
生产环境如何部署deepseek,什么样的配置能生产可用,今天我用双4090,测试几个模型。大家看看。 非常感谢提供环境的朋友。
vLLM 简单介绍
vLLM 是一个快速且易于使用的 LLM 推理和服务库。
vLLM(Very Large Language Model Serving)是由加州大学伯克利分校团队开发的高性能、低延迟的大语言模型(LLM)推理和服务框架。它专为大规模生产级部署设计,尤其擅长处理超长上下文(如8k+ tokens)和高并发请求,同时显著优化显存利用率,是当前开源社区中吞吐量最高的LLM推理引擎之一。
高吞吐量:采用先进的服务器吞吐量技术。 内存管理:通过PagedAttention高效管理注意力键和值内存。 请求批处理:支持连续批处理传入请求。 模型执行:利用CUDA/HIP图实现快速模型执行。 量化技术:支持GPTQ、AWQ、INT4、INT8和FP8量化。 优化内核:包括与FlashAttention和FlashInfer的集成。 其他特性:支持推测解码、分块预填充。
vLLM 文档:https://docs.vllm.ai/en/latest/index.html
源码地址:https://github.com/vllm-project/vllm
性能测试:https://blog.vllm.ai/2024/09/05/perf-update.html
软硬件信息
我的环境是双4090,内存是192GB。我预想的8k上下文。最好16k。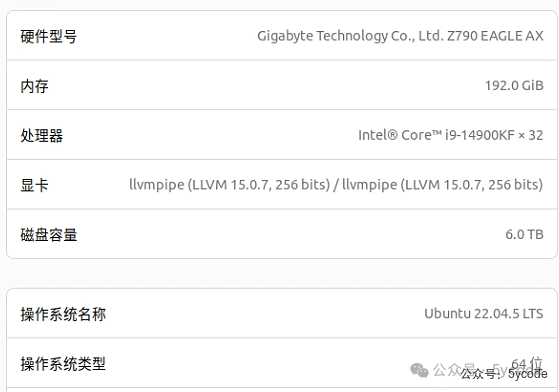
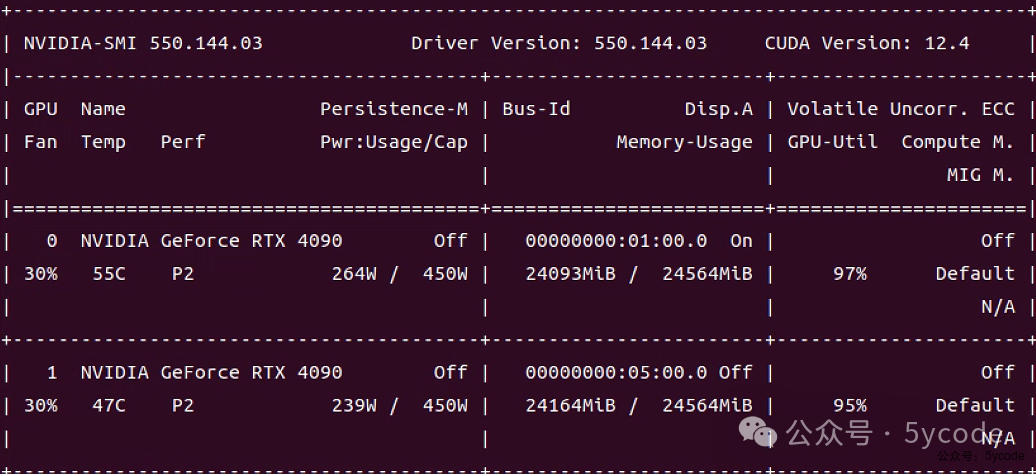
CUDA信息
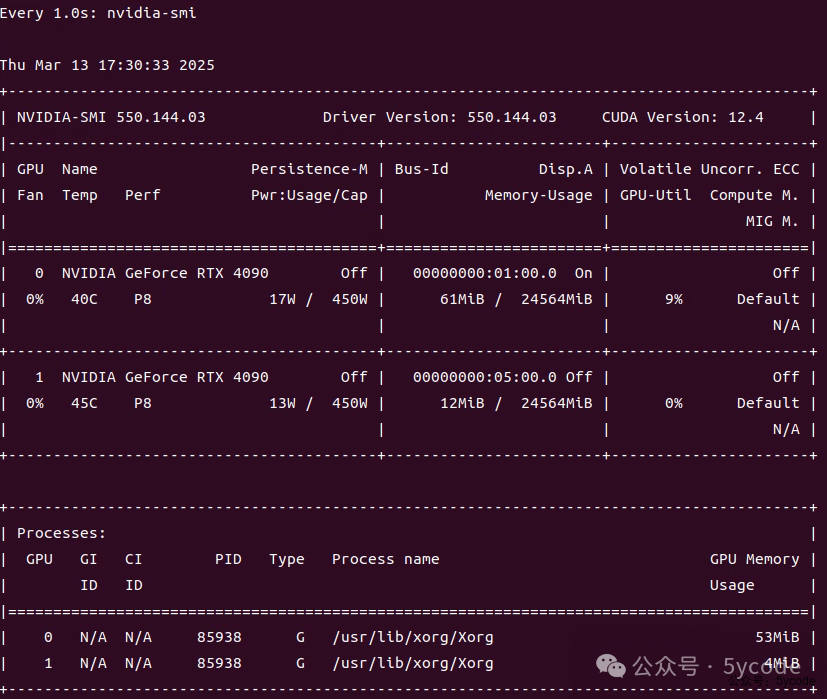
Driver Version: 550.144.03
CUDA Version: 12.4
环境安装
#下载 miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh && chmod +x Miniconda3-latest-Linux-x86_64.sh
# 安装
sh Miniconda3-latest-Linux-x86_64.sh
# 添加国内镜像
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
#创建vllm环境
conda create -n vllm python=3.12 -y
#激活环境,注意,切换窗口一定要执行该命令
conda activate vllm
#设置国内镜像源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple/
