
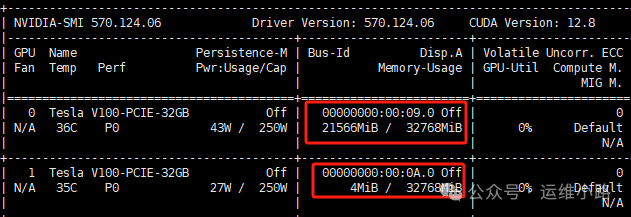
vi /etc/systemd/system/ollama.service #增加下面2个参数 Environment="CUDA_VISIBLE_DEVICES=0,1,2,3" Environment="OLLAMA_SCHED_SPREAD=1" #重新加载ollama systemctl daemon-reload systemctl restart ollama #然后重启模型 ollama run deepseek-r1:32b
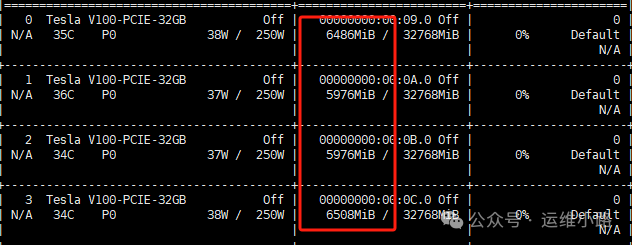
#日志里面大概会有类似的日志 "new model will fit in available VRAM, loading" model=/usr/share/ollama/.ollama/models/blobs/sha256-4cd576d9aa16961244012223abf01445567b061f1814b57dfef699e4cf8df339 library=cuda parallel=4 required="49.9 GiB"
#设置-1则永不退出,也可以设置其他具体时间,比如1h。 #再参考刚才 重启服务即可常驻 Environment="OLLAMA_KEEP_ALIVE=-1"
root@localhost:~# ollama ls NAME ID SIZE MODIFIED deepseek-r1:32b 38056bbcbb2d 19 GB 3 hours ago deepseek-r1:32b-qwen-distill-fp16 141ef25faf00 65 GB 19 hours ago deepseek-r1:70b 0c1615a8ca32 42 GB 20 hours ago
推荐本站淘宝优惠价购买喜欢的宝贝:

本文链接:https://hqyman.cn/post/9748.html 非本站原创文章欢迎转载,原创文章需保留本站地址!

 微信支付宝扫一扫,打赏作者吧~
微信支付宝扫一扫,打赏作者吧~休息一下~~