
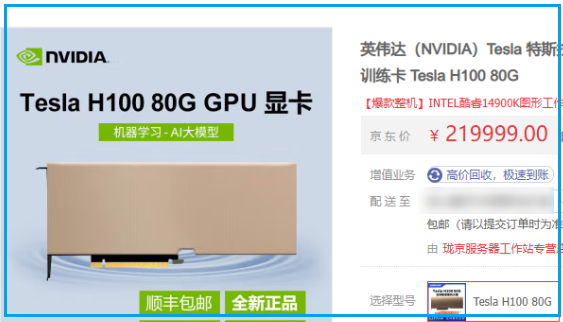
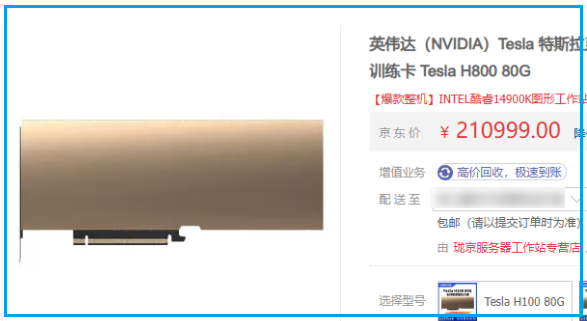
安装必要的库,如 Hugging Face Transformers 和 PyTorch。用于微调的服务器需要有GPU。国内能买到的GPU有 Tesla H100、H800、V100s
GPU 价格会出现波动,最高会打对折。比如 Tesla V100s(32G显存)高位时要¥70000,当前价格为 ¥36999

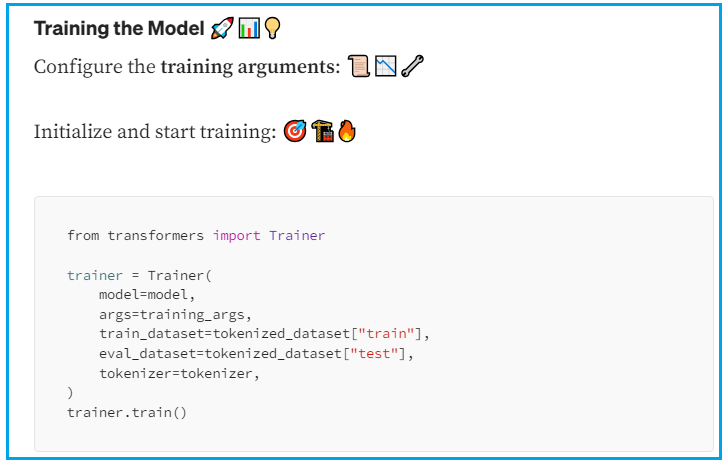
使用 Hugging Face Transformers 库加载预训练模型,通过 Trainer API 或自定义脚本在您的数据集上微调。使用 LoRA 参数高效微调技术可以显著降低计算成本。
将数据集分为训练和验证集,评估微调模型的性能,必要时调整参数。满意后,可部署模型用于实际应用。
DeepSeek 的模型因其高效性和低成本训练而闻名。例如,DeepSeek-V3 总参数为 671B,其中每个 token 激活 37B 参数,训练成本显著低于竞争对手,如 OpenAI 的 GPT-4。DeepSeek-R1 则在推理任务(如数学、编码和逻辑)上表现出色,与 OpenAI 的 o1 模型相当,且开源特性使其易于访问。
https://huggingface.co/deepseek-ai/DeepSeek-R1

