
1.爬虫的基本概念
爬虫:自动获取网站数据的程序,关键是批量的获取
反爬虫:使用技术手段防止爬虫程序的方法
误伤:反爬技术将普通用户识别为爬虫,如果误伤过高,效果再好也不能用
成本:反爬虫需要的人力和机器成本
拦截:成功拦截爬虫,一般拦截率越高,误伤率越高
2.反爬虫的目的
初级爬虫:简单粗暴,不管服务器压力,容易弄挂网站
数据保护:具有知识产权的数据
失控的爬虫:由于某些情况下,忘记或者无法关闭的爬虫
商业竞争对手:防止被对手爬走了数据
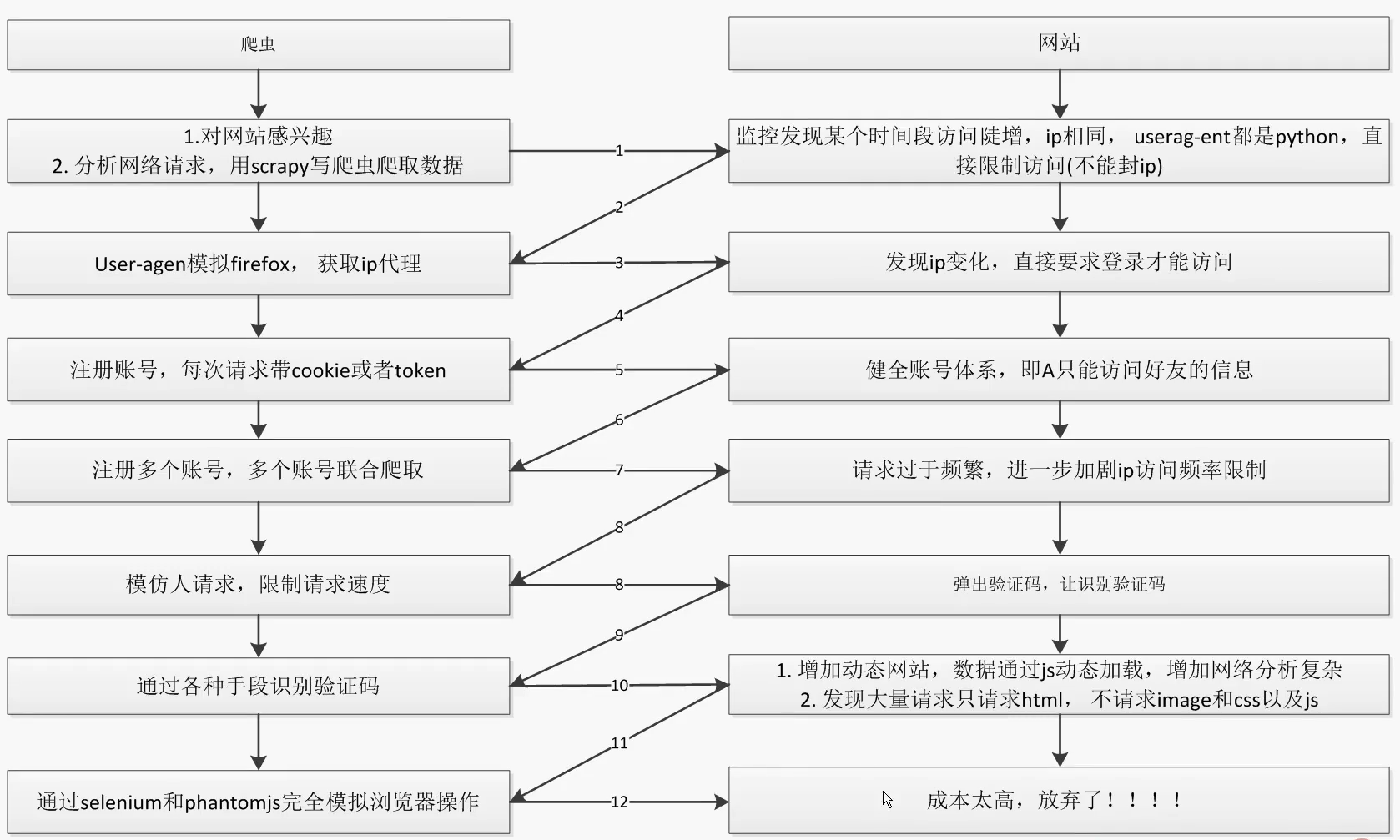
3.爬虫和反爬虫的经典应对场景(重点)
4.随机更换User-Agent
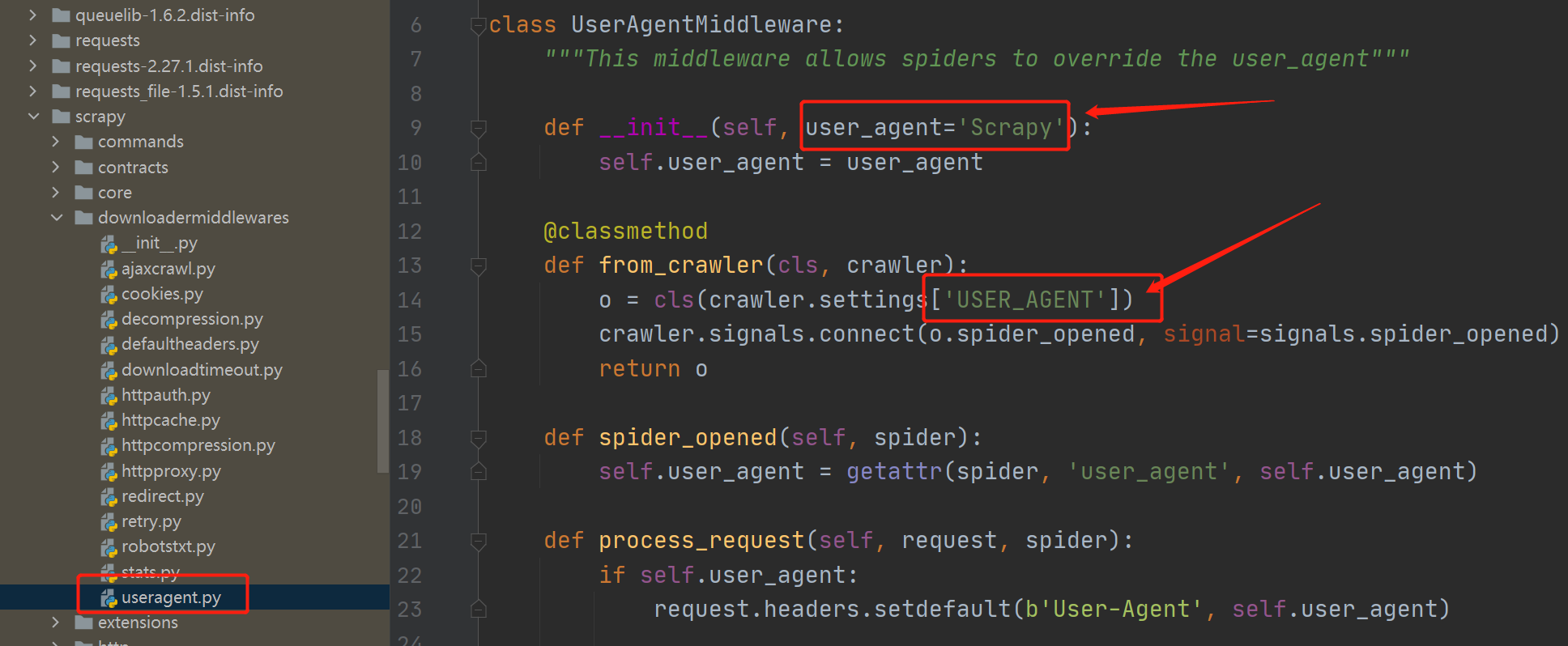
通过之前的执行流程图可以看到,Requests和Response之间有很多的Middleware,这个UserAgentMiddleware就是默认用来处理User-Agent的。
从源码可以看到,如果不在settings文件中定义USER_AGENT,那么就会使用默认的"Scrapy"
4.1 全局User-Agent
如果要定义全局默认的User-Agent,可以在settings.py文件中去定义
# 定义全局的User-Agent USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36"
4.2 局部User-Agent
局部user-agent是在我们自己写的spider代码里面定义的,可以通过custom_settings来定义
custom_settings = {
# 是否开启自定义cookie,如果为False则使用settings中的cookie
"COOKIES_ENABLED": True,
# 下载延迟时间,值越大请求越慢
"DOWNLOAD_DELAY": 10,
# 是否开启随机延迟时间
"RANDOMIZE_DOWNLOAD_DELAY": True,
# 并发请求数
"CONCURRENT_REQUESTS": 1,
# 浏览器的user-agent(注意这里的名字是USER_AGENT)
"USER_AGENT": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.4951.54 Safari/537.36",
}4.3 fake-useragent(重点)
官方地址:https://github.com/hellysmile/fake-useragent
默认维护的User-Agent的链接:https://fake-useragent.herokuapp.com/browsers/0.1.11(后面是最新版本号)
4.3.1 安装模块
pip install fake-useragent
4.3.2 Middleware编写
from fake_useragent import UserAgent # 随机更换User-Agent class RandomUserAgentMiddleware(object): def __init__(self, crawler): super(RandomUserAgentMiddleware, self).__init__() self.ua = UserAgent() @classmethod def from_crawler(cls, crawler): return cls(crawler) def process_request(self, request, spider): request.headers.setdefault(b'User-Agent', self.ua.random)
4.3.3 settings配置
DOWNLOADER_MIDDLEWARES = {
# 'article_spider.middlewares.ArticleSpiderDownloaderMiddleware': 543,
# 注释掉默认的useragent的中间件
# 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
# 自定义useragent的中间件
'article_spider.middlewares.RandomUserAgentMiddleware': 1
}4.3.4 如何自定义生成的策略?
