
一、认识scrapy框架
何为框架,就相当于一个封装了很多功能的结构体,它帮我们把主要的结构给搭建好了,我们只需往骨架里添加内容就行。scrapy框架是一个为了爬取网站数据,提取数据的框架,我们熟知爬虫总共有四大部分,请求、响应、解析、存储,scrapy框架都已经搭建好了。scrapy是基于twisted框架开发而来,twisted是一个流行的事件驱动的python网络框架,scrapy使用了一种非阻塞的代码实现并发的,结构如下:
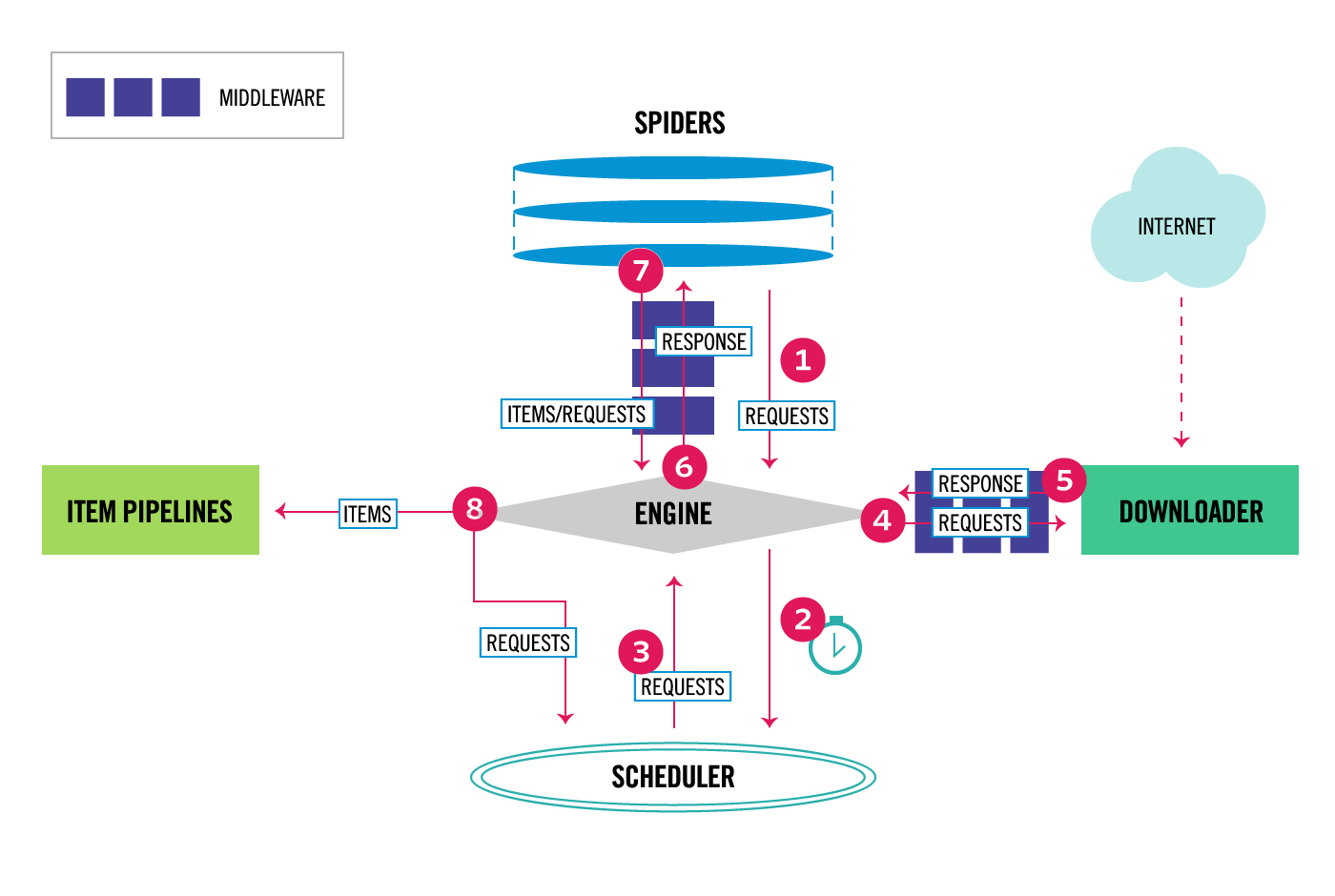

1、引擎(EGINE) 引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件。有关详细信息,请参见上面的数据流部分。2、调度器(SCHEDULER) 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL的优先级队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址3、下载器(DOWLOADER) 用于下载网页内容, 并将网页内容返回给EGINE,下载器是建立在twisted这个高效的异步模型上的4、爬虫(SPIDERS) SPIDERS是开发人员自定义的类,用来解析responses,并且提取items,或者发送新的请求5、项目管道(ITEM PIPLINES) 在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作 下载器中间件(Downloader Middlewares)位于Scrapy引擎和下载器之间,主要用来处理从EGINE传到DOWLOADER的请求request,已经从DOWNLOADER传到EGINE的响应response, 你可用该中间件做以下几件事: (1) process a request just before it is sent to the Downloader (i.e. right before Scrapy sends the request to the website); (2) change received response before passing it to a spider; (3) send a new Request instead of passing received response to a spider; (4) pass response to a spider without fetching a web page; (5) silently drop some requests.6、爬虫中间件(Spider Middlewares) 位于EGINE和SPIDERS之间,主要工作是处理SPIDERS的输入(即responses)和输出(即requests)
1,模块下载
//www.lfd.uci.edu/~gohlke/pythonlibs/17.1
2,开启一个scrapy项目
1,新建一个项目 在pycharm的终端里输入:scrapy startproject 项目名称 构建了一个如下的文件目录: project_name/ scrapy.cfg: project_name/ __init__.py items.py pipelines.py settings.py spiders/ __init__.py scrapy.cfg 项目的主配置信息。(真正爬虫相关的配置信息在settings.py文件中) items.py 设置数据存储模板,用于结构化数据,如:Django的Model pipelines 数据持久化处理 settings.py 配置文件,如:递归的层数、并发数,延迟下载等 spiders 爬虫目录,如:创建文件,编写爬虫解析规则2,新建一个爬虫程序 也是在pycharm的终端下输入:cd 项目名称 #进入项目目录下再输入:scrapy genspider 爬虫程序名称 爬虫程序的起始url 此时就会在第二层的project_name文件夹下创建一个spider文件夹,spider文件夹下就会有一个‘爬虫应用程序名字.py的文件’,如下: project_name: project_name: spider: app_name.py