#安装vllm和 modelscope
pip install vllm modelscope
#根据自己的cuda版本安装,具体适配哪个,可以问下kimi或deepseek,使用下面的方法比较慢,不推荐
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu124
# 设置镜像(推荐)
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/linux-64/
conda install pytorch torchvision torchaudio pytorch-cuda=12.4
#安装基准测试依赖包
pip install pandas datasets transformers
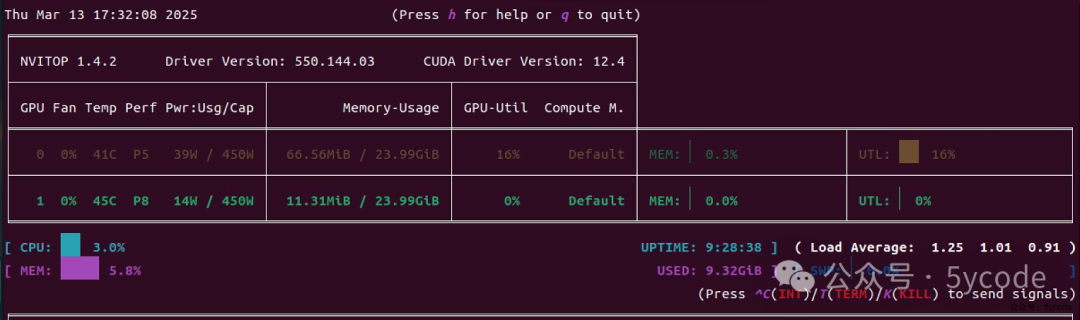
监控工具
pip install nvitop
# 查看
nvitop
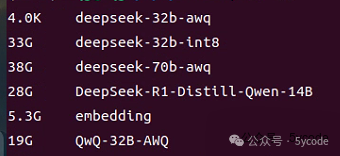
模型选择
我以8k上下文为要求,让deepseek给我推荐测试模型的大小。
| 16bit | ||||
| 8bit | ||||
| 4bit |
基准测试
参考: https://modelscope.cn/docs/models/download
# 创建模型目录
mkdir -p /opt/models
# 官方基准测试代码
git clone https://github.com/vllm-project/vllm.git
cd vllm/benchmarks
基准测试指标含义
| Avg prompt throughput | 输入吞吐量 |
| Avg generation throughput | 生成吞吐量 |
| Running | 正在处理的请求数 |
| Swapped | 被换出的请求数 |
| Pending | 等待中的请求数 |
| GPU KV cache usage | GPU KV Cache 使用率 |
DeepSeek-R1-Distill-Qwen-14B
modelscope download --model 'deepseek-ai/DeepSeek-R1-Distill-Qwen-14B' --local_dir '/opt/models/DeepSeek-R1-Distill-Qwen-14B'
基准测试代码
CUDA_VISIBLE_DEVICES=0,1 python benchmark_throughput.py \
--model "/opt/models/DeepSeek-R1-Distill-Qwen-14B" \