fake-useragent默认支持很多种的user-agent的生成方式,有如下类型:ua.ie、ua.opera、ua.chrome等
我们有的时候就想只生产chrome的user-agent,那如何动态切换配置了?
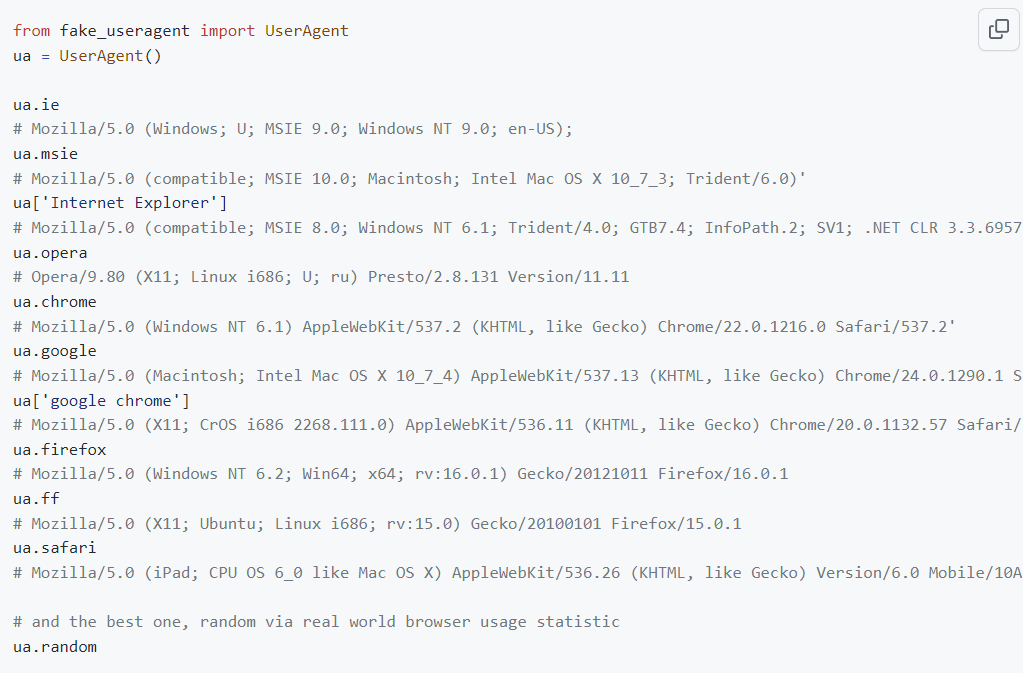
动态切换user-agent的生成策略
通过self.ua_type = crawler.settings.get("RANDOM_UA_TYPE", "random"),可以读取配置文件的数据
通过get_ua()函数可以动态调用对应的方法,相当于:self.ua.self.ua_type,但是python语法是不支持这样调用的。所以我们通过get_ua()这个内部函数来实现
from fake_useragent import UserAgent
# 随机更换User-Agent
class RandomUserAgentMiddleware(object):
def __init__(self, crawler):
super(RandomUserAgentMiddleware, self).__init__()
self.ua = UserAgent()
self.ua_type = crawler.settings.get("RANDOM_UA_TYPE", "random")
@classmethod
def from_crawler(cls, crawler):
return cls(crawler)
def process_request(self, request, spider):
# 动态获得配置的策略
def get_ua():
return getattr(self.ua, self.ua_type)
request.headers.setdefault(b'User-Agent', get_ua())RANDOM_UA_TYPE这个是自定义配置,默认为random
以后如果想改成chrome或其他的,只需要更改settings中的这个配置即可
DOWNLOADER_MIDDLEWARES = {
# 'article_spider.middlewares.ArticleSpiderDownloaderMiddleware': 543,
# 注释掉默认的useragent的中间件
# 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
# 自定义useragent的中间件
'article_spider.middlewares.RandomUserAgentMiddleware': 1
}
# 随机user-agent的策略
RANDOM_UA_TYPE = "random"5.IP代理池
有些网站会限制同一个IP频繁爬取网站,这个时候就需要用到IP代理池了。
IP代理推荐:https://zhuanlan.zhihu.com/p/33576641
5.1 爬取代理IP
5.2 实现随机取代理IP
5.2.1 数据库设计
CREATE TABLE `proxy_ip` ( `ip` varchar(255) NOT NULL, `port` varchar(255) NOT NULL, `speed` float DEFAULT NULL, `proxy_type` varchar(5) DEFAULT NULL, PRIMARY KEY (`ip`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
5.2.2 代码
# mysql高效的取随机数据 SELECT * FROM `table` AS t1 JOIN (SELECT ROUND(RAND() * ((SELECT MAX(id) FROM `table`)-(SELECT MIN(id) FROM `table`))+(SELECT MIN(id) FROM `table`)) AS id) AS t2 WHERE t1.id >= t2.id ORDER BY t1.id LIMIT 1;
class ProxyIP(object):
