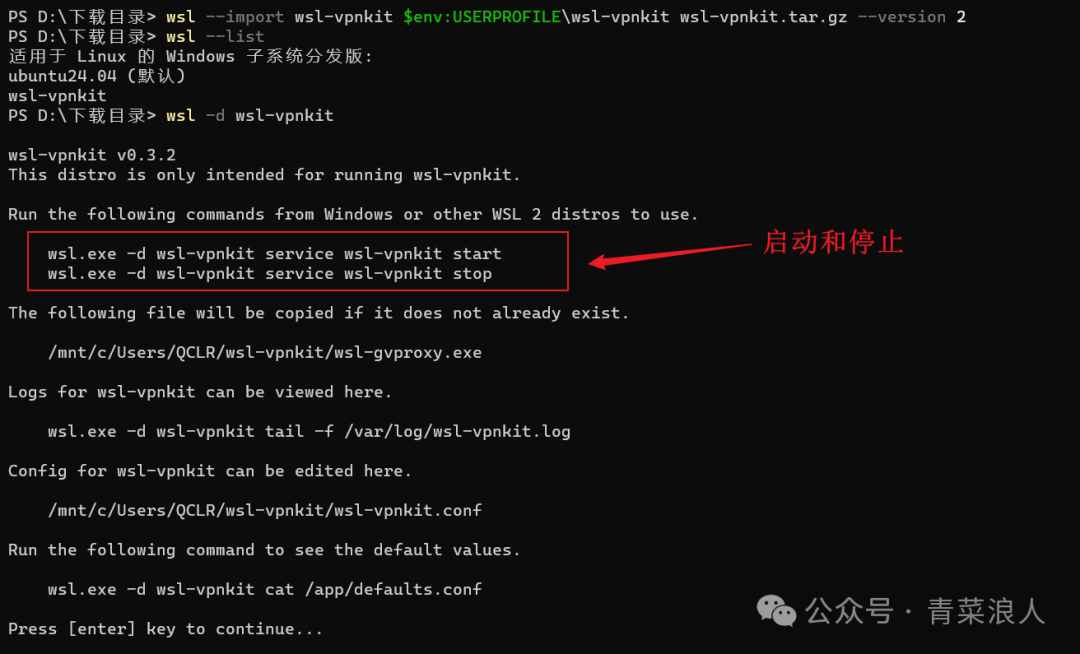
(2)运行后可以看到配置文件位置,以及启停命令
(3)启动服务
wsl.exe -d wsl-vpnkit service wsl-vpnkit start
(4)启动后,可以在网卡配置中看到新创建的网卡
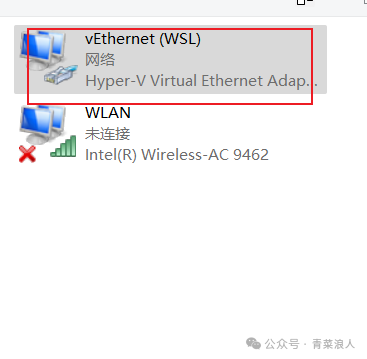
(5)此时再次进入 Ubuntu 内,网络连接恢复正常

二、显卡驱动安装
1.去官网下载显卡驱动程序,确保当前显卡版本为最新
https://www.nvidia.cn/software/nvidia-app/

2.查看当前支持的 CUDA 版本
注:VLLM 支持 CUDA11.8 及以上版本,低于这个版本可能导致无法使用
nvidia-smi.exe
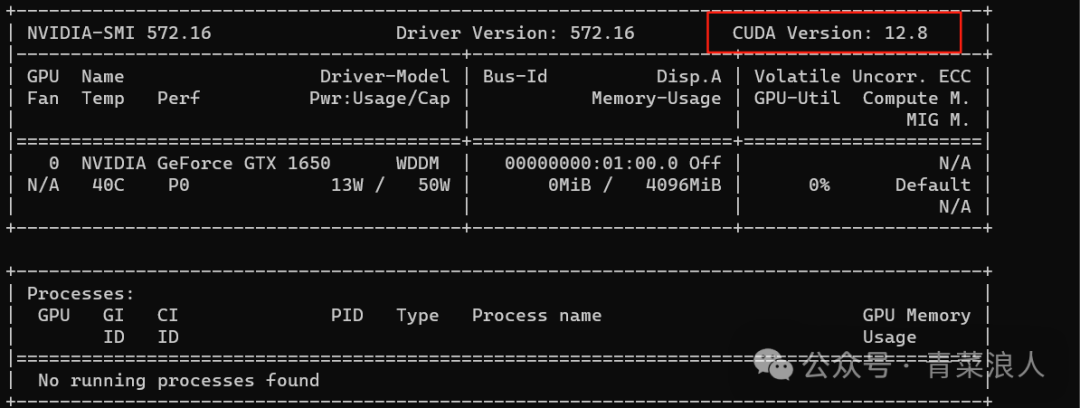
3.在 Ubuntu 内安装对应版本的 cuda
安装依赖包
apt install gcc-12 g++-12 -y #创建软链接 ln -s /usr/bin/gcc-12 /usr/local/bin/gcc ln -s /usr/bin/g++-12 /usr/local/bin/g++