此时app_name.py:
import scrapyclass QiubaiSpider(scrapy.Spider): name = 'qiubai' #应用名称 #允许爬取的域名(如果遇到非该域名的url则爬取不到数据) allowed_domains = ['https://www.qiushibaike.com/'] #我们一般情况下都会把给注释掉, #起始爬取的url start_urls = ['https://www.qiushibaike.com/'] #访问起始URL并获取结果后的回调函数,该函数的response参数就是向起始的url发送请求后,获取的响应对象.该函数返回值必须为可迭代对象或者NUll def parse(self, response): print(response.text) #获取字符串类型的响应内容 print(response.body)#获取字节类型的相应内容
3,修改settings.py配置文件
修改内容及其结果如下: 19行:USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36' #伪装请求载体身份22行:ROBOTSTXT_OBEY = False #可以忽略或者不遵守robots协议
4,运行爬虫程序
在pycharm终端里输入:scrapy crawl 爬虫程序名称 scrapy crawl 爬虫程序名称 --nolog scrapy.cmdline , , ,]) 从此以后,我们每次只需要运行start文件,就可以让程序跑起来
二、请求、响应、解析
这三个功能的实现主要就是在爬虫程序下,我这里以爬取网易新闻为例子。
1,项目要求
我此次项目的功能是:爬取网易新闻下的国内、国际、军事、航空的的所有新闻。
第一步:

第二步:点击进入四个板块
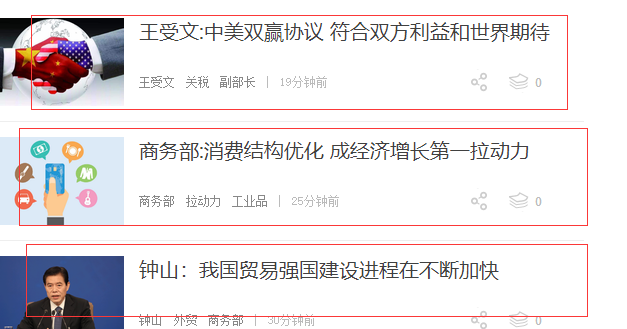
第三步:点击每条新闻,拿到每条新闻的标题,url,图片的url,所属的板块,关键字,内容
2,新建项目
在终端里依次输入: scrapy startproject WY #Demo是我的项目名称cd WY #进入我的项目环境下scrapy genspider wangyi news.163.com #创建我的网易爬虫程序
3,编写wangyi.py代码
= start_urls = [=response.xpath(=[3,4,6,7 i =a_list[i].xpath(=a_list[i].xpath(=scrapy.Request(url=link,callback=self.parse_one=response.xpath( div =div.xpath(=div.xpath(=div.xpath(=div.xpath(= key (key+1) % 2 ==== scrapy.Request(url=url, callback=self.parse_two=response.xpath(= value +=
以上的代码就能拿到想要的数据,但是哈,我在打印每条新闻时,好像并没有数据,这是咋回事呢,仔细检查代码,可以确定是每个板块的请求是发出去了,parse_one也是接收到响应的,但好像响应内容并不全面,于是我猜测应该是页面加载的问题,当我们给每个板块发送请求后,马上拿到的并不是页面的所有内容,有些js代码还没执行。对于这种问题,在我们之前的爬虫过程也遇到了,可以通过selenium模块来解决。
三、selenium模块在scrapy框架的实现
在爬虫过程中,对于动态加载的页面,我们可以使用selenium模块来解决,实例化一个浏览器对象,然后控制浏览器发送请求,等待页面内容加载完毕后,再获取页面信息。