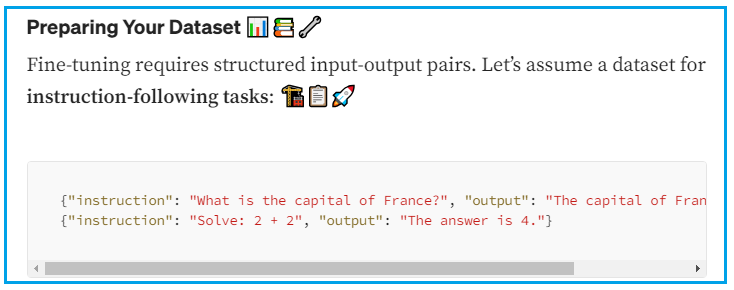
收集相关数据:从公开数据集或自建数据中获取
数据清洗:移除无关或格式错误的条目
数据分割:通常将数据分为训练集和验证集,用于训练和评估
在 linux 系统上安装工具链依赖和GPU驱动
Hugging Face Transformers: 用于加载和微调模型
PyTorch: 深度学习框架
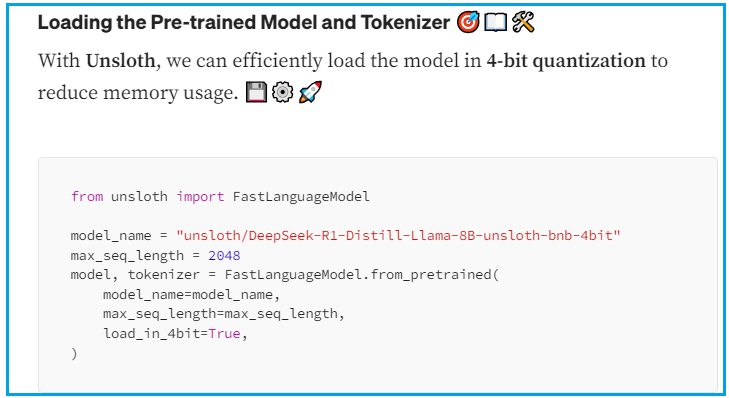
其他工具:如 Unsloth,用于优化微调,降低内存使用
from transformers import AutoModelForCausalLM, AutoTokenizermodel = AutoModelForCausalLM.from_pretrained("deepseek-ai/DeepSeek-V3")https://github.com/deepseek-ai/DeepSeek-Coder/blob/main/finetune/finetune_deepseekcoder.py
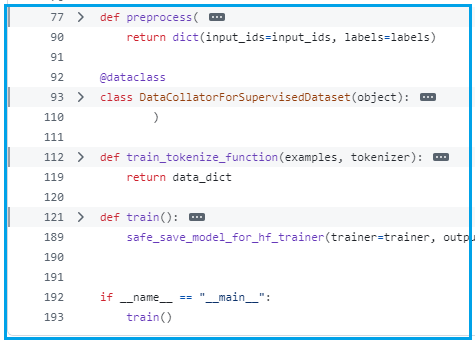
参数高效微调:考虑使用 LoRA(低秩适应)技术,减少计算需求。例如,Unsloth 提供优化,支持在消费级 GPU 上微调,相关教程见
https://medium.com/@pankaj_pandey/fine-tuning-deepseek-r1-on-consumer-hardware-a-step-by-step-guide-dab90bf69e38

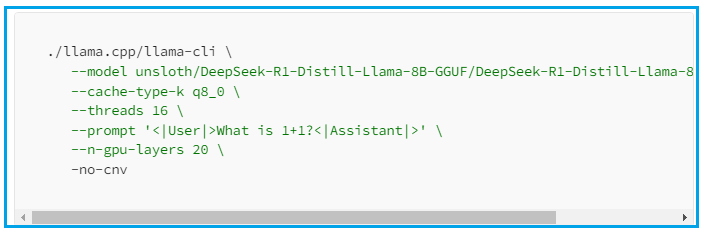
# Install vLLM from pip:pip install vllm# Load and run the model:vllm serve "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B"# Call the server using curl:curl -X POST "http://localhost:8000/v1/chat/completions" \ -H "Content-Type: application/json" \ --data '{ "model": "deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B", "messages": [ { "role": "user", "content": "What is the capital of France?" } ] }'
推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://hqyman.cn/post/9165.html 非本站原创文章欢迎转载,原创文章需保留本站地址!

 微信支付宝扫一扫,打赏作者吧~
微信支付宝扫一扫,打赏作者吧~休息一下~~