选择合适自己的版本进行下载
https://developer.nvidia.com/cuda-toolkit-archive
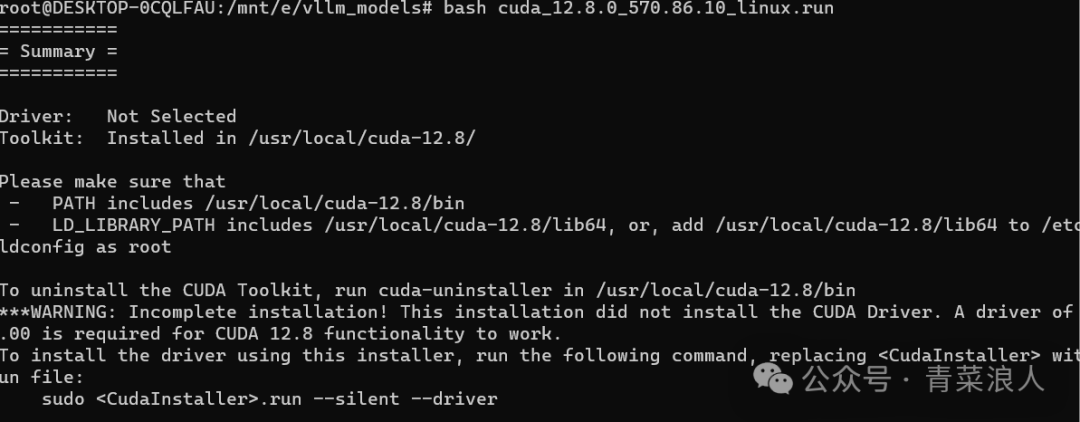
4. 根据上一步的提示,我这里需要安装 cuda-12.8,如型号与我一致可按以下顺序执行命令。
#以下命令均为root用户执行,如为其他用户请加sudo wget bash cuda_12.8.0_570.86.10_linux.run
安装成功后如下图所示 :
5.配置环境变量
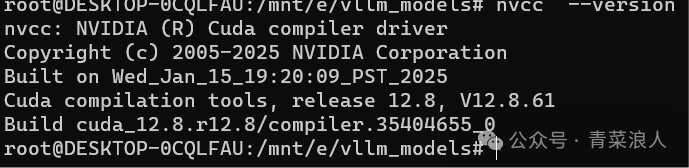
#配置环境变量 vi ~/.bashrc //在文件末尾添加以下内容 export PATH=/usr/local/cuda-12.8/bin:$PATH export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH #使配置立即生效 source ~/.bashrc #查看版本 nvcc -V
三、安装 conda
1. 在 Ubuntu 中下载对应版本安装