1,selenium模块在scrapy框架中实现原理
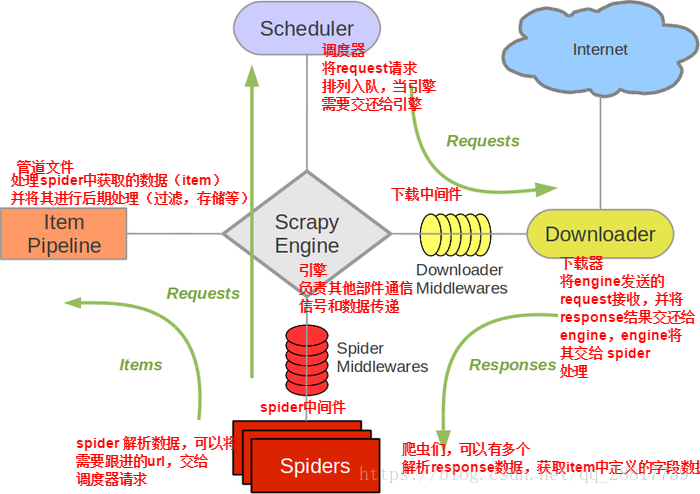
当引擎将国内板块url对应的请求提交给下载器后,下载器进行网页数据的下载,然后将下载到的页面数据,封装到response中,提交给引擎,引擎将response在转交给Spiders。Spiders接受到的response对象中存储的页面数据里是没有动态加载的新闻数据的。要想获取动态加载的新闻数据,则需要在下载中间件中对下载器提交给引擎的response响应对象进行拦截,切对其内部存储的页面数据进行篡改,修改成携带了动态加载出的新闻数据,然后将被篡改的response对象最终交给Spiders进行解析操作
2,selenium的使用流程
重写爬虫文件的构造方法,在该方法中使用selenium实例化一个浏览器对象(因为浏览器对象只需要被实例化一次) 重写爬虫文件的closed(self,spider)方法,在其内部关闭浏览器对象。该方法是在爬虫结束时被调用 重写下载中间件的process_response方法,让该方法对响应对象进行拦截,并篡改response中存储的页面数据 在配置文件中开启下载中间件
3,代码实现
3.1 wangyi.py
selenium
class WangyiSpider(scrapy.Spider):
=webdriver.Chrome(r
3.2 拦截响应,并篡改响应,在中间件中实现,middlewares.py
scrapy.http #这是做了一个要用浏览器对象发送请求的白名单列表 allow_list=[,,, request.url 10= = HtmlResponse(url=request.url,body=res,encoding=,request= response
4,完成setting.py文件的修改
#放开中间件,让中间件生效 DOWNLOADER_MIDDLEWARES =: 543
四、数据存储
1,基于终端指令的持久化存储
保证爬虫文件的parse方法中有可迭代类型对象(通常为列表or字典)的返回,该返回值可以通过终端指令的形式写入指定格式的文件中进行持久化操作 执行输出指定格式进行存储:将爬取到的数据写入不同格式的文件中进行存储 scrapy crawl 爬虫名称 -o xxx.json scrapy crawl 爬虫名称 -o xxx.xml scrapy crawl 爬虫名称 -o xxx.csv
2,基于管道的持久化存储
基于管道的持久化存储,主要依靠scrapy框架的item.py和pipelines.py文件
item.py:数据结构模板文件,定义数据属性
pipelines.py:管道文件,接收数据(item),进行持久化操作
整个流程:
1,爬虫文件爬取到数据后,把数据赋给item对象
2,使用yield关键字将item对象提交给pipelines管道
3,在管道文件中的process_item方法接收item对象,然后把item对象存储
4,在setting中开启管道
2.1 完成item.py文件的书写,也就是定义数据属性
======scrapy.Field() #全部内容 对于本次爬取的网易新闻我只存储这6个信息
2.2 完善wangyi.spider爬虫程序
WY.items selenium =
start_urls = [ =webdriver.Chrome(r=response.xpath(=[3,4,6,7 i =a_list[i].xpath(==a_list[i].xpath(]==scrapy.Request(url=link,callback=self.parse_one,meta={=response.xpath(=response.meta[ div =div.xpath(=div.xpath(=div.xpath(=div.xpath(= key (key+1) % 2 ===]=]=]=]== scrapy.Request(url=url, callback=self.parse_two, meta={=response.meta[=response.xpath(=
