
#安装驱动 dpkg -i nvidia-driver-local-repo-ubuntu2004-570.86.15_1.0-1_amd64.deb cp /var/nvidia-driver-local-repo-ubuntu2004-570.86.15/nvidia-driver-local-C202025D-keyring.gpg /usr/share/keyrings/ apt-get update #安装驱动,甚至都不用安装cuda驱动就可以,安装完成系统需要重启系统 apt-get install nvidia-driver-570 reboot
#安装Docker
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu focal stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
apt update
apt install -y docker-ce docker-ce-cli containerd.io
systemctl start docker
systemctl enable docker
#安装
nvidia-dockerdistribution=$(. /etc/os-release;
echo $ID$VERSION_ID)curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
apt-get update
apt-get install -y nvidia-docker2
systemctl restart docker
wget https://github.com/vllm-project/vllm/blob/main/examples/online_serving/run_cluster.sh
bash run_cluster.sh \ vllm/vllm-openai:latest \ 172.16.0.102 \ --head \ /root/deepseekr1_32b/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B \ -e VLLM_HOST_IP=172.16.0.102 \ -e GLOO_SOCKET_IFNAME=eth0 \ -e TP_SOCKET_IFNAME=eth0 &
bash run_cluster.sh \ vllm/vllm-openai:latest \ 172.16.0.102 \ --worker \ /root/deepseekr1_32b/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B \ -e VLLM_HOST_IP=172.16.0.43 \ -e GLOO_SOCKET_IFNAME=eth0 \ -e TP_SOCKET_IFNAME=eth0 &
bash run_cluster.sh \ vllm/vllm-openai:latest \ 172.16.0.102 \ --worker \ /root/deepseekr1_32b/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B \ -e VLLM_HOST_IP=172.16.0.65 \ -e GLOO_SOCKET_IFNAME=eth0 \ -e TP_SOCKET_IFNAME=eth0 &