https://mirrors.tuna.tsinghua.edu.cn/anaconda/
2. 下载成功后,执行安装文件
./Anaconda3-5.3.1-Linux-x86_64.sh
PS:如执行出现以下报错

3.安装依赖包后再次执行脚本
apt install -y bzip2
4.出现下图时,表示安装完成
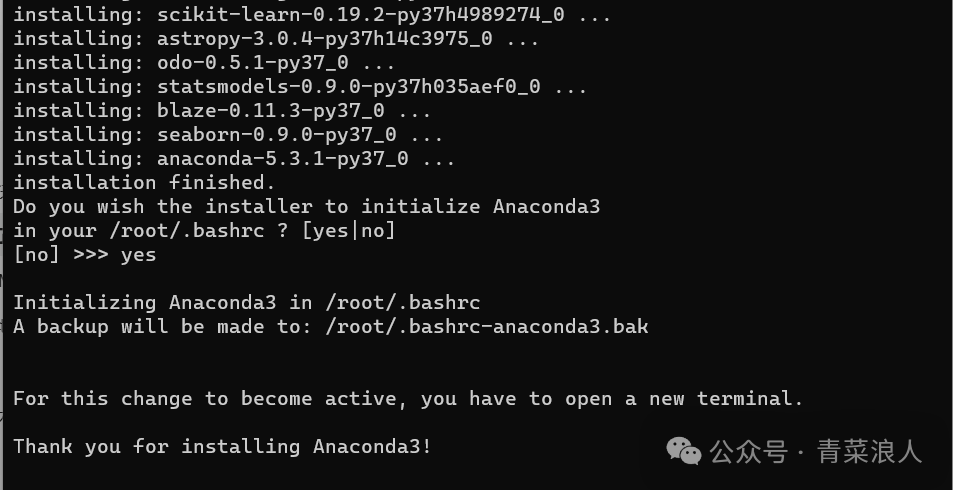
四、VLLM 安装
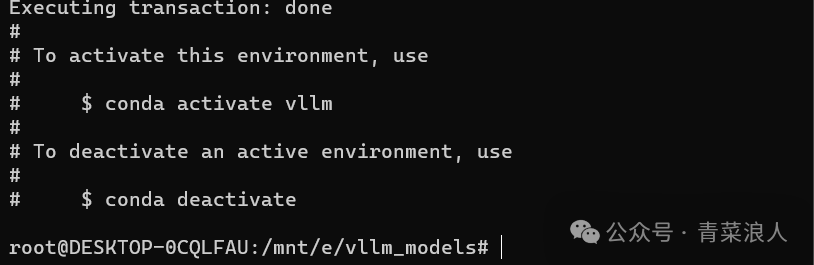
1. 新创建一个 python3.10 的环境
#创建一个名称为vllm的python环境conda create -n vllm python=3.10 -y#激活conda activate vllm
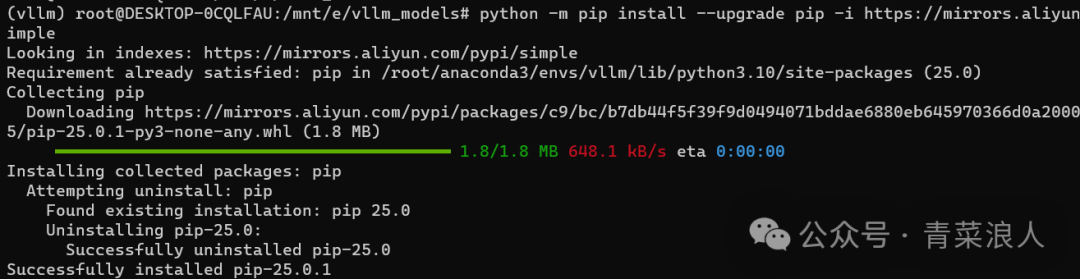
2.更新 pip,保证其为最新版
#安装前更新pippython -m pip install --upgrade pip -i https://mirrors.aliyun.com/pypi/simple
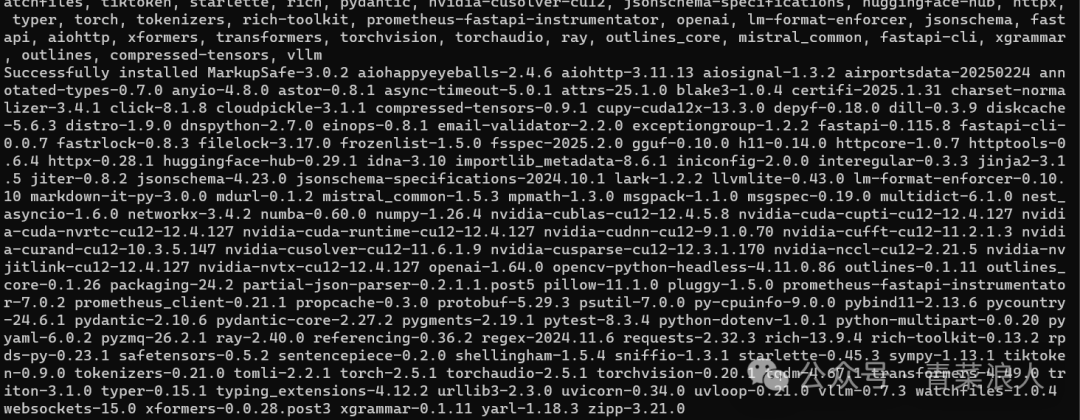
3.安装 VLLM