# 随机提取IP
def get_random_ip(self):
random_ip_sql = """
select ip, port from proxy_ip
order by RAND()
limit 1
"""
cursor.execute(random_ip_sql)
for ip_info in cursor.fetchall():
ip = ip_info[0]
port = ip_info[1]
# 判断ip是否可用
if self.judge_ip(ip, port):
return "http://{0}:{1}".format(ip, port)
else:
# 如果不可用,继续查找可用IP
self.get_random_ip()
# 判断ip是否可用
def judge_ip(self, ip, port):
http_url = "http://www.baidu.com"
proxy_url = "http://{0}:{1}".format(ip, port)
proxy_dict = {
"http": proxy_url,
# "https": proxy_url,
}
try:
resp = requests.get(http_url, proxies=proxy_dict)
code = resp.status_code
if 200 <= code < 300:
print("effective ip")
return True
else:
# 如果ip不可用,删除ip
print("invalid ip and port")
self.delete_ip(ip)
return False
except Exception as e:
print("invalid ip and port")
print(e)
self.delete_ip(ip)
return False
# 删除IP
def delete_ip(self, ip):
delete_ip_sql = """
delete from proxy_ip where ip = '{0}'
""".format(ip)
cursor.execute(delete_ip_sql)
conn.commit()
return True
if __name__ == '__main__':
proxy_ip = ProxyIP()
print(proxy_ip.get_random_ip())5.2.3 Middleware中间件
from article_spider.tools.proxy_ip import ProxyIP # 随机获取代理IP # github上有scrapy-proxies,提供了很多配置功能,可以自己改造一下 # github上有scrapy-crawlera,这个是收费的 # python使用Tor(洋葱浏览器)爬取网站 class RandomIPMiddleware(object): def process_request(self, request, spider): proxy_ip = ProxyIP() request.meta["proxy"] = proxy_ip.get_random_ip()
5.2.4 settings配置
DOWNLOADER_MIDDLEWARES = {
# 自定义useragent的中间件
'article_spider.middlewares.RandomUserAgentMiddleware': 1,
# 随机IP代理
'article_spider.middlewares.RandomIPMiddleware': 2
}5.3 总结
我们在爬取网站的时候,总体还是要采用后面讲的限速的策略,不要爬的太快了,一定要珍惜自己的IP!
