
本文使用 llama.cpp 本地部署 DeepSeek-R1 模型。
llama.cpp 介绍
Github 地址:https://github.com/ggerganov/llama.cpp 下载地址:https://github.com/ggerganov/llama.cpp/releases 下载 llama.cpp 首先,根据自己电脑硬件配置下载相应版本的 llama.cpp 软件,如下图: 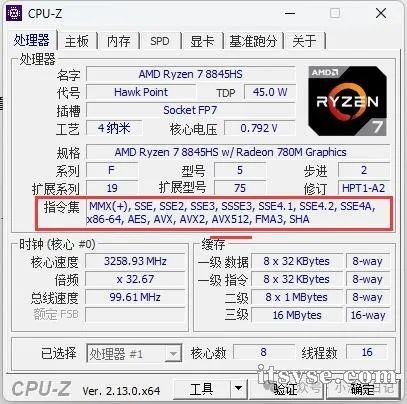 AVX 支持 256 位宽的操作。 AVX2 也支持 256 位宽的操作,但增加了对整数操作的支持以及一些额外的指令。 AVX-512 支持 512 位宽的操作,提供了更高的并行度和性能,特别是在处理大量数据或浮点运算时。 我电脑是纯 CPU 运行,并且支持 avx512 指令集,所以下载“”版本,下载地址:https://github.com/ggerganov/llama.cpp/releases/download/b4658/llama-b4658-bin-win-avx512-x64.zip,下载完成后,解压到 D:\llama-b4658-bin-win-avx512-x64 目录。 