value +=]=2.3 pipelines.py文件代码的实现,也就是真正的存储过程
1)存储在文件中
class WyFilePipeline(object): #构造方法
def __init__(self):
self.fp = None #定义一个文件描述符属性 #下列都是在重写父类的方法:
#开始爬虫时,执行一次
def open_spider(self,spider): print('爬虫开始')
self.fp = open('./data.txt', 'w')
#因为该方法会被执行调用多次,所以文件的开启和关闭操作写在了另外两个只会各自执行一次的方法中。
def process_item(self, item, spider): #将爬虫程序提交的item进行持久化存储
self.fp.write(item['author'] + ':' + item['content'] + '\n') return item #结束爬虫时,执行一次
def close_spider(self,spider):
self.fp.close() print('爬虫结束')setting配置
#开启管道
ITEM_PIPELINES = {
'WY.pipelines.WyFilePipeline': 300,
}2)存储在mongodb数据库中
= pymongo.MongoClient(host=, port=27017=
setting配置
#开启管道
ITEM_PIPELINES = {
'WY.pipelines.WyMongodbPipeline': 300,
}3)存储在mysql数据库中
import pymysqlclass WyMysqlPipeline(object):
conn = None #mysql的连接对象声明
cursor = None#mysql游标对象声明
def open_spider(self,spider): print('开始爬虫') #链接数据库
self.conn = pymysql.Connect(host='127.0.0.1',port=3306,user='root',password='123456',db='wangyi') #编写向数据库中存储数据的相关代码
def process_item(self, item, spider): #1.链接数据库
#2.执行sql语句
sql = 'insert into xinwen values("%s","%s")'%(item['genre'],item['url']....)
self.cursor = self.conn.cursor() #执行事务
try:
self.cursor.execute(sql)
self.conn.commit() except Exception as e: print(e)
self.conn.rollback() return item def close_spider(self,spider): print('爬虫结束')
self.cursor.close()
self.conn.close()setting配置
ITEM_PIPELINES = { 'WY.pipelines.WyMysqlPipeline': 300,
}4)存储在redis数据库
import redisclass WyRedisPipeline(object):
conn = None def open_spider(self,spider): print('开始爬虫') #创建链接对象
self.conn = redis.Redis(host='127.0.0.1',port=6379) def process_item(self, item, spider):
dict = { 'genre':item['genre'], 'content':item['content'].......