python -m pip install vllm -i https://mirrors.aliyun.com/pypi/simple
安装成功如下图所示:
五、大模型下载&运行
PS: 下载模型方法这里不再赘述,可参考往期文章:告别复杂配置!轻松使用VLLM部署大模型
1. 运行下载好的本地模型:
vllm serve /mnt/e/vllm_models/Qwen0.5b --max-model-len 32768 --enforce-eager --gpu-memory-utilization 0.9 --api-key TEST@123 --dtype half
出现下图,则表示运行成功

2. 在客户端中填写 API 密钥与地址,就可以识别到本地模型了
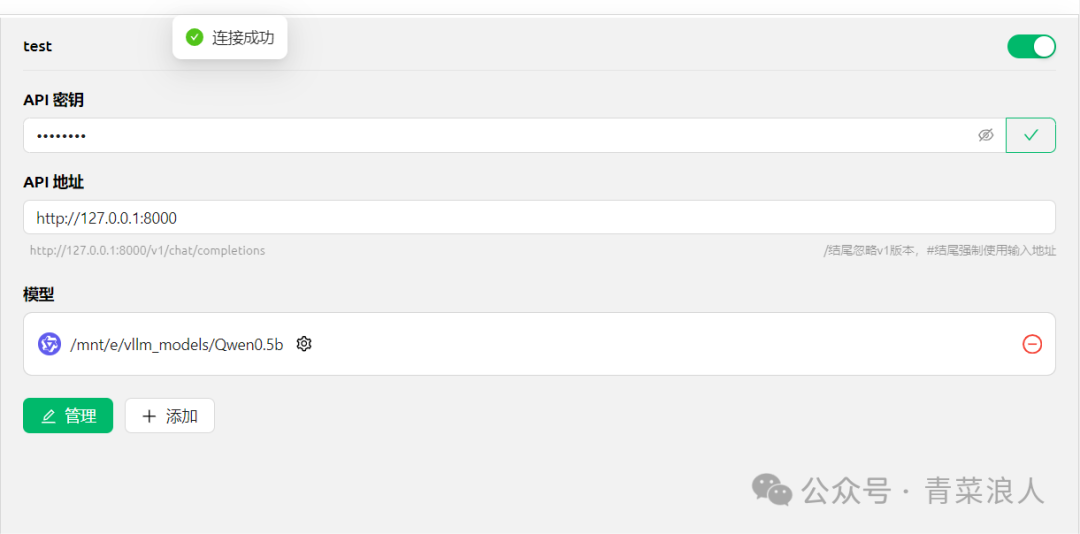
3. 此时就可以在客户端正常进行对话了

推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://hqyman.cn/post/9710.html 非本站原创文章欢迎转载,原创文章需保留本站地址!

 微信支付宝扫一扫,打赏作者吧~
微信支付宝扫一扫,打赏作者吧~休息一下~~