#进入主节点容器 docker exec -it node bash
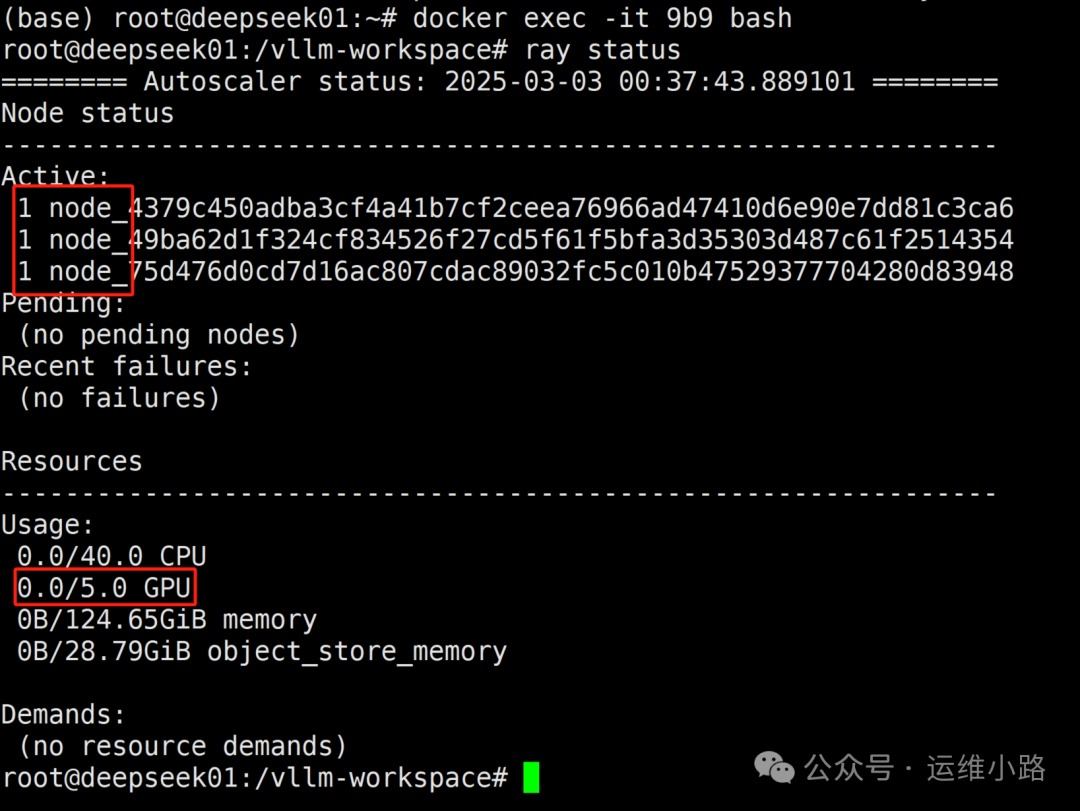
#进入主节点容器docker exec -it node bash
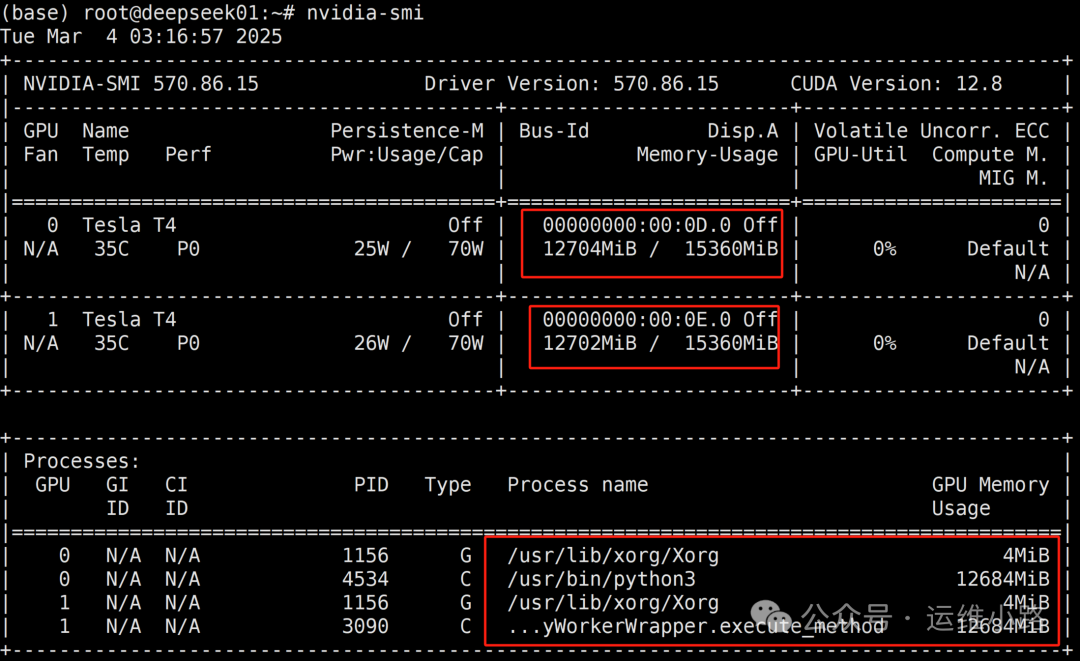
vllm serve \ --model-path /root/.cache/huggingface/ \ --tensor-parallel-size 2 \ --pipeline-parallel-size 3 \ --served-model-name "DeepSeek" \ --host 0.0.0.0 \ --port 8000 \ --gpumemoryutilization 0.95 \ --trust-remote-code \ --max-num-batched-tokens 8192 \ --max-model-len 16384 \ --enable-reasoning \ --reasoning-parser deepseekr1 \ --enable-prefix-caching \ --enable-chunked-prefill \ --dtyp=half
/root/.cache/huggingface/:指定模型存储路径,其实就是我们启动容器的挂载进去的目录--tensor-parallel-size 2 设置张量并行度为2,这意味着模型将在两个GPU上分割运行。简单理解就是每个机器有几张卡就选多少。--pipeline-parallel-size 3 设置流水线并行度为3,模型将被分为三个阶段来执行。简单理解就是有几个机器都选多少。--served-model-name "DeepSeek":设置服务暴露的模型名称为 “DeepSeek”。--host 0.0.0.0:设置服务监听所有的网络接口。--port 8000:设置服务端口为8000。--gpu_memory_utilization 0.95:设置GPU显存利用率阈值为95%。--trust-remote-code:允许执行模型自定义代码,这可能会带来安全风险。--max-num-batched-tokens 8192:设置单批次最大token数为8192。--max-model-len 16384:设置模型最大上下文长度为16384。--enable-reasoning:启用推理增强模式。--reasoning-parser deepseek_r1:指定推理解析器为 “deepseek_r1”。--enable-prefix-caching:激活前缀缓存优化。--enable-chunked-prefill:启用分块预填充。--dtype=half:使用半精度浮点数(FP16),这有助于减少显存使用并可能提高推理速度。

推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://hqyman.cn/post/9750.html 非本站原创文章欢迎转载,原创文章需保留本站地址!

 微信支付宝扫一扫,打赏作者吧~
微信支付宝扫一扫,打赏作者吧~休息一下~~