--backend vllm \
--input-len 2048 \
--output-len 10000 \
--num-prompts 50 \
--seed 1100 \
--dtype float16 \ -- 半精度
--tensor-parallel-size 2 \ -- 双cpu
--gpu-memory-utilization 0.95 \
--max-model-len 60000 --长上下文
刚开始600多tokens/s,并行能达到20多个
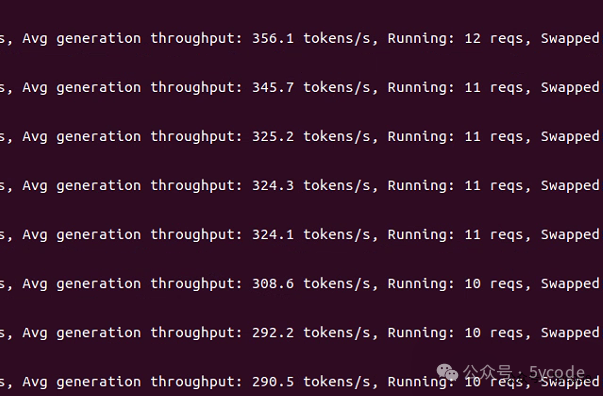 几分钟以后,降到了290tokens/s,并发降到10多个
几分钟以后,降到了290tokens/s,并发降到10多个
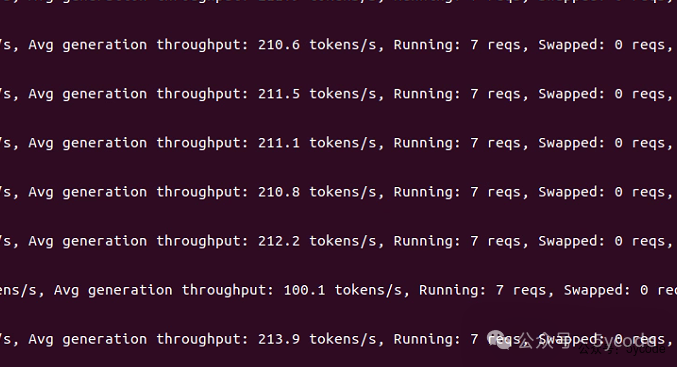 最后降到了200tokens 左右,并发稳定到7个。
最后降到了200tokens 左右,并发稳定到7个。
Qwen/QwQ-32B
modelscope download --model 'Qwen/QwQ-32B' --local_dir '/opt/models/QwQ-32B'
CUDA_VISIBLE_DEVICES=0,1 python benchmark_throughput.py \
--model "/opt/models/QwQ-32B" \
--backend vllm \
--input-len 1024 \
--output-len 3000 \
--num-prompts 50 \
--seed 1100 \
--dtype float16 \
--tensor-parallel-size 2 \
--gpu-memory-utilization 0.95 \
--max-model-len 4096

直接内存溢出,加载不上。
Valdemardi/DeepSeek-R1-Distill-Llama-70B-AWQ
modelscope download --model 'Valdemardi/DeepSeek-R1-Distill-Llama-70B-AWQ' --local_dir '/opt/models/deepseek-70b-awq'
基准测试脚本
CUDA_VISIBLE_DEVICES=0,1 python benchmark_throughput.py \
--model "/opt/models/deepseek-70b-awq" \
--backend vllm \
--input-len 1024 \
--output-len 4096 \
--num-prompts 50 \
--seed 1100 \
--dtype float16 \
