
在观察一个 Web 服务器的日志的时候,看到一个现象,有大量的网络爬虫,或者说网络蜘蛛来访问,抓取内容。这个访问数量有些过分。
看这个截图。
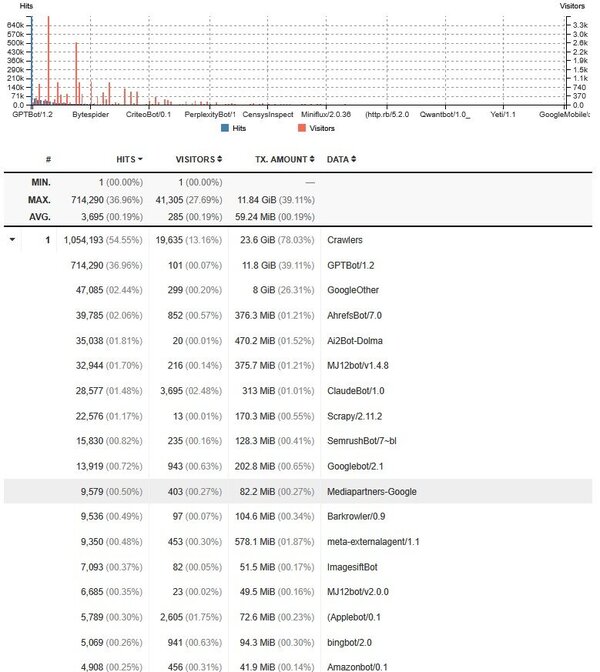 排名最前的十位如下:
排名最前的十位如下:
| 714,290 (36.96%) | 101 (00.07%) | 11.8 GiB (39.11%) | GPTBot/1.2 |
| 47,085 (02.44%) | 299 (00.20%) | 8 GiB (26.31%) | GoogleOther |
| 9,350 (00.48%) | 453 (00.30%) | 578.1 MiB (01.87%) | meta-externalagent/1.1 |
| 35,038 (01.81%) | 20 (00.01%) | 470.2 MiB (01.52%) | Ai2Bot-Dolma |
| 39,785 (02.06%) | 852 (00.57%) | 376.3 MiB (01.21%) | AhrefsBot/7.0 |
| 32,944 (01.70%) | 216 (00.14%) | 375.7 MiB (01.21%) | MJ12bot/v1.4.8 |
| 28,577 (01.48%) | 3,695 (02.48%) | 313 MiB (01.01%) | ClaudeBot/1.0 |
| 3,953 (00.20%) | 967 (00.65%) | 297.4 MiB (00.96%) | Bytespider |
| 13,919 (00.72%) | 943 (00.63%) | 202.8 MiB (00.65%) | Googlebot/2.1 |
| 22,576 (01.17%) | 13 (00.01%) | 170.3 MiB (00.55%) | Scrapy/2.11.2 |
排最前面的几位就是 GPTBot, GoogleOther, A12Bot-dolma,之流。都属于人工智能派出来的网络蜘蛛,来各个网站抓取内容,而它们抓取的内容会怎样使用的,会给你的网站带来访客吗?
基本上是不会的,本质上,这些机器人会抓取你的内容,然后进行索引,对其重组织后,来产生人工智能所编写的内容。
这意味着任何用 ChatGPT 之类的智能工具所攥写的内容都是在剽窃你我的内容。
作为内容的创造者,你会愿意无偿提供内容给他们吗?
来看看 OpenAI 的 GPTBot 干了什么吧?
网站的站长允许 GPTBot 来抓取网站内容,就意味着允许 OpenAI:
使用你的内容来训练人工智能模型
使用你的网站信息来生成 AI 内容
增加了额外的服务器负担,影响普通访客访问网站的效果
作为内容的创造者,我对滥用 AI 的能力,无偿使用原创者的作品,十分担忧,也很反对。
目前我采用了 robots.txt 来封锁 GPTBot 和其它的一些人工智能 robot。
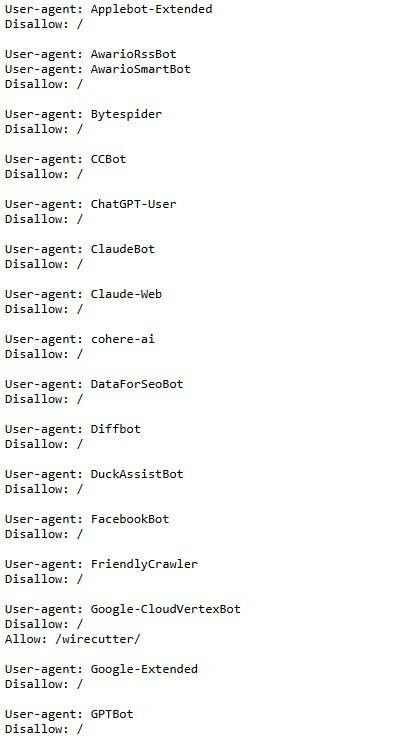 如果还有新出来的人工智能机器人,我不介意把他们加上去,在没有合理的使用原创内容方法之前,还是都封掉为好。
如果还有新出来的人工智能机器人,我不介意把他们加上去,在没有合理的使用原创内容方法之前,还是都封掉为好。
推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://hqyman.cn/post/9820.html 非本站原创文章欢迎转载,原创文章需保留本站地址!

 微信支付宝扫一扫,打赏作者吧~
微信支付宝扫一扫,打赏作者吧~休息一下~~