下载 DeepSeek-R1 模型 下载地址:https://hf-mirror.com/lmstudio-community/DeepSeek-R1-Distill-Qwen-1.5B-GGUF/tree/main,本文以“DeepSeek-R1-Distill-Qwen-1.5B-Q3_K_L.gguf”为例。 根据自己配置下载即可。量化级别越高,文件越大,模型精度越高。 llama.cpp 部署 DeepSeek-R1 模型 在 DeepSeek-R1-Distill-Qwen-1.5B-Q3_K_L.gguf 文件目录下面执行如下命令:
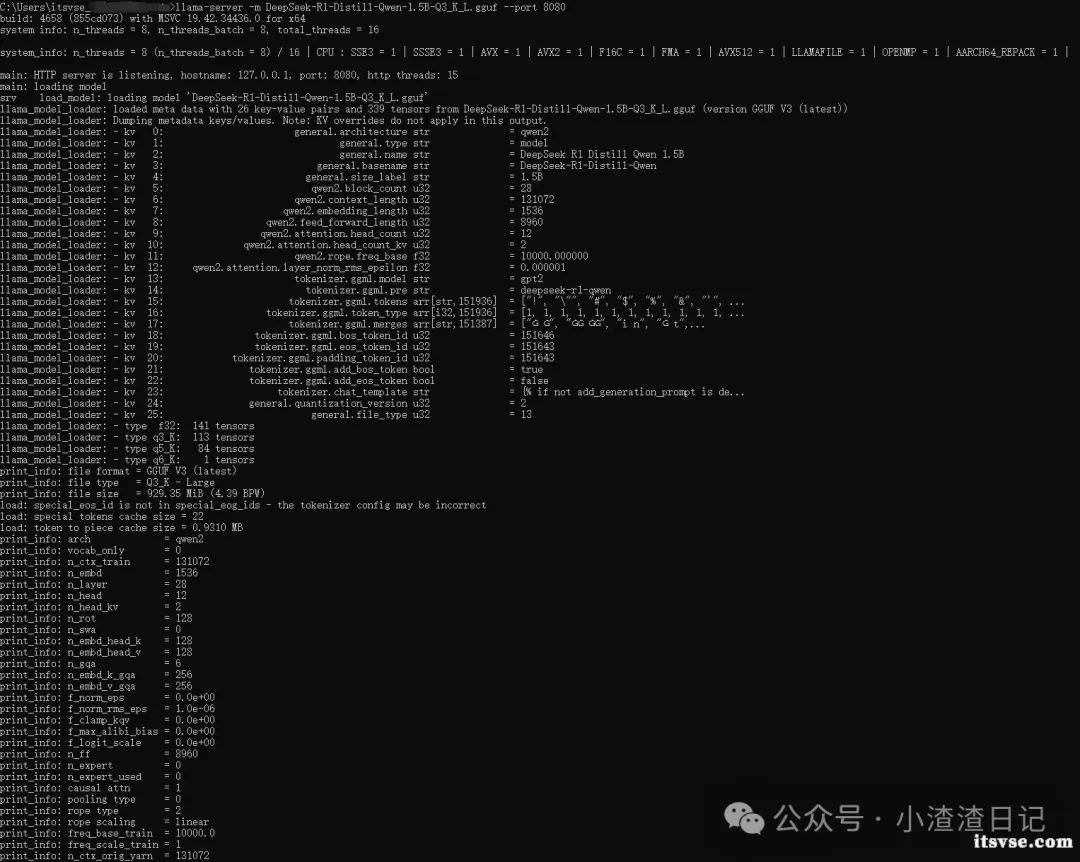 使用浏览器打开 http://127.0.0.1:8080/ 地址进行测试,如下图: 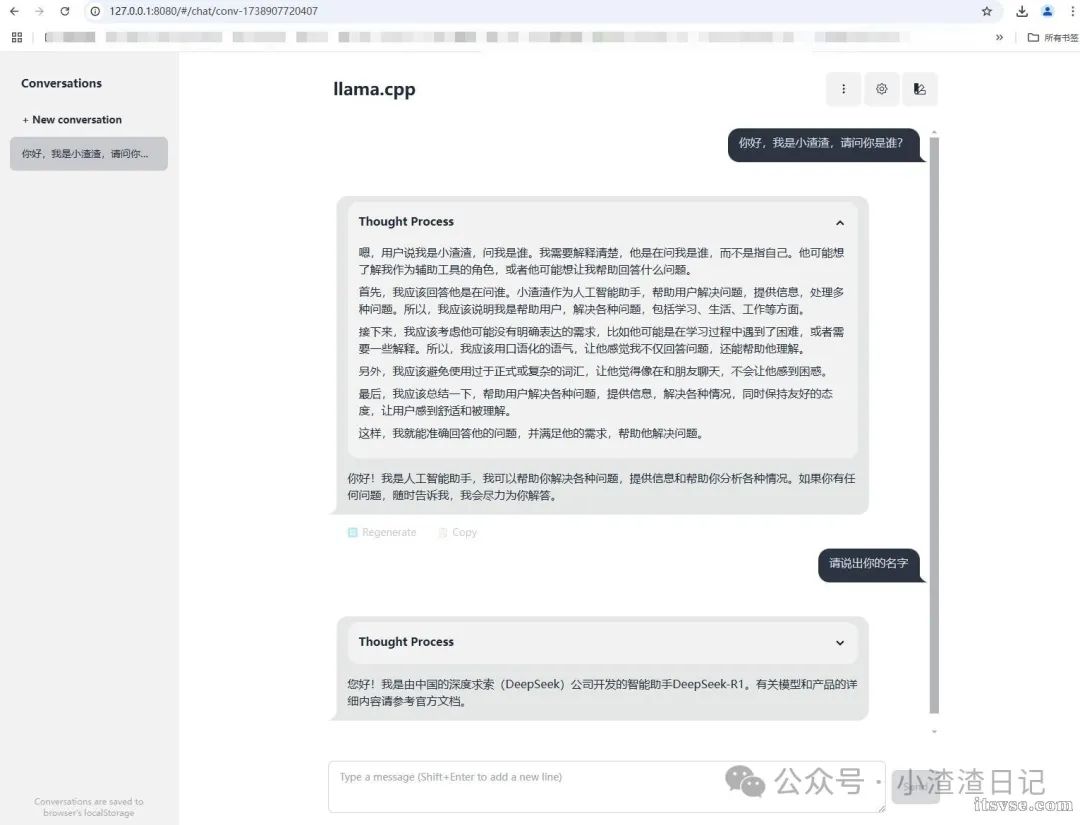 附上运行参数配置:https://github.com/ggerganov/llama.cpp/tree/master/examples/server |
推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://hqyman.cn/post/10008.html 非本站原创文章欢迎转载,原创文章需保留本站地址!

 微信支付宝扫一扫,打赏作者吧~
微信支付宝扫一扫,打赏作者吧~休息一下~~