--tensor-parallel-size 2 \
--gpu-memory-utilization 0.95 \
--max-model-len 5200
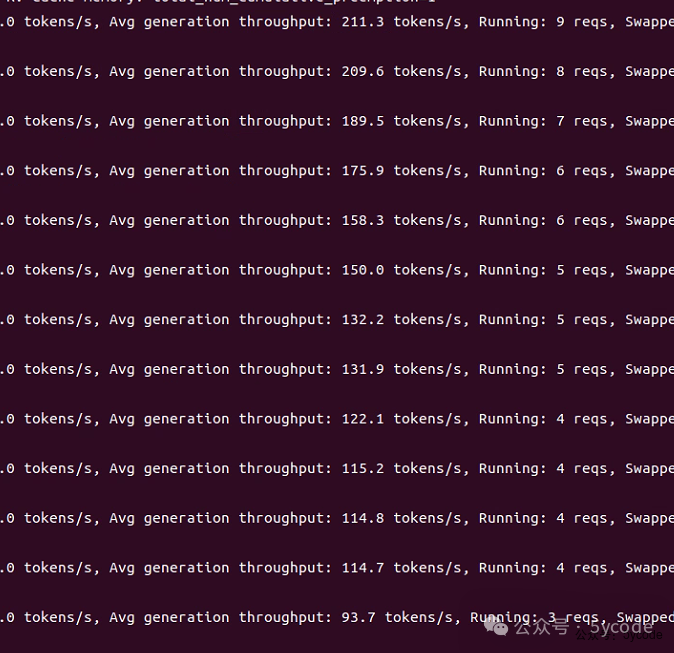 压测刚开始,还好一些,能达到6~9个并发,随着时间的挪移,逐步稳定到2个并发。
压测刚开始,还好一些,能达到6~9个并发,随着时间的挪移,逐步稳定到2个并发。
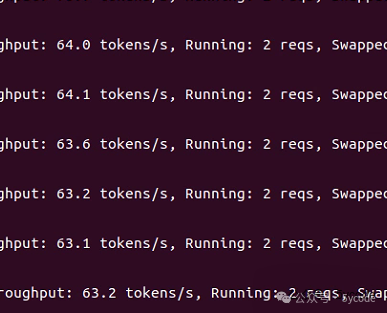
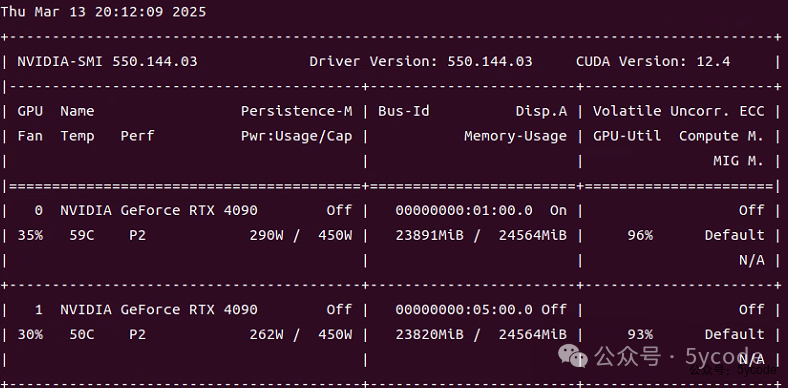
利用内存,开启长上下文
deepseek推荐的两个参数.
| --cpu-offload-gb | 模型参数过大 | ||
| --swap-space | 长序列生成 |
CUDA_VISIBLE_DEVICES=0,1 python benchmark_throughput.py \
--model "/opt/models/deepseek-70b-awq" \
--backend vllm \
--input-len 4096 \
--output-len 10000 \
--num-prompts 50 \
--seed 1100 \
--dtype float16 \
--tensor-parallel-size 2 \
--gpu-memory-utilization 0.95 \
--max-model-len 16384 \
--swap-space 40
 在启动的过程中,一直报超过了10256,我以为这个参数可以直接通过CPU增加GPU的内存。
在启动的过程中,一直报超过了10256,我以为这个参数可以直接通过CPU增加GPU的内存。
然后在官方的ai上问了下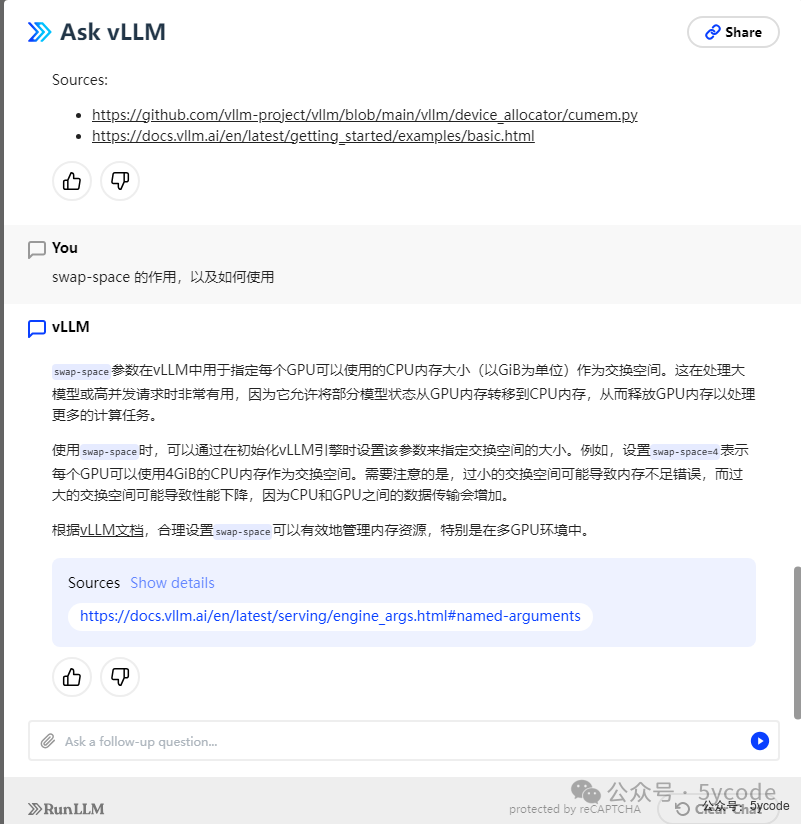
看这个意思,在并发的时候,才会利用,启动的时候,并不会利用。
然后我就又问下了,该如何配置启动参数。
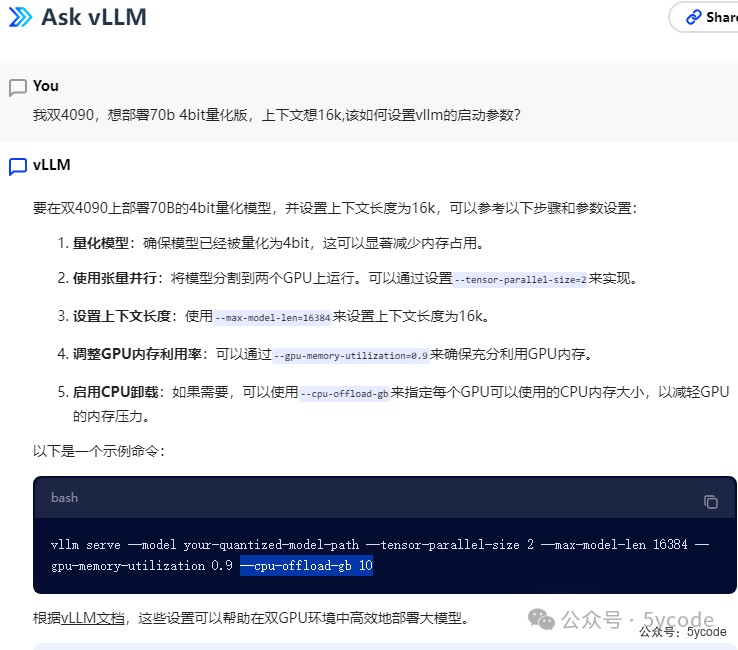 官方的api给我了一个配置参数,用上。
官方的api给我了一个配置参数,用上。
CUDA_VISIBLE_DEVICES=0,1 python benchmark_throughput.py \
--model "/opt/models/deepseek-70b-awq" \
--backend vllm \
--input-len 4096 \
--output-len 10000 \
--num-prompts 50 \
--seed 1100 \
--dtype float16 \