如果你想爬的更快的话,可以使用IP代理池进行爬取
5.4 其他好用的IP代理的实现
上面的代理IP都是爬取的免费的,免费的一般都不稳定,可以考虑一些付费的IP代理
5.4.1 scrapy-proxies
这个都是在settings文件中进行配置的,不支持数据库操作,所以可以自己对源码改一下。
官方地址:https://github.com/aivarsk/scrapy-proxies
5.4.2 scrapy-crawlera(收费)
这个是代理IP商提供的开源代码,但是使用他们的代理IP是收费的
官方地址:https://github.com/scrapy-plugins/scrapy-zyte-smartproxy
官方文档:https://scrapy-zyte-smartproxy.readthedocs.io/en/latest/
5.4.2 Tor(洋葱浏览器)爬取网站
洋葱浏览器可以使用代理隐藏自己的真实IP地址,常用于黑客使用,我们的python也可以操作Tor来爬取网站
文章:https://copyfuture.com/blogs-details/2020051818370565011ksvjjtfy8inp9
6.验证码识别
6.1 编码实现(tesseract-ocr)
这个识别准确度比较低,不太推荐使用
还可以使用之前我们写的opencv识别工具类:https://www.yuque.com/suifengbiji/kzz2hu/lufd1y#MKjYY
6.2 在线打码(推荐)
超级鹰:超级鹰验证码识别-专业的验证码云端识别服务,让验证码识别更快速、更准确、更强大
6.2.1 超级鹰打码平台代码
1)工具类
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files,
headers=self.headers)
return r.json()
def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
if __name__ == '__main__':
# 用户中心>>软件ID 生成一个替换 96001
chaojiying = Chaojiying_Client('13279385584', 'ky6856', '930856')
# 本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
im = open('a.jpg', 'rb').read()
# 1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()
print(chaojiying.PostPic(im, 1902))2)识别超级鹰自己的登录验证码
from selenium.webdriver import Chrome
from selenium.webdriver.common.by import By
import time
from chaojiying import Chaojiying_Client
web = Chrome()
web.get("http://www.chaojiying.com/user/login/")
# 截取验证码图片,自动获得图片的二进制
img = web.find_element(By.XPATH, "/html/body/div[3]/div/div[3]/div[1]/form/div/img").screenshot_as_png
# 识别验证码
chaojiying = Chaojiying_Client('13279385584', 'ky6856', '930856')
dic = chaojiying.PostPic(img, 1902)
verify_code = dic.get("pic_str")
# 填写用户名
web.find_element(By.XPATH, "/html/body/div[3]/div/div[3]/div[1]/form/p[1]/input").send_keys("13279385584")
# 填写密码
web.find_element(By.XPATH, "/html/body/div[3]/div/div[3]/div[1]/form/p[2]/input").send_keys("ky6856")
# 填写验证码
web.find_element(By.XPATH, "/html/body/div[3]/div/div[3]/div[1]/form/p[3]/input").send_keys(verify_code)
time.sleep(5)
# 点击登陆
web.find_element(By.XPATH, "/html/body/div[3]/div/div[3]/div[1]/form/p[4]/input").click()6.3 人工代码
后面是真人在给你识别,价格最贵,但是识别率肯定是最高的
7.禁用Cookie
将Cookie禁掉,就不会在Requests中携带cookie了,那网站就无法跟踪,适用于不需要登录的网站。
我们可以在scrapy中的settings.py文件中做全局配置
# Disable cookies (enabled by default) COOKIES_ENABLED = False
也可以在我们具体的spider代码中做自定义配置custom_settings
class ZhihuSpider(scrapy.Spider):
name = 'zhihu'
allowed_domains = ['www.zhihu.com']
start_urls = ['http://www.zhihu.com/']
# 禁用Cookie
custom_settings = {
"COOKIES_ENABLED": False
}
}8.限制爬取速度
中文文档:AutoThrottle 扩展 — Scrapy 2.5.0 文档
官方文档:AutoThrottle extension — Scrapy 2.11.2 documentation
主要是通过这个AutoThrottle扩展来实现限制速度,可以在settings文件中配置
也可以在spider代码中自定义配置custom_settings
8.1 介绍
# Enable and configure the AutoThrottle extension (disabled by default) # See https://docs.scrapy.org/en/latest/topics/autothrottle.html AUTOTHROTTLE_ENABLED = True # The initial download delay AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies AUTOTHROTTLE_MAX_DELAY = 60 # The average number of requests Scrapy should be sending in parallel to # each remote server AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: AUTOTHROTTLE_DEBUG = False
# Configure a delay for requests for the same website (default: 0) # See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay # 下载延迟时间,每隔3秒下载一个网页 DOWNLOAD_DELAY = 3 # The download delay setting will honor only one of: CONCURRENT_REQUESTS_PER_DOMAIN = 16 CONCURRENT_REQUESTS_PER_IP = 16
8.2 代码
cookie_list = "111111"
custom_settings = {
# 是否开启自定义cookie,如果为False则使用settings中的cookie
"COOKIES_ENABLED": True,
# 下载延迟时间,值越大请求越慢
"DOWNLOAD_DELAY": 10,
# 是否开启随机延迟时间
"RANDOMIZE_DOWNLOAD_DELAY": True,
# 并发请求数
"CONCURRENT_REQUESTS": 1,
# 浏览器的user-agent(注意这里的名字是USER_AGENT)
"USER_AGENT": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.4951.54 Safari/537.36",
# 默认的请求头
'DEFAULT_REQUEST_HEADERS': {
'Accept': 'application/json, text/javascript, */*; q=0.01',推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://hqyman.cn/post/10878.html 非本站原创文章欢迎转载,原创文章需保留本站地址!

 微信支付宝扫一扫,打赏作者吧~
微信支付宝扫一扫,打赏作者吧~休息一下~~