} #写入redis中
self.conn.lpush('data', dict) return itemsetting配置
ITEM_PIPELINES = { 'WY.pipelines.WyRedisPipeline': 300,
}可以从上面四种存储方式看出,模式都是一样的,主要是你的类名要和你的setting里的要一致
5)可以同时存储在多个里面,以同时存储在文件和mongodb中为例
class WyFilePipeline(object): #构造方法
def __init__(self):
self.fp = None #定义一个文件描述符属性 #下列都是在重写父类的方法:
#开始爬虫时,执行一次
def open_spider(self,spider): print('爬虫开始')
self.fp = open('./data.txt', 'w')
#因为该方法会被执行调用多次,所以文件的开启和关闭操作写在了另外两个只会各自执行一次的方法中。
def process_item(self, item, spider): #将爬虫程序提交的item进行持久化存储
self.fp.write(item['author'] + ':' + item['content'] + '\n') return item #为什么要在这返回item,也就是给下一种存储方法使用
#结束爬虫时,执行一次
def close_spider(self,spider):
self.fp.close() print('爬虫结束')import
setting配置
ITEM_PIPELINES =: 300: 290
五、UA池和IP代理池
我们都知道哈,我们要爬取网页的时候,门户网站会有很多反爬策略,比如检查UA和IP,为了绕过这层反爬,我们可以使用UA池和IP池来解决。改变我们的ua和ip是在发送请求前要做的,而且我们要给每个请求都伪装一下,所以我可以在中间件的process_request方法中添加。利用UA池和IP池就会使得每次请求的UA和ip在很大程度上不一样,就使得被反爬的几率变小
1,UA池
middlewares.py文件中添加一个UA类
scrapy.downloadermiddlewares.useragent = = None
setting配置
DOWNLOADER_MIDDLEWARES =: 543: 542
2,IP代理池
在middlewares.py文件中添加一个IP类
===request.url.split( head == ==] = head + + None
setting配置
DOWNLOADER_MIDDLEWARES = { 'WY.middlewares.WyDownloaderMiddleware': 543, 'WY.middlewares.MyUserAgentMiddleWare': 542, 'WY.middlewares.MyIPMiddleWare': 541,
}六、发送post请求
之前我发送的第一个请求都是写在start_urls列表,让它自动帮我们发送第一个请求,其实我可以手动发送第一个请求。scrapy框架是调用了Spider类下面的一个start_requests方法发送第一个请求,所以我可以重写这个方法,自己手动发送第一个请求,它默认是发送的是get请求,我们可以把它换成post请求。
def start_requests(self): #请求的url
post_url = 'http://fanyi.baidu.com/sug'
# post请求参数
formdata = { 'kw': 'wolf',
} # 发送post请求
yield scrapy.FormRequest(url=post_url, formdata=formdata, callback=self.parse) #在这里我们自己回调了parse函数七、递归解析
1,情况分析
很多情况下,我们爬取的数据不止一个,他们会以索引的方式存在于页末,比如下一页等,但是这些页面数据的结构都是一样的,所以用的解析方式也是一样的。对于这样的爬虫,我们可以使用递归解析完成。
实现流程:
1,访问第一页,拿到响应,交给parse解析出第一页的数据,存储。
2,但第一页中肯定会拿到下一页的链接,我们在parse中对下一页的链接发起请求,然后这次请求的回调函数也是当前所在的parse,在自己函数中调用自己,这就形成了递归,递归函数必须要有一个出口,不然就行成了死循环,我们的出口就是,当下一页的链接不存在时,就不要发送请求了。
2,代码实现
spider程序
Demo1.items = =scrapy.Request(, callback==response.xpath( link =scrapy.Request(url=link,callback==+response.xpath(=scrapy.Request(url=next_page_link,callback==response.xpath(=response.xpath(=.join(response.xpath(=]=]=]= item
八、CrawlSpider
1,简介
Crawlspider其实是Spider的一个子类,除了继承到Spider的特性和功能外,还派生出其他强大的功能,其中最显著的就是‘LinkExtractors链接提取器’。爬取网页上的链接继续发送请求时使用CrawlSpider更合适