--tensor-parallel-size 2 \
--gpu-memory-utilization 0.95 \
--max-model-len 16384 \
--cpu-offload-gb 10
--enforce-eager
 好不容易看到点希望,又挂了。继续调整脚本。
好不容易看到点希望,又挂了。继续调整脚本。
CUDA_VISIBLE_DEVICES=0,1 python benchmark_throughput.py \
--model "/opt/models/deepseek-70b-awq" \
--backend vllm \
--input-len 4096 \
--output-len 10000 \
--num-prompts 50 \
--seed 1100 \
--dtype float16 \
--tensor-parallel-size 2 \
--gpu-memory-utilization 0.95 \
--max-model-len 16384 \
--cpu-offload-gb 10 \
--enforce-eager
 这次终于起来了,这速度。。。
这次终于起来了,这速度。。。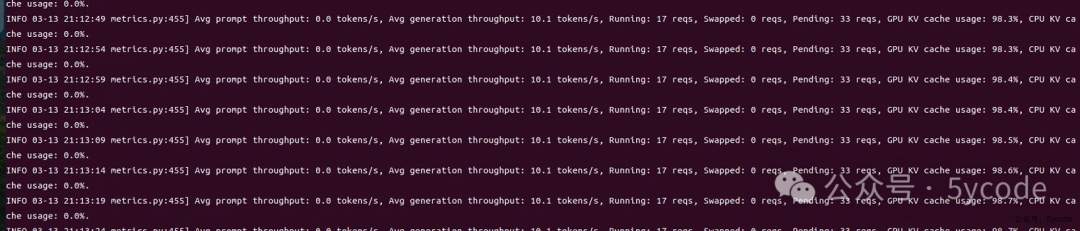 这cpu也没有利用起来。
这cpu也没有利用起来。
后记
使用vllm还是老老实实的使用显存吧,使用cpu,这速度真的没法忍受。也可能是我的能力有限。有哪位高手看到了,可以指教下。
善于利用官方的ai工具真能省不少力气,感觉浪费了好几个小时。
生产环境看自己的要求,尽量减少上下文长度,十几个并发,重度使用,也就20来个人可用,轻度使用,几十个人。它不像普通程序,很快就返回,每次执行都是好多秒。
通过官方的基准测试,不断地调整参数,找到适合自己的配置,没有绝对。
相关软件都放到了网盘里。有需要的可以自己下载。想加群的小伙伴,直接加我微信,yxkong。我拉你们进群。
相关资料
清华DeepSeek相关资料
https://pan.quark.cn/s/5c1e8f268e02https://pan.baidu.com/s/13zOEcm1lRk-ZZXukrDgvDw?pwd=22ce
北京大学DeepSeek相关资料
https://pan.quark.cn/s/918266bd423ahttps://pan.baidu.com/s/1IjddCW5gsKLAVRtcXEkVIQ?pwd=ech7
零基础使用DeepSeek
https://pan.quark.cn/s/17e07b1d7fd0
https://pan.baidu.com/s/1KitxQy9VdAGfwYI28TrX8A?pwd=vg6g
ollama的docker镜像
