

DeepSeek从春节一直火到现在,我除了看各种报道资料向大家学习之外,也一直考虑着能拿手头什么样的硬件配置玩一下:)
今天我要分享的结论很简单。当然除了下表之外,还想补充点经验给大家参考——包括我自己的,也包括来自同行友人的。
测试模型 | DeepSeek-R1-UD-IQ1_S(671B,Dynamic 1.58-bit) | |
OS | Ubuntu 24.01 LTS | |
CPU | AMD EPYC 8534P(64核,SP6,Zen4c) | |
内存 | 6通道192GB DDR5-4800 | 4通道256GB |
Token/s (输出超过1000) | ≈5.47 | ≈4 |
我只使用CPU+6通道DDR5内存(无GPU),DeepSeek-R1-UD-IQ1_S跑到了5.47 Token/s。测试硬件平台,与《一次无需调优的测试:SMT多线程对存储服务器IOPS的贡献》基本相同。我主要是验证了一点,大模型Decode输出的性能与内存或显存带宽直接相关。
建议:
1、在以上测试中,我发现Ubuntu Linux下Ollama有时不够稳定?后来改用llama.cpp效果还好,包括从SSD加载模型都更快。尽管核心也是基于llama.cpp,但Ollama也有不少优点,特别是与前端软件对接的生态方面。
2、用纯CPU来跑DeepSeek,建议每个核心只用单线程——也就是64核跑64线程就好;如果跑128线程(即SMT用满)还会稍慢点。另外根据LLM大模型的特点,AMD的NPS设置建议设置为1(单CPU)或0(双CPU),即禁用NUMA内存亲和。
扩展阅读:《AMD EPYC 9005服务器BIOS & 工作负载调优指南》

这个1.58B量化的671B模型,文件大小只有131GB,所以比较节省内存。
注:当前我只在CPU上跑了DeepSeek-R1-UD-IQ1_S这个1.58bit量化的671B全量模型,主要是节省内存。我甚至看到网上有人说拿128G内存+4090 24G显卡跑的?如果内存够多的话,也可以试着跑下KTransformers那样的CPU+GPU混合推理方案。
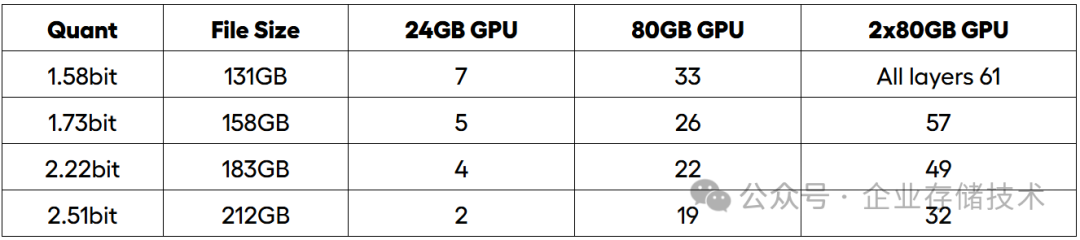
如果您只有1块GPU并且显存容量不够,比如24GB的也可以把1.58bit量化模型当中的7层跑在GPU上,余下用CPU来跑。而达到2块80GB的GPU卡就能承担模型的全部61层了。
测试记录
https://huggingface.co/unsloth/DeepSeek-R1-GGUF 我是从这里下载的测试模型,也参考了里面的部署说明。
 已关注 关注
已关注 关注 上面这段视频,是在4通道内存配置时运行的。在我提问后DeepSeek会先显示“思考过程”,然后给出下面的输出:

在输出较短的Token时,速度比我在本文开头列出的还会高一点。
这一段在字符界面的输出,就是6通道内存的配置了。
更多分享

上面这位朋友用了最新的Turin CPU,12通道内存并且容量更大,所以可以跑4bit量化的DeepSeek R1 671B。性能自然也比我前面的更快:

如上图,这个纯CPU跑的DeepSeek R1Q4_K全量模型达到了9.27 Token/s。至于72B以及更小参数的模型,我建议还是用GPU性价比高些。
去年我还曾关注过AI PC领域,当时做过一期视频节目介绍Ollama + Chatbox,不知是不是有点长所以看的人不多。Ollama的流行度自不必说,而当时关注到Chatbox这个中文UI的人应该还不多吧。
而在今天,DeepSeek让全民都来关注AI,动手本地部署大模型的人也多了不少。
推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://hqyman.cn/post/9164.html 非本站原创文章欢迎转载,原创文章需保留本站地址!

 微信支付宝扫一扫,打赏作者吧~
微信支付宝扫一扫,打赏作者吧~休息一下~~