2,创建CrawlSpider爬虫程序
1,新建一个项目,这个和spider一样的 scrapy startproject 项目名称2,创建一个CrawlSpider的爬虫程序 scrapy genspider -t crawl 程序名字 url #这个比spider多了-t crawl,表示基于CrawlSpider类的
得到如下的程序:
import scrapyfrom scrapy.linkextractors import LinkExtractorfrom scrapy.spiders import CrawlSpider, Ruleclass ChoutidemoSpider(CrawlSpider):
name = 'choutiDemo'
#allowed_domains = ['www.chouti.com']
start_urls = ['http://www.chouti.com/']
#这是提取规则
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
) def parse_item(self, response):
i = {} #i['domain_id'] = response.xpath('//input[@id="sid"]/@value').extract()
#i['name'] = response.xpath('//div[@id="name"]').extract()
#i['description'] = response.xpath('//div[@id="description"]').extract()
return i
这个程序和spider最大的不同在于,CrawlSpider类多了一个rules属性,作用是定义‘提取动作’,在rules中可以包含一个或多个rule对象,在rule对象中包含了LingkExtractor对象3,LinkExtractor,链接提取器
LinkExtractor( allow=r'Items/',# 满足括号中“正则表达式”的值会被提取,如果为空,则全部匹配。 deny=xxx, # 满足正则表达式的则不会被提取。 restrict_xpaths=xxx, # 满足xpath表达式的值会被提取 restrict_css=xxx, # 满足css表达式的值会被提取 deny_domains=xxx, # 不会被提取的链接的domains。 ) 作用:提取response中符合规则的链接
4,Rule,规则解析器
根据链接提取器中提取到的链接,根据指定规则提取解析器链接网页中的内容。 Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True) 参数介绍: 参数1:指定链接提取器 参数2:指定规则解析器解析数据的规则(回调函数) 参数3:是否将链接提取器继续作用到链接提取器提取出的链接网页中。当callback为None,参数3的默认值为true。
5,爬取的流程
a)爬虫文件首先根据起始url,获取该url的网页内容 b)链接提取器会根据指定提取规则将步骤a中网页内容中的链接进行提取 c)规则解析器会根据指定解析规则将链接提取器中提取到的链接中的网页内容根据指定的规则进行解析 d)将解析数据封装到item中,然后提交给管道进行持久化存储
6,实例
import scrapyfrom scrapy.linkextractors import LinkExtractorfrom scrapy.spiders import CrawlSpider, Ruleclass CrawldemoSpider(CrawlSpider): name = 'qiubai' #allowed_domains = ['www.qiushibaike.com'] start_urls = ['https://www.qiushibaike.com/pic/'] #连接提取器:会去起始url响应回来的页面中提取指定的url link = LinkExtractor(allow=r'/pic/page/\d+\?') #s=为随机数 link1 = LinkExtractor(allow=r'/pic/$')#爬取第一页 #rules元组中存放的是不同的规则解析器(封装好了某种解析规则) rules = ( #规则解析器:可以将连接提取器提取到的所有连接表示的页面进行指定规则(回调函数)的解析 Rule(link, callback='parse_item', follow=True), Rule(link1, callback='parse_item', follow=True), ) #这里拿到的就是提取出来的链接请求返回的响应体 def parse_item(self, response): print(response)
推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://hqyman.cn/post/10876.html 非本站原创文章欢迎转载,原创文章需保留本站地址!

 微信支付宝扫一扫,打赏作者吧~
微信支付宝扫一扫,打赏作者吧~休息一下~~