https://pan.baidu.com/s/13JhJAwaZlvssCXgPaV_n_A?pwd=gpfq
deepseek和qwq模型(ollama上pull下来的)
https://pan.quark.cn/s/dd3d2d5aefb2
https://pan.baidu.com/s/1FacMQSh9p1wIcKUDBEfjlw?pwd=ks7c
dify相关镜像
https://pan.baidu.com/s/1oa27LL-1B9d1qMnBl8_edg?pwd=1ish
ragflow相关资料和模型
https://pan.baidu.com/s/1bA9ZyQG75ZnBkCCenSEzcA?pwd=u5ei
公众号案例
https://pan.quark.cn/s/18fdf0b1ef2ehttps://pan.baidu.com/s/1aCSwXYpUhVdV2mfgZfdOvA?pwd=6xc2
总入口(有时候会被屏蔽):
https://pan.quark.cn/s/05f22bd57f47提取码:HiyL
https://pan.baidu.com/s/1GK0_euyn2LtGVmcGfwQuFg?pwd=nkq7
系列文档:
DeepSeek本地部署相关
DeepSeek相关资料
清华出品!《DeepSeek从入门到精通》免费下载,AI时代进阶必看!
清华出品!《DeepSeek赋能职场应用》轻松搞定PPT、海报、文案
DeepSeek个人应用
不要浪费deepseek的算力了,DeepSeek提示词库指南
deepseek一键生成小红书爆款内容,排版下载全自动!睡后收入不是梦
知识库Dify和cherry无法解析影印pdf word解决方案
dify相关
DeepSeek+dify 本地知识库:高级应用Agent+工作流
DeepSeek+dify知识库,查询数据库的两种方式(api+直连)
DeepSeek+dify 工作流应用,自然语言查询数据库信息并展示
知识库Dify和cherry无法解析影印pdf word解决方案
ragflow相关
DeepSeek+ragflow构建企业知识库:突然觉的dify不香了(1)
DeepSeek+ragflow构建企业知识库之工作流,突然觉的dify又香了
DeepSeek+ragflow构建企业知识库:高级应用篇,越折腾越觉得ragflow好玩
模型微调相关
推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://hqyman.cn/post/9745.html 非本站原创文章欢迎转载,原创文章需保留本站地址!

 微信支付宝扫一扫,打赏作者吧~
微信支付宝扫一扫,打赏作者吧~休息一下~~